如何通过 Docker 部署 Logstash 同步 Mysql 数据库数据到 ElasticSearch
在开发过程中,我们经常会遇到对业务数据进行模糊搜索的需求,例如电商网站对于商品的搜索,以及内容网站对于内容的关键字检索等等。对于这些高级的搜索功能,显然数据库的 Like 是不合适的,通常我们采用 ElasticSearch 来完成数据的搜索和分析,有了这个利器,我们可以轻松应对上述场景,实现关键字搜索等功能。
不过,由于增加了 ElasticSearch 作为搜索引擎,随之而来的问题就是,如何将业务中的数据同步到 ElasticSearch 中,主要有两种方式:
- 业务双写(具有侵入性)
- 数据库同步
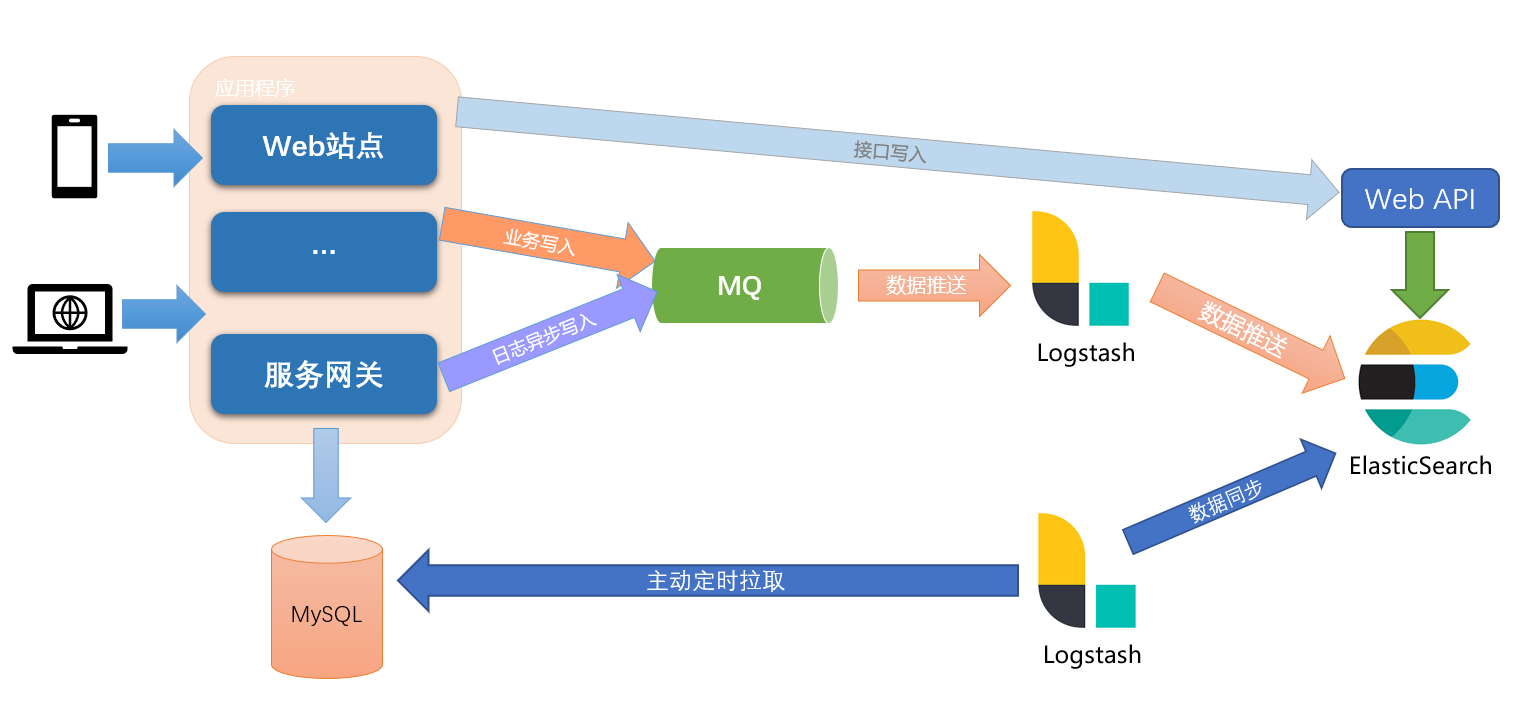
由于业务双写需要更改业务代码,一般不建议采用此种方式,除非有强一致性要求,或者对业务侵入不敏感的系统可以采取此种方式:
- 强一致性:同步通过HTTP请求写入 ElasticSearch
- 最终一致性:
- 可采取业务写入日志,后端通过日志流数据过滤写入 ElasticSearch(ELK标准模式,推荐)
- 另一种方案就是同步写入 MQ,后端通过消费MQ异步写入 ElasticSearch
本文主要讨论非代码侵入的数据库同步方式,主要采用的是通过 LogStash 定时扫描数据库来增量同步数据的方案。
数据库脚本
数据库表结构中,需要有一个时间类型的字段作为增量更新的标识字段(例如 lastupdatetime),当该条数据更新时,必须同时更新该字段。
CREATE TABLE user (
`id` int(11) NOT NULL,
`name` varchar(50) NOT NULL,
`age` int(11) NOT NULL,
`createtime` datetime(0) NOT NULL,
`lastupdatetime` datetime(0) NOT NULL,
PRIMARY KEY (`id`) USING BTREE
)
INSERT INTO `user` VALUES(1,"jack",18,Now(),Now())
INSERT INTO `user` VALUES(2,"William",18,Now(),Now())
SELECT * from `user`
查询结果:
| id | name | age | createtime | lastupdatetime |
|---|---|---|---|---|
| 1 | jack | 18 | 2019-10-24 10:31:14 | 2019-10-24 10:31:14 |
| 2 | William | 18 | 2019-10-24 10:31:49 | 2019-10-24 10:31:49 |
LogStash 配置信息
logstash docker 安装脚本:
mkdir /opt/logstashsync/
mkdir /opt/logstashsync/pipeline
vi /opt/logstashsync/pipeline/logstash.conf
input {
jdbc {
jdbc_driver_library => "/app/mysql-connector-java-8.0.18.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://192.168.10.102:3306/synctest"
jdbc_user => "root"
jdbc_password => "123456"
tracking_column => "unix_ts_in_secs"
use_column_value => true
schedule => "*/5 * * * * *"
statement => "SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > :sql_last_value AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC"
}
}
filter {
mutate {
copy => { "id" => "[@metadata][_id]"}
remove_field => ["id", "@version", "unix_ts_in_secs"]
}
}
output {
elasticsearch {
hosts => "192.168.10.102:9200"
index => "syncuser"
timeout => 300
document_id => "%{[@metadata][_id]}"
}
}
上述配置说明:
- jdbc_driver_library:logstash的镜像中并不包含 jdbc connector,需要在官方网站中下载下来之后,在容器启动时映射到容器中,可点此下载。
- tracking_column:用于跟踪 Logstash从MySQL读取的最后最后一条数据的 lastupdatetime 的值,并默认持久化到磁盘文件 .logstash_jdbc_last_run 中。该值用于在下一次循环同步时,同步的起始值,从而达到增量同步的作用,存储在 .logstash_jdbc_last_run 在 SQL 语句中可以以 :sql_last_value 访问。
- schedule:设置多久循环同步一次,以cron语法指定,我们当前设置的是5秒一次循环。
- statement:执行同步的SQL语句。值得注意的是where条件中为什么要这么写,可以参考 https://www.elastic.co/blog/how-to-keep-elasticsearch-synchronized-with-a-relational-database-using-logstash 文章中给定的解释。
- 重要: 关于上述配置中的 [@metadata][_id],在同步过程中,必须使用数据库数据id作为 ElasticSearch 中的文档 _id,这样当数据库中该条数据有修改时,ElasticSearch 中的文档才会相应的同步修改,否则会以一条新的数据插入 ElasticSearch,导致数据同步错误。
有了上述配置,我们把 Logstath 的 docker 容器跑起来:
docker run -d \
-v /opt/logstashsync/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /opt/logstashsync/pipeline/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
-v /opt/logstashsync/mysql-connector-java-8.0.18.jar:/app/mysql-connector-java-8.0.18.jar \
--name=logstash \
logstash:6.7.1
注意:上述脚本可以看到,我们将本地 /opt/logstashsync/ 目录下的 mysql-connector-java-8.0.18.jar 映射到了容器的 /app 目录下,对应在上述 logstash.conf 中的配置的 jdbc_driver_library 的值
通过查看 Logstash 容器运行日志,我们可以看到如下日志内容,说明该容易已经按照我们预期的每5s同步一次数据库:
[2019-10-25T06:27:59,056][INFO ][logstash.inputs.jdbc ] (0.039651s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 0 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC
[2019-10-25T06:28:05,154][INFO ][logstash.inputs.jdbc ] (0.004232s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 1571913109 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC
[2019-10-25T06:28:10,230][INFO ][logstash.inputs.jdbc ] (0.002832s) SELECT *, UNIX_TIMESTAMP(lastupdatetime) AS unix_ts_in_secs FROM user WHERE (UNIX_TIMESTAMP(lastupdatetime) > 1571913109 AND lastupdatetime < NOW()) ORDER BY lastupdatetime ASC
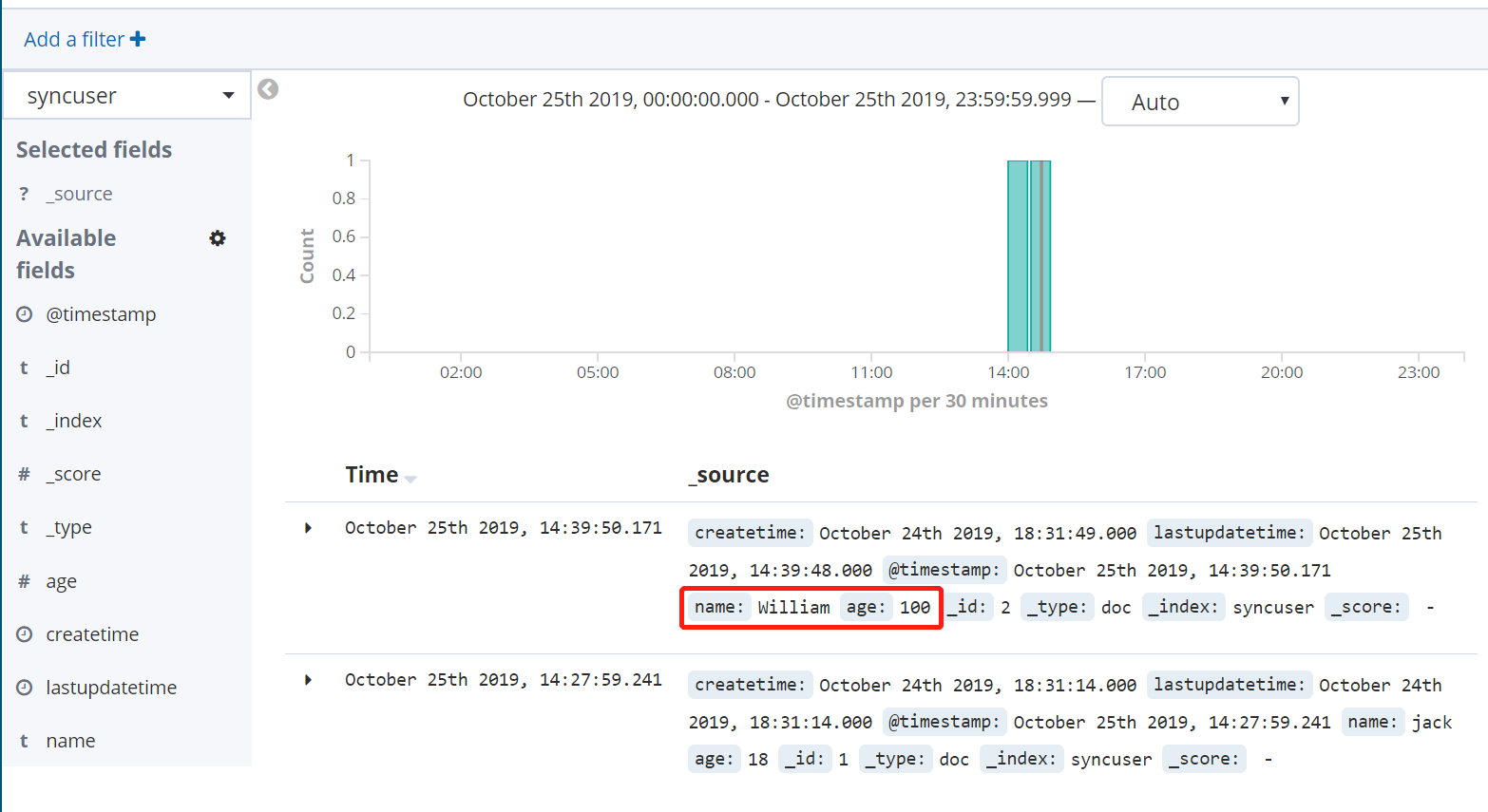
通过Kibana查询同步结果
在 Kibana 中创建 syncuser index,即可以查看到已经同步的数据:

尝试对数据库数据做更新操作,将名为 William 的用户年龄修改为100(记得同时要更新lastupdatetime 字段):
UPDATE `user` SET age=100, lastupdatetime=NOW() WHERE `name`='William';
SELECT * from `user`

再次查看 Kibana 中的数据,可以看到该数据已经成功同步:
结语
根据上述过程,我们完成了简单的单表数据定时同步至 ElasticSearch 过程,但是在实际使用过程中,需要注意以下问题:
- sql语句需要考虑每次同步最大条数。大多数情况下,数据库可能已经存在大量数据,如果不做控制,可能会导致 Logstash 刚启动时一次同步的数据量过大,发生异常,采取的方式可以在 SQL 语句中增加每次获取最大条数限制。
- 增量更新的标识字段,既然是通过>号方式判断,那么如果id是自增主键,也可以采用 int 类型的主键字段,这样可以减少在数据库中创建 lastupdatetime 索引。但如果不是主键,则需要谨慎使用,具体原因请仔细参考上述配置说明中 statement 给出的链接。
- 由于增量同步机制所致,所有数据库中的删除操作应该以软删除的方式进行,即增加 is_delete 字段,否则如果硬删除会导致该条数据状态无法同步至 ElasticSearch,当然在查询 ElasticSearch 时,也应该增加该条件,排除已经删除的数据。
如何通过 Docker 部署 Logstash 同步 Mysql 数据库数据到 ElasticSearch的更多相关文章
- 使用logstash同步mysql数据库信息到ElasticSearch
本文介绍如何使用logstash同步mysql数据库信息到ElasticSearch. 1.准备工作 1.1 安装JDK 网上文章比较多,可以参考:https://www.dalaoyang.cn/a ...
- Logstash同步mysql数据库信息到ES
@font-face{ font-family:"Times New Roman"; } @font-face{ font-family:"宋体"; } @fo ...
- 使用canal增量同步mysql数据库信息到ElasticSearch
本文介绍如何使用canal增量同步mysql数据库信息到ElasticSearch.(注意:是增量!!!) 1.简介 1.1 canal介绍 Canal是一个基于MySQL二进制日志的高性能数据同步系 ...
- 使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch
本文介绍如何使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch. 1.go-mysql-elasticsearch简介 go-mysql-elasti ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第四篇:使用go-mysql-elasticsearch同步mysql数据库信息到ElasticSearch
文章转载自: https://www.cnblogs.com/dalaoyang/p/11018541.html 1.go-mysql-elasticsearch简介 go-mysql-elastic ...
- 使用logstash同步MySQL数据到ES
使用logstash同步MySQL数据到ES 版权声明:[分享也是一种提高]个人转载请在正文开头明显位置注明出处,未经作者同意禁止企业/组织转载,禁止私自更改原文,禁止用于商业目的. https:// ...
- centos7配置Logstash同步Mysql数据到Elasticsearch
Logstash 是开源的服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到您最喜欢的“存储库”中.个人认为这款插件是比较稳定,容易配置的使用Logstash之前,我们得明确 ...
- Elasticsearch的快速使用——Spring Boot使用Elastcisearch, 并且使用Logstash同步mysql和Elasticsearch的数据
我主要是给出一些方向,很多地方没有详细说明.当时我学习的时候一直不知道怎么着手,花时间找入口点上比较多,你们可以直接顺着方向去找资源学习. 如果不是Spring Boot项目,那么根据Elastics ...
- 在Linux环境下,将Solr部署到tomcat7中,导入Mysql数据库数据, 定时更新索引
什么是solr solr是基于Lucene的全文搜索服务器,对Lucene进行了扩展优化. 准备工作 首先,去下载以下软件包: JDK8:jdk-8u60-linux-x64.tar.gz TOMCA ...
随机推荐
- oracle 11g 下载安装 使用记录
Oracle 11g 使用记录 1.下载oracle快捷安装版: (1)下载连接:https://pan.baidu.com/s/1ClC0hQepmTw2lSJ2ODtL7g 无提取码 (2)去 ...
- DOM之事件(一)
DOM事件,就是浏览器或用户针对页面可以做出的某种动作,我们称这些动作为DOM事件.它是用户和页面交互的核心.当动作发生(事件触发)时,我们可以为其绑定一个或多个事件处理程序(函数),来完成我们想要实 ...
- Git初始化项目 和 Gitignore
初始化init: git init git status git add . git commit -am "init projrct" 添加远程仓库: git remote ad ...
- Scala Class etc.
Classes 一个源文件可包含多个类,每个类默认都是 public 类字段必须初始化,编译后默认是 private,自动生成 public 的 getter/setter :Person 示例 pr ...
- Kotlin学习系列(二)
IF表达式 if在kotlin可以当做表达式使用跟java的三元操作符类似: var max = if( a > b ) a else b if分支可以使用代码块,最后一个表达式是返回值: va ...
- 阿里云服务器CentOS6.9安装Mysql
上篇讲了CentOS6.9安装tomcat,这篇来讲mysql的安装 1.查看CentOS是否安装了MySQL yum list installed | grep mysql //查看CentOS是否 ...
- Java入门学习笔记(全)
JAVA https://zhuanlan.zhihu.com/p/21454718 引用部分实验楼代码,侵删 先通读文档 再亲自试标程 复习时自己再批注 1.a = b += c = -~d a = ...
- <反向传播(backprop)>梯度下降法gradient descent的发展历史与各版本
梯度下降法作为一种反向传播算法最早在上世纪由geoffrey hinton等人提出并被广泛接受.最早GD由很多研究团队各自发表,可他们大多无人问津,而hinton做的研究完整表述了GD方法,同时hin ...
- C++常用库函数(1)
Hello,疯狂的杰克由于大家见面了哦! 今天,给大家介绍一篇很有内涵的文章:C++常用库函数 1.缓冲区操作函数 函数名:memchr 函数原型:void *memchr(const void * ...
- 值类型不允许赋值为Null
与引用类型不同,值类型不可能包含 null 值. 每种值类型均有一个隐式的默认构造函数来初始化该类型的默认值.有关值类型默认值的信息,请参见默认值表. bool false byte 0 char ' ...