数据库优化 - SQL优化
前面一篇文章从实例的角度进行数据库优化,通过配置一些参数让数据库性能达到最优。但是一些“不好”的SQL也会导致数据库查询变慢,影响业务流程。本文从SQL角度进行数据库优化,提升SQL运行效率。
判断问题SQL
判断SQL是否有问题时可以通过两个表象进行判断:
- 系统级别表象
- CPU消耗严重
- IO等待严重
- 页面响应时间过长
- 应用的日志出现超时等错误
可以使用sar命令,top命令查看当前系统状态。

也可以通过Prometheus、Grafana等监控工具观察系统状态。(感兴趣的可以翻看我之前的文章)
- SQL语句表象
- 冗长
- 执行时间过长
- 从全表扫描获取数据
- 执行计划中的rows、cost很大
冗长的SQL都好理解,一段SQL太长阅读性肯定会差,而且出现问题的频率肯定会更高。更进一步判断SQL问题就得从执行计划入手,如下所示:

执行计划告诉我们本次查询走了全表扫描Type=ALL,rows很大(9950400)基本可以判断这是一段"有味道"的SQL。
获取问题SQL
不同数据库有不同的获取方法,以下为目前主流数据库的慢查询SQL获取工具
- MySQL
- 慢查询日志
- 测试工具loadrunner
- Percona公司的ptquery等工具
- Oracle
- AWR报告
- 测试工具loadrunner等
- 相关内部视图如v$sql、v$session_wait等
- GRID CONTROL监控工具
- 达梦数据库
- AWR报告
- 测试工具loadrunner等
- 达梦性能监控工具(dem)
- 相关内部视图如v$sql、v$session_wait等
SQL编写技巧
SQL编写有以下几个通用的技巧:
• 合理使用索引
索引少了查询慢;索引多了占用空间大,执行增删改语句的时候需要动态维护索引,影响性能
选择率高(重复值少)且被where频繁引用需要建立B树索引;一般join列需要建立索引;复杂文档类型查询采用全文索引效率更好;索引的建立要在查询和DML性能之间取得平衡;复合索引创建时要注意基于非前导列查询的情况
• 使用UNION ALL替代UNION
UNION ALL的执行效率比UNION高,UNION执行时需要排重;UNION需要对数据进行排序
• 避免select * 写法
执行SQL时优化器需要将 * 转成具体的列;每次查询都要回表,不能走覆盖索引。
• JOIN字段建议建立索引
一般JOIN字段都提前加上索引
• 避免复杂SQL语句
提升可阅读性;避免慢查询的概率;可以转换成多个短查询,用业务端处理
• 避免where 1=1写法
• 避免order by rand()类似写法
RAND()导致数据列被多次扫描
SQL优化
执行计划
完成SQL优化一定要先读执行计划,执行计划会告诉你哪些地方效率低,哪里可以需要优化。我们以MYSQL为例,看看执行计划是什么。(每个数据库的执行计划都不一样,需要自行了解)
explain sql

| 字段 | 解释 |
|---|---|
| id | 每个被独立执行的操作标识,标识对象被操作的顺序,id值越大,先被执行,如果相同,执行顺序从上到下 |
| select_type | 查询中每个select 字句的类型 |
| table | 被操作的对象名称,通常是表名,但有其他格式 |
| partitions | 匹配的分区信息(对于非分区表值为NULL) |
| type | 连接操作的类型 |
| possible_keys | 可能用到的索引 |
| key | 优化器实际使用的索引(最重要的列) 从最好到最差的连接类型为const、eq_reg、ref、range、index和ALL。当出现ALL时表示当前SQL出现了“坏味道” |
| key_len | 被优化器选定的索引键长度,单位是字节 |
| ref | 表示本行被操作对象的参照对象,无参照对象为NULL |
| rows | 查询执行所扫描的元组个数(对于innodb,此值为估计值) |
| filtered | 条件表上数据被过滤的元组个数百分比 |
| extra | 执行计划的重要补充信息,当此列出现Using filesort , Using temporary 字样时就要小心了,很可能SQL语句需要优化 |
接下来我们用一段实际优化案例来说明SQL优化的过程及优化技巧。
优化案例
表结构
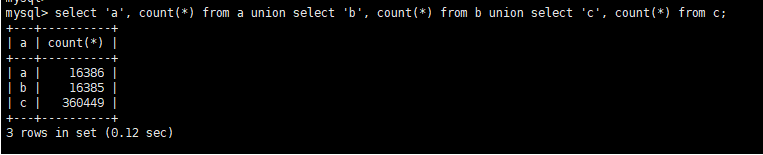
CREATE TABLE `a` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_id` bigint(20) DEFAULT NULL, `seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `b` ( `id` int(11) NOT NULLAUTO_INCREMENT, `seller_name` varchar(100) DEFAULT NULL, `user_id` varchar(50) DEFAULT NULL, `user_name` varchar(100) DEFAULT NULL, `sales` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) ); CREATE TABLE `c` ( `id` int(11) NOT NULLAUTO_INCREMENT, `user_id` varchar(50) DEFAULT NULL, `order_id` varchar(100) DEFAULT NULL, `state` bigint(20) DEFAULT NULL, `gmt_create` varchar(30) DEFAULT NULL, PRIMARY KEY (`id`) );三张表关联,查询当前用户在当前时间前后10个小时的订单情况,并根据订单创建时间升序排列,具体SQL如下
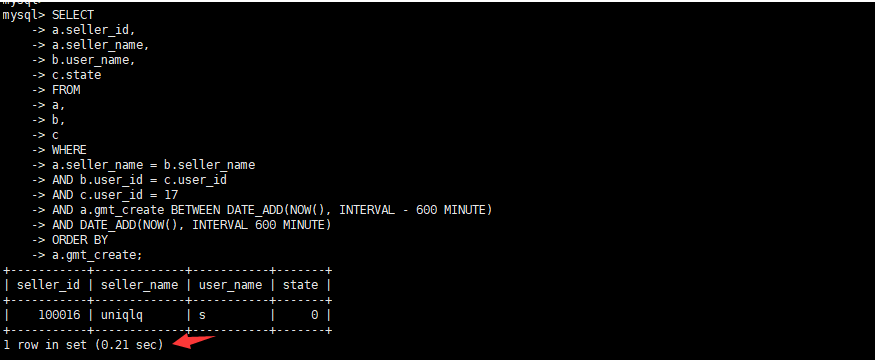
select a.seller_id, a.seller_name, b.user_name, c.state from a, b, c where a.seller_name = b.seller_name and b.user_id = c.user_id and c.user_id = 17 and a.gmt_create BETWEEN DATE_ADD(NOW(), INTERVAL – 600 MINUTE) AND DATE_ADD(NOW(), INTERVAL 600 MINUTE) order by a.gmt_create;查看数据量
原执行时间
原执行计划
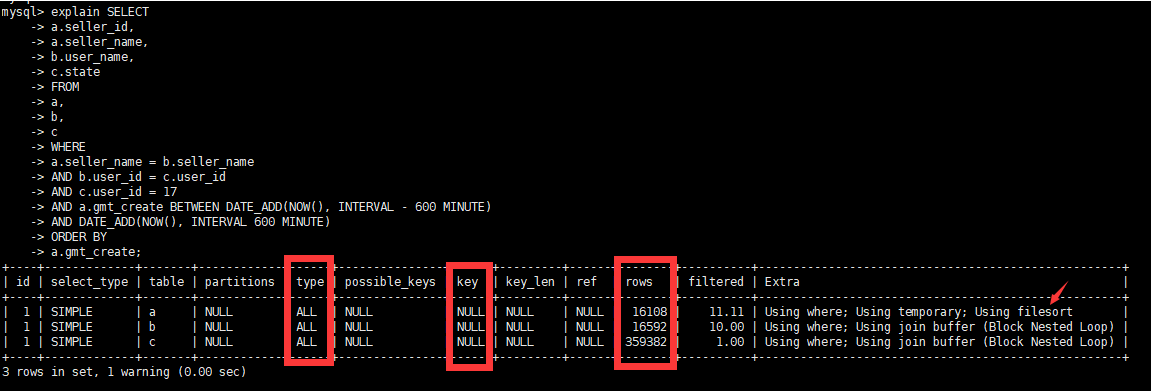
- 初步优化思路
- SQL中 where条件字段类型要跟表结构一致,表中
user_id为varchar(50)类型,实际SQL用的int类型,存在隐式转换,也未添加索引。将b和c表user_id字段改成int类型。 - 因存在b表和c表关联,将b和c表
user_id创建索引 - 因存在a表和b表关联,将a和b表
seller_name字段创建索引 - 利用复合索引消除临时表和排序
- SQL中 where条件字段类型要跟表结构一致,表中
初步优化SQL
alter table b modify `user_id` int(10) DEFAULT NULL; alter table c modify `user_id` int(10) DEFAULT NULL; alter table c add index `idx_user_id`(`user_id`); alter table b add index `idx_user_id_sell_name`(`user_id`,`seller_name`); alter table a add index `idx_sellname_gmt_sellid`(`gmt_create`,`seller_name`,`seller_id`);查看优化后执行时间
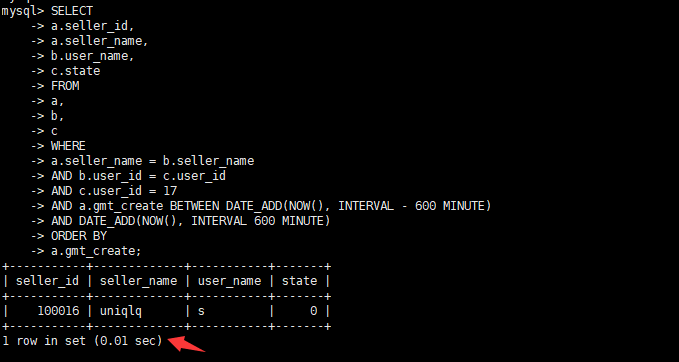
查看优化后执行计划
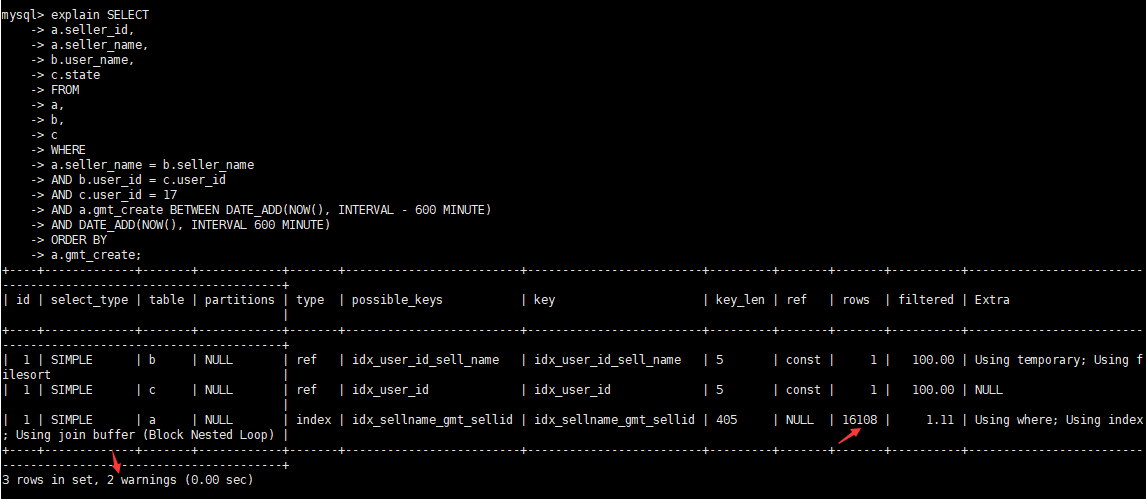
查看warnings信息
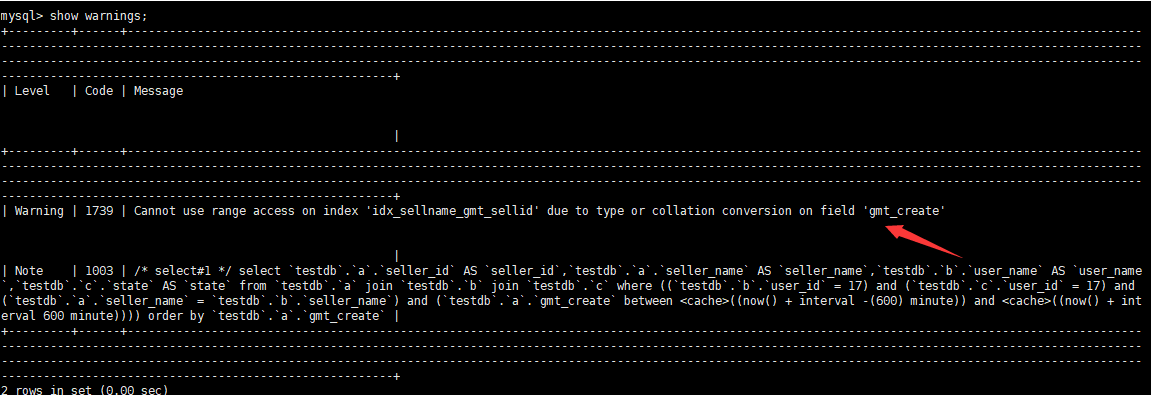
继续优化
alter table a modify "gmt_create" datetime DEFAULT NULL;查看执行时间
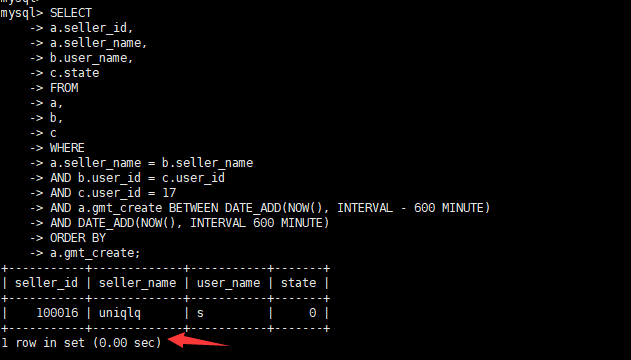
查看执行计划
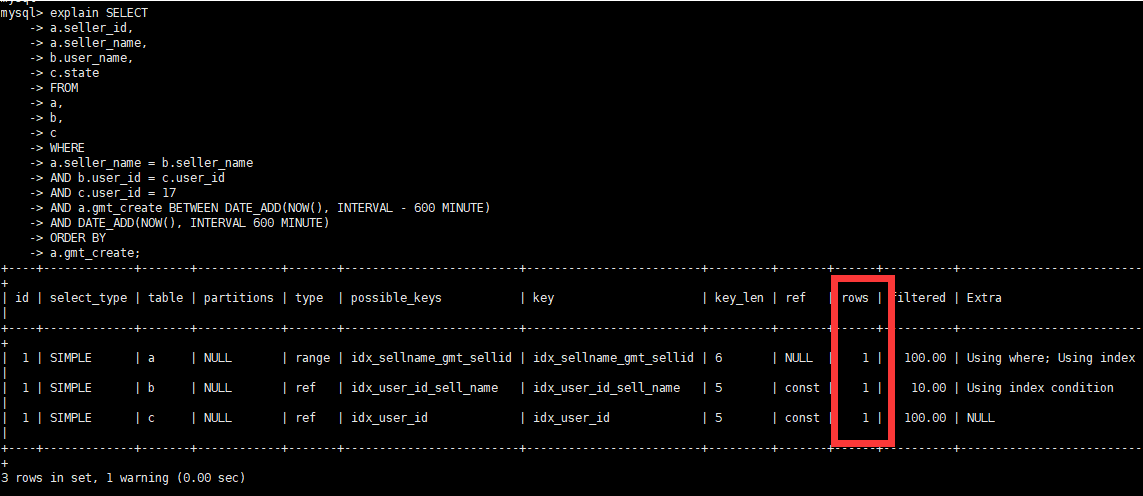
- 优化总结
- 查看执行计划 explain
- 如果有告警信息,查看告警信息 show warnings;
- 查看SQL涉及的表结构和索引信息
- 根据执行计划,思考可能的优化点
- 按照可能的优化点执行表结构变更、增加索引、SQL改写等操作
- 查看优化后的执行时间和执行计划
如果优化效果不明显,重复第四步操作
请关注个人公众号:JAVA日知录

数据库优化 - SQL优化的更多相关文章
- 【数据库】SQL优化方法汇总
最近在研究SQL语句的优化问题. 下面是从网上搜集的,有的地方有点老了,可是还是有很多可以借鉴的地方的. 如何加快查询速度? 1.升级硬件. 2.根据查询条件,建立索引,优化索引.优化访问方式,限制结 ...
- 聊聊数据库~4.SQL优化篇
1.5.查询的艺术 上期回顾:https://www.cnblogs.com/dotnetcrazy/p/10399838.html 本节脚本:https://github.com/lotapp/Ba ...
- 转载 数据库优化 - SQL优化
判断问题SQL判断SQL是否有问题时可以通过两个表象进行判断: 系统级别表象CPU消耗严重IO等待严重页面响应时间过长应用的日志出现超时等错误可以使用sar命令,top命令查看当前系统状态. 也可以通 ...
- 面试问题之数据库:SQL优化的具体操作
转载于:https://www.cnblogs.com/wangzhengyu/p/10412499.html SQL优化的具体操作: 1.尽量避免使用select *,返回无用的字段会降低查询效率. ...
- 二,mysql优化——sql优化基本概念
1,SQL优化的一般步骤 (1)通过show status命令了解各种SQL执行效率. (2)通过执行效率较低的SQL语句(重点select). (3)通过explain分析低效率的SQL语句的执行情 ...
- MySQL单机优化---SQL优化
SQL优化(变多次维护为一次维护) Sql优化分为:DDL.DML.DQL 一.DDL优化 1 .通过禁用索引来提供导入数据性能 . 这个操作主要针对有数据库的表,追加数据 //去除键 alter t ...
- SQL精华总结索引类型优化SQL优化事务大表优化思维导图❤️
索引类型 从数据结构角度: B+树索引, hash索引,基于哈希表实现,只有全值匹配才有效.以链表的形式解决冲突.查找速度非常快 O(1) 全文索引,查找的是文本中的关键词,而不是直接比较索引中的值, ...
- 数据库及SQL优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- 数据库的SQL优化
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. (因为在条件查询条件添加索引,会直接被检索到列,会非常的快速) 2.应尽量避免在 wher ...
随机推荐
- AJAX基础内容
1.什么是ajax?为什么要使用ajax? ajax是Asynchronous JavaScript and XML ,也称为创建交互式网页应用开发技术. 2.为什么采用ajax 1)通过异步交互,提 ...
- Audio Bit Depth Super-Resolution with Neural Networks
Audio Bit Depth Super-Resolution with Neural Networks 作者:Thomas Liu.Taylor Lundy.William Qi 摘要 Audio ...
- 使用Storm实现累加求和操作
package com.csylh; import org.apache.storm.Config; import org.apache.storm.LocalCluster; import org. ...
- Scrapy项目 - 数据简析 - 实现斗鱼直播网站信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 2-3个图,作业文字描述) 本次将所爬取的数据信息,如:房间数,直播类别和人气,导入Weka 3.7工具进行数据分析.有关本次的数据分析详情详见下图所示: ...
- freemarker常用属性
1.th:action 定义后台控制器的路径,类似<form>标签的action属性. 示例如下. <form id="login" th:action=&quo ...
- linux 查看文件大小命令
1.# ls -l (k) ls -l total -rw-r----- root root Oct : catalina.--.log -rw-r----- root root Oct : cata ...
- 离线服务器安装zabbix
因为机房内的服务器并不是所有都能上外网,所以利用zabbix官方源的安装方法就行不通了,又嫌弃编译安装麻烦,所以这里选择离线RPM包安装zabbix.(如需完整rpm包可以留言与我联系) 下载zabb ...
- Java 学习笔记之 线程安全
线程安全: 线程安全的方法一定是排队运行的. public class SyncObject { synchronized public void methodA() { try { System.o ...
- document.body.scrollTop等常见易混淆属性整理
网页可见区域宽: document.body.clientWidth; 网页可见区域宽: document.body.offsetWidth (包括边线的宽); 网页可见区域高: do ...
- 分库分表(5) ---SpringBoot + ShardingSphere 实现分库分表
分库分表(5)--- ShardingSphere实现分库分表 有关分库分表前面写了四篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论) 3. ...