AUC ROC PR曲线
ROC曲线:
横轴:假阳性率 代表将负例错分为正例的概率
纵轴:真阳性率 代表能将正例分对的概率
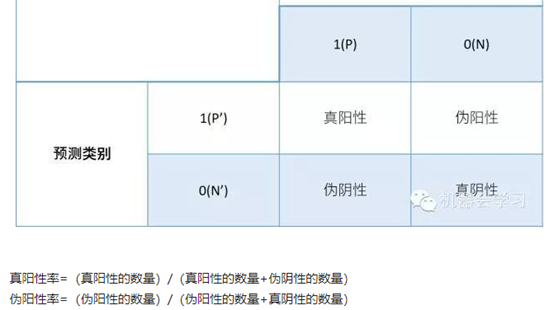
AUC是ROC曲线下面区域得面积。
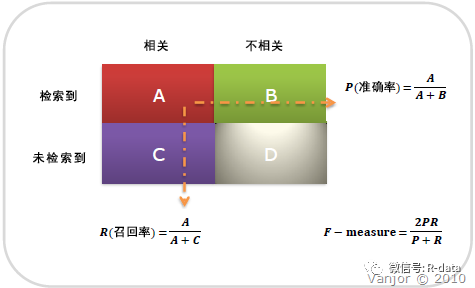
与召回率对比:
AUC意义:
任取一对(正、负)样本,把正样本预测为1的概率大于把负样本预测为1的概率的概率。基于上述,AUC反映的是分类器对样本的排序能力,如果进行随机预测,那么AUC的值应该为0.5.另外AUC对样本类别是否均衡并不敏感,所以不均衡样本通常使用AUC作为评价分类器的标准。
首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
AUC面积的数值不会大于1。ROC曲线一般都处于y=x这条直线的上方-->AUC的取值范围在0.5和1之间
使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
0,1 都靠中心斜线,主要看中间段,中间段正样本排前面的越多,属于正样本的概率值大且这个大概率符合实际情况(真阳性),序列前面大部分都是正样本而模型预测的偏向将它们预测为正样本,负样本排后面,这样曲线就会往左上靠拢,模型的效果就越好
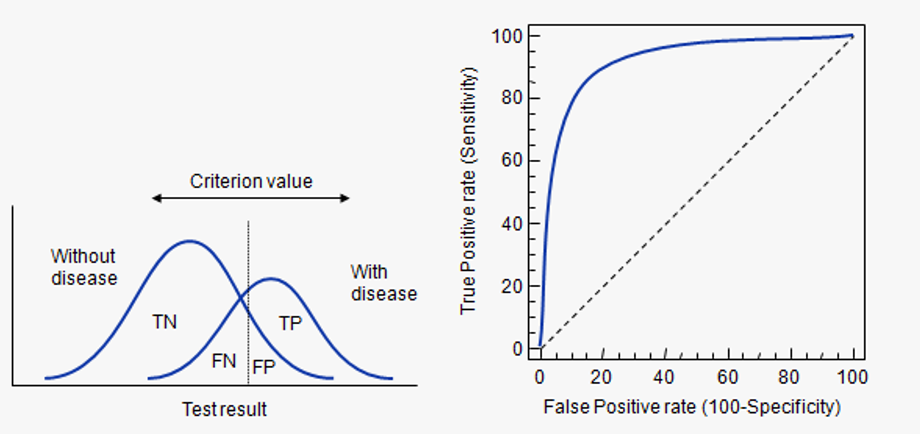
AUC画图例子
假如我们已经得到了所有样本的概率输出(属于正样本的概率),现在的问题是如何改变“discrimination threashold”?我们根据每个测试样本属于正样本的概率值从大到小排序。下图是一个示例,图中共有20个测试样本,“Class”一栏表示每个测试样本真正的标签(p表示正样本,n表示负样本),“Score”表示每个测试样本属于正样本的概率。

接下来,我们从高到低,依次将“Score”值作为阈值threshold,当测试样本属于正样本的概率大于或等于这个threshold时,我们认为它为正样本,否则为负样本。举例来说,对于图中的第4个样本,其“Score”值为0.6,那么样本1,2,3,4都被认为是正样本,因为它们的“Score”值都大于等于0.6,而其他样本则都认为是负样本。每次选取一个不同的threshold,我们就可以得到一组FPR和TPR,即ROC曲线上的一点。这样一来,我们一共得到了20组FPR和TPR的值,将它们画在ROC曲线的结果如下图:
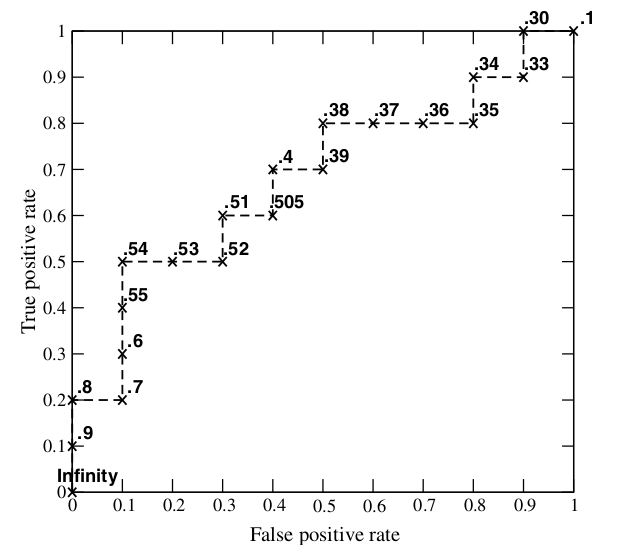
当我们将threshold设置为1和0时,分别可以得到ROC曲线上的(0,0)和(1,1)两个点。将这些(FPR,TPR)对连接起来,就得到了ROC曲线。当threshold取值越多,ROC曲线越平滑。
为什么要使用ROC和AUC呢?
ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。
AUC对样本类别是否均衡并不敏感,所以不均衡样本通常使用AUC作为评价分类器的标准。
http://alexkong.net/2013/06/introduction-to-auc-and-roc/
PR曲线
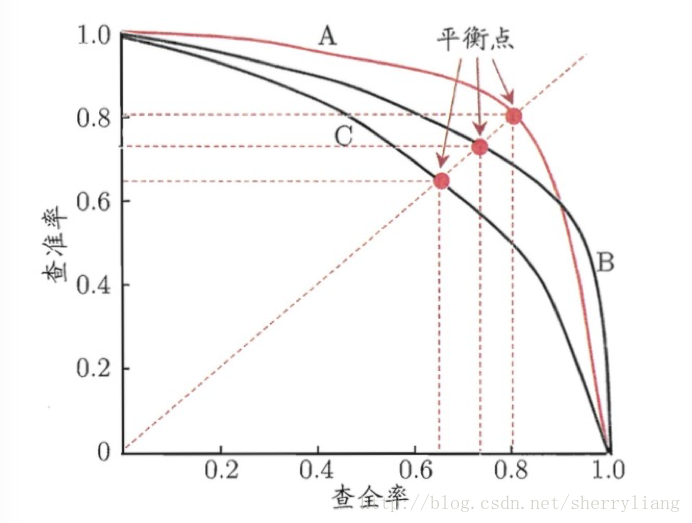
P-R图直观地显示出学习器在样本总体上的查全率和查准率。在进行比较时,若一个学习器的P-R曲线完全被另一个学习器的曲线完全“包住”,则我们就可以断言后者的性能优于前者。
准确率(accuracy),其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。不适合不平衡数据
Precision 和Recall
在linear model中,我们对各个特征线性组合,得到linear score,然后确定一个threshold,linear score < threshold 判为负类,linear score > threshold 判为正类。画PR曲线时, 我们可以想象threshold 是不断变化的。首先,threshold 特别大,这样木有一个是正类,我们计算出查全率与查准率; 然后 threshold 减小, 只有一个正类,我们计算出查全率与查准率;然后 threshold再减小,有2个正类,我们计算出查全率与查准率;threshold减小一次,多出一个正类,直到所有的类别都被判为正类。 然后以查全率为横坐标,差准率为纵坐标,画出图形即可。
例如,有
| 实际类别 | linear score | threshold 为6 | threshold 为5 | threshold 为4 | threshold 为3 | threshold 为2 | threshold 为1 | |
| + | 5.2 | - | + | + | + | + | + | |
| + | 4.45 | - | - | + | + | + | + | |
| - | 3.5 | - | - | - | + | + | + | |
| - | 2.45 | - | - | - | - | + | + | |
| - | 1.65 | - | - | - | - | - | + | |
| 0/0 | 1 / 1 | 2 / 2 | 2 / 3 | 2 / 4 | 2 / 5 | 查准率 | ||
| 0/2 | 1 / 2 | 2 / 2 | 2/ 2 | 2 / 2 | 2/ 2 | 差全率 | ||
| 0/2 | 1/2 | 2/2 | 2/2 | 2/2 | 2/2 | TPR | ||
| 0/3 | 0/3 | 1/3 | 2/3 | 3/3 | FPR |
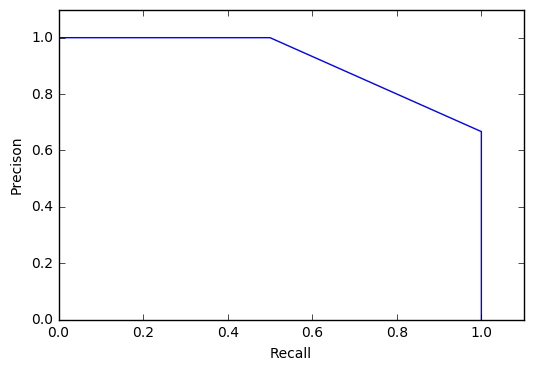
绘制pr曲线代码
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
Recall = np.array([0,1/2,2/2,2/2,2/2,2/2])
Precison = np.array([1/1,2/2,2/3,2/4,2/5,0])
plt.figure()
plt.ylim(0,1.1)
plt.xlabel("Recall")
plt.xlim(0,1.1)
plt.ylabel("Precison")
plt.plot(Recall,Precison)
plt.show()
ROC和PR曲线的选择
如果负样本对于问题没有多大价值,或者负样本比例很大。 那么,PR曲线通常更合适。
比如样本正负比例非常不平衡,且正样本非常少,那我们使用PR曲线。 举个例子:欺诈检测,其中非欺诈样本可能为10000,而欺诈样本可能低于100。
否则ROC会更有用
AUC ROC PR曲线的更多相关文章
- PR曲线,ROC曲线,AUC指标等,Accuracy vs Precision
作为机器学习重要的评价指标,标题中的三个内容,在下面读书笔记里面都有讲: http://www.cnblogs.com/charlesblc/p/6188562.html 但是讲的不细,不太懂.今天又 ...
- Mean Average Precision(mAP),Precision,Recall,Accuracy,F1_score,PR曲线、ROC曲线,AUC值,决定系数R^2 的含义与计算
背景 之前在研究Object Detection的时候,只是知道Precision这个指标,但是mAP(mean Average Precision)具体是如何计算的,暂时还不知道.最近做OD的任 ...
- 查全率(Recall),查准率(Precision),灵敏性(Sensitivity),特异性(Specificity),F1,PR曲线,ROC,AUC的应用场景
之前介绍了这么多分类模型的性能评价指标(<分类模型的性能评价指标(Classification Model Performance Evaluation Metric)>),那么到底应该选 ...
- 精确率与召回率,RoC曲线与PR曲线
在机器学习的算法评估中,尤其是分类算法评估中,我们经常听到精确率(precision)与召回率(recall),RoC曲线与PR曲线这些概念,那这些概念到底有什么用处呢? 首先,我们需要搞清楚几个拗口 ...
- ROC曲线和PR曲线
转自:http://www.zhizhihu.com/html/y2012/4076.html分类.检索中的评价指标很多,Precision.Recall.Accuracy.F1.ROC.PR Cur ...
- 【ROC曲线】关于ROC曲线、PR曲线对于不平衡样本的不敏感性分析说引发的思考
ROC曲线 在网上有很多地方都有说ROC曲线对于正负样本比例不敏感,即正负样本比例的变化不会改变ROC曲线.但是对于PR曲线就不一样了.PR曲线会随着正负样本比例的变化而变化.但是没有一个有十分具体和 ...
- 机器学习之类别不平衡问题 (2) —— ROC和PR曲线
机器学习之类别不平衡问题 (1) -- 各种评估指标 机器学习之类别不平衡问题 (2) -- ROC和PR曲线 完整代码 ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题 ...
- ROC,AUC,PR,AP介绍及python绘制
这里介绍一下如题所述的四个概念以及相应的使用python绘制曲线: 参考博客:http://kubicode.me/2016/09/19/Machine%20Learning/AUC-Calculat ...
- ROC曲线和PR曲线绘制【转】
TPR=TP/P :真正率:判断对的正样本占所有正样本的比例. Precision=TP/(TP+FP) :判断对的正样本占判断出来的所有正样本的比例 FPR=FP/N :负正率:判断错的负样本占所 ...
随机推荐
- [转载]Java给word中的table赋值
一.准备工作: 下载PageOffice for Java:http://www.zhuozhengsoft.com/dowm/ 二. 实现方法: 要调用PageOffice操作Word中的tabl ...
- LeetCode OJ:Remove Duplicates from Sorted List (排好序的链表去重)
Given a sorted linked list, delete all duplicates such that each element appear only once. For examp ...
- 闸流管(或双向可控硅) IGBT 应用
十条规则规则1. 为了导通闸流管(或双向可控硅),必须有门极电流≧IGT ,直至负载电流达到≧IL .这条件必须满足,并按可能遇到的最低温度考虑.规则2. 要断开(切换)闸流管(或双向可控硅),负载电 ...
- canvas 绘制坐标轴
结果: 代码: <!DOCTYPE html> <html> <head lang="en"> <meta charset="U ...
- 一个高性能RPC框架的连接管理
既然说连接,先对EpollServer的连接管理做个介绍吧.客户端与服务器一次conn,被封装成为Connection类在服务器进行管理. 服务器连接有三种类型,分别为: enum EnumConne ...
- Django 之Ajax
必备知识:json 什么是json 定义 JSON(JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式. 它基于 ECMAScript (w3c制定的 ...
- python web开发配置
安装python(最好是2.*版本) 安装easyinstall 参考Windows 下 Python easy_install 的安装 完成之后注意环境变量的配置 在系统环境变量的PATH中添加ea ...
- python学习之面向对象(下)
该篇主要是针对面向对象的细讲,包括类的多重继承,方法的重写,析构函数,回收机制进行讲解 #该类主要是讲述python面象对象的一些特征,包括继承,方法的重写,多态,垃圾回收 class person( ...
- 高级C/C++编译技术之读书笔记(五)之动态库版本控制
最近有幸阅读了<高级C/C++编译技术>深受启发,该书深入浅出地讲解了构建过程(编译.链接)中的各种细节,从多个角度展示了程序与库文件或代码的集成方法,提出了面向代码复用和系统集成的软件架 ...
- VSCode高效开发插件
VSCode 必装的 10 个高效开发插件 https://www.cnblogs.com/parry/p/vscode_top_ten_plugins.html 本文介绍了目前前端开发最受欢迎的开发 ...