Filebeat 5.x 日志收集器 安装和配置
Filebeat 5.x版本
风来了.fox
1.下载和安装
https://www.elastic.co/downloads/beats/filebeat这里选择 LINUX 64-BIT 即方式一
https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-5.6.3-linux-x86_64.tar.gz
tar -zxvf filebeat-5.6.3-linux-x86_64.tar.gz2.配置Filebeat
环境说明:
1)elasticsearch和logstash 在不同/相同的服务器上,只发送数据给logstash/elasticsearch
2)监控nginx日志
3)监控站点日志
2.1配置
编辑filebeat.yml
vim filebeat.yml修改为
filebeat.prospectors:
- input_type: log
paths:
- /www/wwwLog/www.foxwho.com/*.log
input_type: log
document_type: nginx-www.foxwho.com
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
- input_type: log
paths:
- /www/wwwroot/www.foxwho.com/runtime/log/*/[0-9]*[_\w]?*.log
input_type: log
document_type: web-www.foxwho.com
multiline.pattern: '^\['
multiline.negate: true
multiline.match: after
#output.elasticsearch:
# hosts: ["localhost:9200"]
# index: "filebeat-www.babymarkt.cn"
# template.name: "filebeat"
# template.path: "filebeat.template.json"
# template.overwrite: false
output.logstash:
hosts: ["10.1.5.65:5044"]
...其他部分没有改动,不需要修改2.2 说明
- paths:指定要监控的日志,目前按照Go语言的glob函数处理。没有对配置目录做递归处理,比如配置的如果是:
/var/log/* /*.log则只会去/var/log目录的所有子目录中寻找以”.log”结尾的文件,而不会寻找/var/log目录下以”.log”结尾的文件。
2. input_type:指定文件的输入类型log(默认)或者stdin。
3. document_type:设定Elasticsearch输出时的document的type字段,也可以用来给日志进行分类。
把 elasticsearch和其下的所有都注释掉(这里Filebeat是新安装的,只注释这2处即可)
#output.elasticsearch:
# hosts: ["localhost:9200"]开启 logstash(删除这两行前的#号),并把localhost改为logstash服务器地址
output.logstash:
hosts: ["10.1.5.65:5044"]如果开启logstash了,那么Logstash配置中要设置监听端口 5044:
这个是默认文件位置,如果不存在请自行查找
建立beats-input.conf配置文件
vim /etc/logstash/etc/beats-input.conf增加端口
input {
beats {
port => 5044
}
}3.启动
3.1 测试
./filebeat -e -c filebeat.yml -d "Publish"如果能看到一堆东西输出,表示正在向elasticsearch或logstash发送日志。
如果是elasticsearch可以浏览:http://localhost:9200/_search?pretty 如果有新内容返回,表示ok
测试正常后,Ctrl+C结束
3.2启动
nohup ./filebeat -e -c filebeat.yml &上面会转入后台运行
3.3停止
查找进程 ID
ps -ef |grep filebeatKILL他
kill -9 id3.X kibana设置
如果使用 kibana 做日志分析,
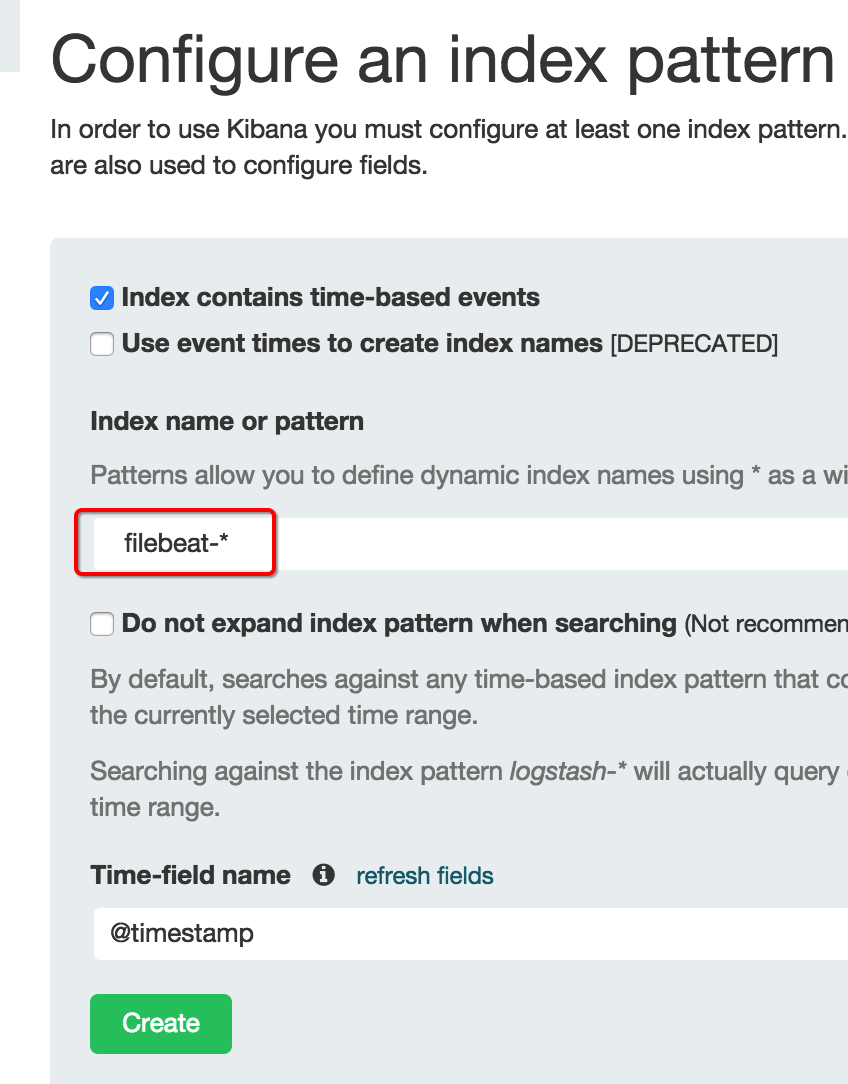
在kibana里,创建一个索引,注意pattern为:filebeat-*
4.高级配置说明
http://kibana.logstash.es/content/beats/file.html
http://blog.csdn.net/a464057216/article/details/51233375
5.其他说明
5.1Elasticsearch知道如何处理每个日志事件
默认的Elasticsearch需要的index template在安装Filebeat的时候已经提供,路径为/etc/filebeat/filebeat.template.json,可以使用如下命令装载该模板:
在 filebeat 安装目录中运行
curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@filebeat.template.json如果运行成功则返回如下,表示模板已被接收
{
"acknowledged" : true
}每次修改Filebeat配置,重启Filebeat才能生效
部分来源:
http://blog.csdn.net/a464057216/article/details/50987695
http://www.cnblogs.com/yjmyzz/p/filebeat-turorial-and-kibana-login-setting-with-nginx.html
Filebeat 5.x 日志收集器 安装和配置的更多相关文章
- Filebeat 日志收集器 安装和配置
Filebeat的配置文件是/etc/filebeat/filebeat.yml,遵循YAML语法.具体可以配置如下几个项目: Filebeat Output Shipper Logging(可选) ...
- 日志分析平台ELK之日志收集器filebeat
前面我们了解了elk集群中的logstash的用法,使用logstash处理日志挺好的,但是有一个缺陷,就是太慢了:当然logstash慢的原因是它依赖jruby虚拟机,jruby虚拟机就是用java ...
- 日志分析平台ELK之日志收集器logstash
前文我们聊解了什么是elk,elk中的elasticsearch集群相关组件和集群搭建以及es集群常用接口的说明和使用,回顾请查看考https://www.cnblogs.com/qiuhom-187 ...
- rsyslog日志收集器
rsyslog详解(思维导图) 1. 日志收集概述 1.1 日志记录 时间 事件 1.2 日志收集器 syslog rsyslog elk stack 1.3 日志文件 文件记录的日志格式 其他日志文 ...
- 【Qt开发】Qt Creator在Windows上的调试器安装与配置
Qt Creator在Windows上的调试器安装与配置 如果安装Qt时使用的是Visual Studio的预编译版,那么很有可能就会缺少调试器(Debugger),而使用MSVC的Qt对应的原生调试 ...
- 【RSYSLOG】rsyslog作为日志采集器安装配置说明
RSYSLOG is the rocket-fast system for log processing. About 由于环境基于CentOS 6.7 x64,rsyslog本身就是OS的组件,由于 ...
- 日志分析平台ELK之日志收集器logstash常用插件配置
前文我们了解了logstash的工作流程以及基本的收集日志相关配置,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13761906.html:今天我们来了解下l ...
- Kafka+Zookeeper+Filebeat+ELK 搭建日志收集系统
ELK ELK目前主流的一种日志系统,过多的就不多介绍了 Filebeat收集日志,将收集的日志输出到kafka,避免网络问题丢失信息 kafka接收到日志消息后直接消费到Logstash Logst ...
- docker容器日志收集方案(方案二 filebeat+syslog本地日志收集)
与方案一一样都是把日志输出到本地文件系统使用filebeat进行扫描采集 不同的是输出的位置是不一样的 我们对docker进行如下设置 sudo docker service update --lo ...
随机推荐
- java验证类ValidUtils
ValidUtils.java package com.lyqc.utils; import org.apache.commons.lang.StringUtils; public class Val ...
- 斯坦福机器学习视频笔记 Week8 无监督学习:聚类与数据降维 Clusting & Dimensionality Reduction
监督学习算法需要标记的样本(x,y),但是无监督学习算法只需要input(x). 您将了解聚类 - 用于市场分割,文本摘要,以及许多其他应用程序. Principal Components Analy ...
- Android SDK组件:webview笔记
1.安卓手机中内置了一款webkit内核的浏览器,在SDK中封装为WebView组件. 2.该组件可以在自己的应用程序中显示本地或者Internet上的网页,也可以把它当作一个浏览器来时用. 3.We ...
- C# 处理base64 以及base64的原理分析
base64的原理, http://www.cnblogs.com/diligenceday/p/6002382.html http://www.cnblogs.com/chengxiaohui/ar ...
- 未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0” 提供程序
我在Web App程序里面用“Microsoft.Jet.OLEDB.4.0”来连接Excel文件,导入到数据库,在Windows 2003+ Office 2007 的环境下正常,但是在Window ...
- BZOJ3669 [Noi2014]魔法森林(SPFA+动态加边)
本文版权归ljh2000和博客园共有,欢迎转载,但须保留此声明,并给出原文链接,谢谢合作. 本文作者:ljh2000 作者博客:http://www.cnblogs.com/ljh2000-jump/ ...
- 使用Jenkins进行持续集成
首先,我们从Jenkins官方网站https://jenkins.io/下载最新的war包.虽然Jenkins提供了Windows.Linux.OS X等各种安装程序,但是,这些安装程序都没有war包 ...
- python定制
1.简单定制 a.使用time模块的localtime方法获取时间 b.time.localtime返回struct_time的时间格式 c.表现你的类:__str__和__repr__ 注:当属 ...
- review07
java类可以有两种重要的成员:成员变量和方法,实际上java还允许有一种成员:内部类.内部类是在一个类中定义另一个类.内部类和外嵌类的关系如下: (1)内部类的外嵌类的成员变量在内部类中仍然有效,内 ...
- weinre远程调试
一: 关于weinre weinre是一款依赖于nodejs的远程调试工具,现阶段一般用到手机app上调试非常的强大 二: weinre的安装 1) 安装 nodejs以及npm 2) 安装wein ...