【云计算】mesos+marathon 服务发现、负载均衡、监控告警方案
Mesos-dns 和 Marathon-lb 是mesosphere 官网提供的两种服务发现和负载均衡工具。官方的文档主要针对DCOS,针对其它系统的相关中文文档不多,下面是我在Centos7上的安装说明和使用总结。
1. Mesos服务发现与负载均衡
默认情况下,mesos marathon会把app发布到随机节点的随机端口上,当mesos slaves和app越来越多的时候,想查找某组app就变得困难。
mesos提供了两个工具:mesos-dns和marathon-lb。mesos-dns是一个服务发现工具,marathon-lb不仅是服务发现工具,还是负载均衡工具。
2. mesos-dns
Mesos-dns是 mesos 服务发现工具,能查找app的Ip,端口号以及master,leader等信息。
2.1 安装
从下述地址下载mesos-dns二进制文件:
https://github.com/mesosphere/mesos-dns/releases
重命名为mesos-dns
chmod +x mesos-dns
按照官方文档编写config.json,填入zk、master等相关信息
2.2 启动
2.2.1 命令行方式
mesos-dns -config config.json
2.2.2 也可以用marathon部署
#mesos-dns.json
{
"id": "mesos-dns",
"cpus": 0.5,
"mem": 128.0,
"instances": 3,
"constraints": [["hostname", "UNIQUE"]],
"cmd": "/opt/mesos-dns/mesos-dns -config /opt/mesos-dns/config.json"
}
#向marathon发送部署内容
curl -i -H 'Content-Type: application/json' 172.31.17.71:8080/v2/apps -d@mesos-dns.json
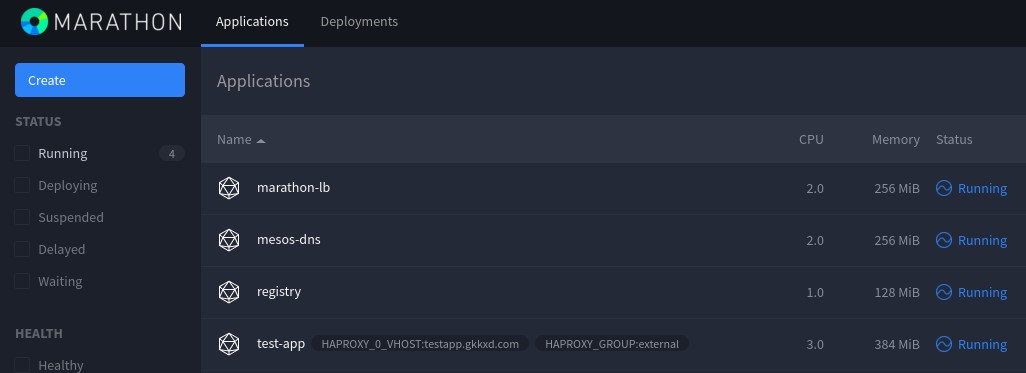
图中的mesos-dns是通过marathon部署的mesos-dns,共两个实例。
2.3 使用方法
注:slave4是安装了mesos-dns的主机名
2.3.1 查找app的ip
dig test-app.marathon.mesos +short @slave4
172.17.0.2
2.3.2 查找app所在节点的IP
dig test-app.marathon.slave.mesos +short @slave4
172.31.17.33
172.31.17.31
172.31.17.32
2.3.3 查找app服务端口号
dig SRV _test-app._tcp.marathon.mesos +short @slave4
0 0 31234 test-app-s3ehn-s11.marathon.slave.mesos.
0 0 31846 test-app-zfp5d-s10.marathon.slave.mesos.
0 0 31114 test-app-3xynw-s12.marathon.slave.mesos.
3. marathon-lb
Marathon-lb既是一个服务发现工具,也是负载均衡工具,它集成了haproxy,自动获取各个app的信息,为每一组app生成haproxy配置,通过servicePort或者web虚拟主机提供服务。
要使用marathonn-lb,每组app必须设置HAPROXY_GROUP标签。
Marathon-lb运行时绑定在各组app定义的服务端口(servicePort,如果app不定义servicePort,marathon会随机分配端口号)上,可以通过marathon-lb所在节点的相关服务端口访问各组app。
例如:marathon-lb部署在slave5,test-app 部署在slave1,test-app 的servicePort是10004,那么可以在slave5的 10004端口访问到test-app提供的服务。
由于servicePort 非80、443端口(80、443端口已被marathon-lb中的 haproxy独占),对于web服务来说不太方便,可以使用 haproxy虚拟主机解决这个问题:
在提供web服务的app配置里增加HAPROXY_{n}_VHOST(WEB虚拟主机)标签,marathon-lb会自动把这组app的WEB集群服务发布在marathon-lb所在节点的80和443端口上,用户设置DNS后通过虚拟主机名来访问。
3.1 安装
#下载marathon-lb镜像
docker pull docker.io/mesosphere/marathon-lb
可以通过docker run运行,也可以通过marathon部署到mesos集群里。
3.2 运行
3.2.1 命令行运行
docker run -d --privileged -e PORTS=9090 --net=host docker.io/mesosphere/marathon-lb sse -m http://master1_ip:8080 -m http://master2_ip:8080 -m http://master3_ip:8080 --group external
3.2.2 通过marathon部署
{
"id": "marathon-lb",
"instances": 3,
"constraints": [["hostname", "UNIQUE"]],
"container": {
"type": "DOCKER",
"docker": {
"image": "docker.io/mesosphere/marathon-lb",
"privileged": true,
"network": "HOST"
}
},
"args": ["sse", "-m","http://master1_ip:8080", "-m","http://master2_ip:8080", "-m","http://master3_ip:8080","--group", "external"]
}
curl -i -H 'Content-Type: application/json' 172.31.17.71:8080/v2/apps -d@marathon-lb.json
3.3 使用方法
下面使用marathon-lb对http服务进行服务发现和负载均衡:
3.3.1 发布app
# 先创建app的json配置信息
一定要加上HAPROXY_GROUP标签,对于web服务,可以加上VHOST标签,让marathon-lb设置WEB虚拟主机;
对于web服务,servicePort设置为0即可,marathon-lb会自动把web服务集群发布到80、443上;
{
"id": "test-app",
"labels": {
"HAPROXY_GROUP":"external",
"HAPROXY_0_VHOST":"test-app.XXXXX.com"
},
"cpus": 0.5,
"mem": 64.0,
"instances": 3,
"constraints": [["hostname", "UNIQUE"]],
"container": {
"type": "DOCKER",
"docker": {
"image": "httpd",
"privileged": false,
"network": "BRIDGE",
"portMappings": [
{ "containerPort": 80, "hostPort": 0, "servicePort": 0, "protocol": "tcp"}
]
}
}
}
#发布app
curl -i -H 'Content-Type: application/json' 172.31.17.71:8080/v2/apps -d@test-app.json
3.3.2 访问app
先设置DNS或者hosts文件:
172.31.17.34 test-app.XXXXX.com
用浏览器通过http和https访问虚拟主机,发现服务已经启动,实际上是marathon-lb内置的haproxy对test-app的三个实例配置的web服务集群:
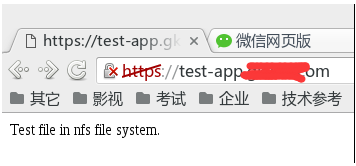
对于marathon-lb,可以同时部署多台,然后用DNS轮询或者keepalived虚拟IP实现高可用。
前几天我在mesos平台上基于 cadvisor部署了 influxdb 和 grafana,用于监控 mesos 以及 docker app 运行信息,发现这套监控系统不太适合 mesos + docker 的架构,原因是:
1)mesos task id 和 docker container name 不一致
cadvisor 的设计基于 docker host,没有考虑到mesos 数据中心;
cadvisor 用 docker name(docker ps能看到)来标记抓取的数据,而 mesos 用 task id(在mesos ui 或者metrics里能看到) 来标记正在运行的任务。mesos task 的类型可以是 docker 容器,也可以是非容器。mesos task id 与docker container name 的命名也是完全不一样的。
上述问题导致 cadvisor 抓取到数据后,用户难以识别属于哪个 mesos task
2)cadvisor 和 grafana 不支持报警
经过查询资料,发现 mesos-exporter + prometheus + alert-manager 是个很好的组合,可以解决上述问题:
mesos-exporter 是 mesosphere 开发的工具,用于导出 mesos 集群包括 task 的监控数据并传递给prometheus;prometheus是个集 db、graph、statistic 于一体的监控工具;alert-manager 是 prometheus 的报警工具
搭建方法:
1. build mesos-exporter
|
1
2
3
|
git clone https://github.com/mesosphere/mesos_exporter.gitcd mesos_exporterdocker build -f Dockerfile -t mesosphere/mesos-exporter . |
2. docker pull prometheus, alert-manager
3. 部署 mesos-exporter, alert-manager, prometheus
mesos-exporter:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
{ "id": "mesos-exporter-slave", "instances": 6, "cpus": 0.2, "mem": 128, "args": [ "-slave=http://127.0.0.1:5051", "-timeout=5s" ], "constraints": [ ["hostname","UNIQUE"], ["hostname", "LIKE", "slave[1-6]"] ], "container": { "type": "DOCKER", "docker": { "image": "172.31.17.36:5000/mesos-exporter:latest", "network": "HOST" }, "volumes": [ { "containerPath": "/etc/localtime", "hostPath": "/etc/localtime", "mode": "RO" } ] }} |
请打开slave 防火墙的9110/tcp 端口
alert-manager:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
{ "id": "alertmanager", "instances": 1, "cpus": 0.5, "mem": 128, "constraints": [ ["hostname","UNIQUE"], ["hostname", "LIKE", "slave[1-6]"] ], "labels": { "HAPROXY_GROUP":"external", "HAPROXY_0_VHOST":"alertmanager.XXXXX.com" }, "container": { "type": "DOCKER", "docker": { "image": "172.31.17.36:5000/alertmanager:latest", "network": "BRIDGE", "portMappings": [ { "containerPort": 9093, "hostPort": 0, "servicePort": 0, "protocol": "tcp" } ] }, "volumes": [ { "containerPath": "/etc/localtime", "hostPath": "/etc/localtime", "mode": "RO" }, { "containerPath": "/etc/alertmanager/config.yml", "hostPath": "/var/nfsshare/alertmanager/config.yml", "mode": "RO" }, { "containerPath": "/alertmanager", "hostPath": "/var/nfsshare/alertmanager/data", "mode": "RW" } ] }} |
prometheus:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
{ "id": "prometheus", "instances": 1, "cpus": 0.5, "mem": 128, "args": [ "-config.file=/etc/prometheus/prometheus.yml", "-storage.local.path=/prometheus", "-web.console.libraries=/etc/prometheus/console_libraries", "-web.console.templates=/etc/prometheus/consoles", "-alertmanager.url=http://alertmanager.XXXXX.com" ], "constraints": [ ["hostname","UNIQUE"], ["hostname", "LIKE", "slave[1-6]"] ], "labels": { "HAPROXY_GROUP":"external", "HAPROXY_0_VHOST":"prometheus.XXXXX.com" }, "container": { "type": "DOCKER", "docker": { "image": "172.31.17.36:5000/prometheus:latest", "network": "BRIDGE", "portMappings": [ { "containerPort": 9090, "hostPort": 0, "servicePort": 0, "protocol": "tcp" } ] }, "volumes": [ { "containerPath": "/etc/localtime", "hostPath": "/etc/localtime", "mode": "RO" }, { "containerPath": "/etc/prometheus", "hostPath": "/var/nfsshare/prometheus/conf", "mode": "RO" }, { "containerPath": "/prometheus", "hostPath": "/var/nfsshare/prometheus/data", "mode": "RW" } ] }} |
4. prometheus 配置
prometheus.yml
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# my global configglobal: scrape_interval: 15s # By default, scrape targets every 15 seconds. evaluation_interval: 15s # By default, scrape targets every 15 seconds. # scrape_timeout is set to the global default (10s). # Attach these labels to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: monitor: 'codelab-monitor'# Load and evaluate rules in this file every 'evaluation_interval' seconds.rule_files: # - "first.rules" # - "second.rules"scrape_configs: - job_name: 'mesos-slaves' scrape_interval: 5s metrics_path: '/metrics' scheme: 'http' target_groups: - targets: ['172.31.17.31:9110', '172.31.17.32:9110', '172.31.17.33:9110', '172.31.17.34:9110', '172.31.17.35:9110', '172.31.17.36:9110'] - labels: group: 'office' |
待补充 ...
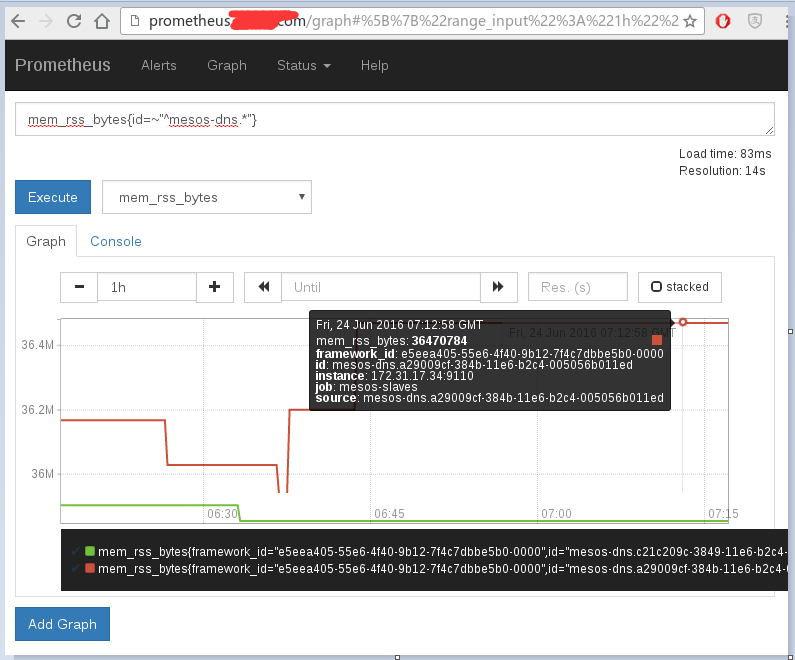
5. 报警设置
待补充 ...
6. 与 grafana 集成
prometheus的 graph 功能不太完善,可以与 grafana 集成,让 grafana 承担 graph 功能。
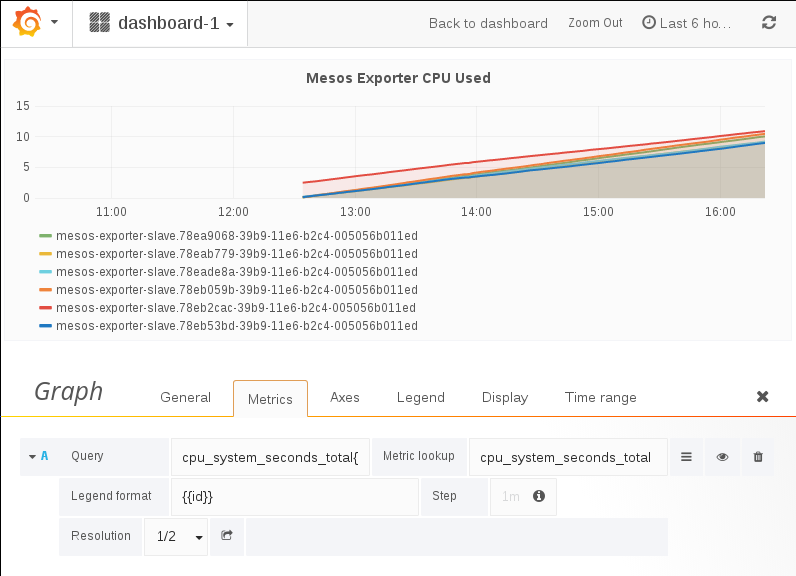
data source 设置:

7. 附:mesos metrics 和 statics 地址
http://master1:5050/metrics/snapshot
http://slave4:5051/metrics/snapshot
http://master1:5050/master/state.json
http://slave4:5051/monitor/statistics.json
用户可以基于上述页面的数据,编写自己的监控程序。
参考资料:
【云计算】mesos+marathon 服务发现、负载均衡、监控告警方案的更多相关文章
- .net core grpc consul 实现服务注册 服务发现 负载均衡(二)
在上一篇 .net core grpc 实现通信(一) 中,我们实现的grpc通信在.net core中的可行性,但要在微服务中真正使用,还缺少 服务注册,服务发现及负载均衡等,本篇我们将在 .net ...
- .Net Core Grpc Consul 实现服务注册 服务发现 负载均衡
本文是基于..net core grpc consul 实现服务注册 服务发现 负载均衡(二)的,很多内容是直接复制过来的,..net core grpc consul 实现服务注册 服务发现 负载均 ...
- .net core Ocelot Consul 实现API网关 服务注册 服务发现 负载均衡
大神张善友 分享过一篇 <.NET Core 在腾讯财付通的企业级应用开发实践>里面就是用.net core 和 Ocelot搭建的可扩展的高性能Api网关. Ocelot(http:// ...
- Nginx负载均衡+监控状态检测
Nginx负载均衡+监控状态检测 想用Nginx或者Tengine替代LVS,即能做七层的负载均衡,又能做监控状态检测,一旦发现后面的realserver挂了就自动剔除,恢复后自动加入服务池里,可以用 ...
- 关于Ocelot和Consul 实现GateWay(网关) 服务注册 负载均衡等方面
Ocelot 路由 请求聚合 服务发现 认证 鉴权 限流熔断 内置负载均衡器 Consul 自动服务发现 健康检查 通过Ocelot搭建API网关 服务注册 负载均衡 1. ...
- 搭建服务与负载均衡的客户端-Spring Cloud学习第二天(非原创)
文章大纲 一.Eureka中的核心概念二.Spring RestTemplate详解三.代码实战服务与负载均衡的客户端四.项目源码与参考资料下载五.参考文章 一.Eureka中的核心概念 1. 服务提 ...
- 一起来学Spring Cloud | 第三章:服务消费者 (负载均衡Ribbon)
一.负载均衡的简介: 负载均衡是高可用架构的一个关键组件,主要用来提高性能和可用性,通过负载均衡将流量分发到多个服务器,多服务器能够消除单个服务器的故障,减轻单个服务器的访问压力. 1.服务端负载均衡 ...
- 寻找丢失的微服务-HAProxy热加载问题的发现与分析 原创: 单既喜 一点大数据技术团队 4月8日 在一点资讯的容器计算平台中,我们通过HAProxy进行Marathon服务发现。本文记录HAProxy服务热加载后某微服务50%概率失效的问题。设计3组对比实验,验证了陈旧配置的HAProxy在Reload时没有退出进而导致微服务丢失,并给出了解决方案. Keywords:HAProxy热加
寻找丢失的微服务-HAProxy热加载问题的发现与分析 原创: 单既喜 一点大数据技术团队 4月8日 在一点资讯的容器计算平台中,我们通过HAProxy进行Marathon服务发现.本文记录HAPro ...
- 使用nginx 做kbmmw REST 服务的负载均衡
我们一般在云上部署REST服务.既想利用kbmmw 的方便性,又想保证系统的安全性,同时 想通过负载均衡保证服务器的健壮性.下面我们使用ubuntu+nginx 来实现以下kbmmw rest 服务器 ...
随机推荐
- 教你从头到尾利用DQN自动玩flappy bird(全程命令提示,GPU+CPU版)【转】
转自:http://blog.csdn.net/v_JULY_v/article/details/52810219?locationNum=3&fps=1 目录(?)[-] 教你从头到尾利用D ...
- 在oracle官网上,找到我们所需版本的jdk
oracle的官网,因为都是英文,而且内容还特别多,经常的找不到历史版本的JDK. 特地,将找历史版本JDK的方法记录下来. 访问:http://www.oracle.com/technetwork/ ...
- SSH的简单入门体验(Struts2.1+Spring3.1+Hibernate4.1)- 查询系统(上)
所谓SSH,指的是struts+spring+hibernate的一个集成框架,它是目前较流行的一种Web应用程序的开源框架. 集成SSH框架的系统从职责上分为四层:表示层.业务逻辑层.数据持久层和域 ...
- docker从零开始 存储(三)bind mounts
使用bind mounts 自Docker早期以来bind mounts 一直存在.与volumes相比,绑定挂载具有有限的功能.使用bind mounts时,主机上的文件或目录将装入容器中.文件或目 ...
- 手工安装kubernetes
参考的URL是 http://www.cnblogs.com/zhenyuyaodidiao/p/6500830.html 安装kubernets本身比较顺利,只是作dashboard时,老是日文版, ...
- c#实现Form窗体始终在桌面最前端显示
方法一 //调用API [System.Runtime.InteropServices.DllImport("user32", CharSet = System.Runtime.I ...
- 统计mysql库中每张表的行数据
修改数据库配置文件:vim /etc/my.cnf [client] user=username password=password 使用shell脚本统计表中的行数据:count.sh #!/bin ...
- C++的Public.lib(Public.dll) : fatal error LNK1112: module machine type 'X86' conflicts with target machine type 'x64'
今天开始编译网游服务器,找前辈借来批处理文件,版本控制上拿下代码,库等一系列资源,尼玛啊,编译出错: Public.lib(Public.dll) : fatal error LNK1112: mod ...
- bzoj3942
有一个S串和一个T串,长度均小于1,000,000,设当前串为U串,然后从前往后枚举S串一个字符一个字符往U串里添加,若U串后缀为T,则去掉这个后缀继续流程.将s中的每一个字符压入栈暴力将s中的字符和 ...
- Codeforces 856B - Similar Words
856B - Similar Words 题意 如果一个字符串可以通过去掉首位字母得到另一个字符串,则称两个字符串相似. 给出一个字符串集合,求一个新的字符串集合,满足新集合里的字符串是原字符串集合中 ...