Python-beautifulsoup库
#beautifulsoup库的安装
pip install beautifulsoup4
python -m pip install --upgrage pip
from bs4 import BeautifulSoup #----------------beautifulsoup库的使用--------------------------------------
import requests
from bs4 import BeautifulSoup
url = "http://python123.io/ws/demo.html"
r = requests.get(url)
# print(r.text)
demo = r.text
soup = BeautifulSoup(demo,"html.parser") #熬一锅`粥
#print(soup.prettify()) #打印这锅粥 #下行遍历函数:.contents() .children()用于循环 .descendants()
soup.head #获取head标签
soup.head.contents #获取head的子节点,返回类型是列表
soup.body.contents #
len(soup.body.contents) #terurn 5
soup.body.contents[2]
print('以下输出子节点:')
for child in soup.body.children:
print('##',child)
print('以下输出子孙节点:')
for child in soup.body.descendants:
print('**',child) #---上行遍历 .parent .parents(用于循环)
soup.title.parent #return <head><title>This is a python demo page</title></head>
soup.html.parents #返回 html所有内容
soup.parent #返回为空
print('以下输出父节点:')
for par in soup.a.parents:
if par is None:
print('$$$',par)
else:
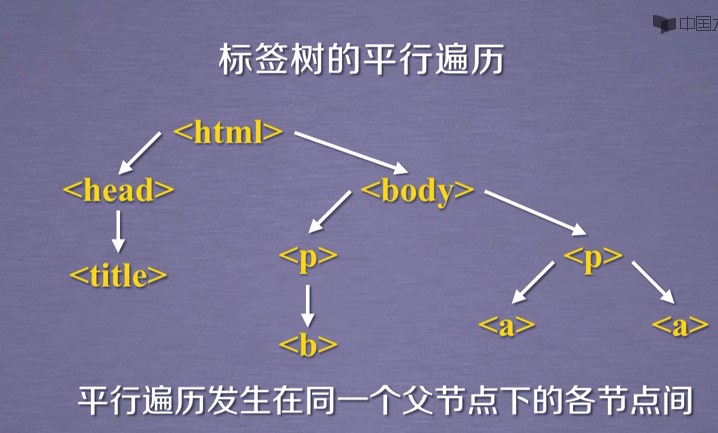
print('%',par.name) #----平行遍历----
# 向后.next_sibling 向前.previous_sibling 加 s 用于遍历
#title 与 p标签 不构成平行关系
soup.a.next_sibling #return ' and ' 所以<a>标签的下一个标签不一定是<a>标签,需要判断
soup.a.next_sibling.next_sibling #return <a ...</a> soup.a.previous_sibling
soup.a.previous_sibling.previous_sibling
print('以下输出下行遍历:')
for sibling in soup.a.next_siblings:
print('##',sibling)
print('以下输出上行遍历:')
for sibling in soup.a.previous_siblings:
print('**',sibling)

Python-beautifulsoup库的更多相关文章
- python BeautifulSoup库的基本使用
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简单又常用的导航(navigating),搜索以 ...
- python BeautifulSoup库用法总结
1. Beautiful Soup 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- Python BeautifulSoup库的用法
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的Python库,它通过解析器把文档解析为利于人们理解的文档导航模式,有利于查找和修改文档. BeautifulSoup3目前已经 ...
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
- python爬虫从入门到放弃(六)之 BeautifulSoup库的使用
上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器. beautifulSoup ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- python下载安装BeautifulSoup库
python下载安装BeautifulSoup库 1.下载https://www.crummy.com/software/BeautifulSoup/bs4/download/4.5/ 2.解压到解压 ...
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
最近在看爬虫相关的东西,一方面是兴趣,另一方面也是借学习爬虫练习python的使用,推荐一个很好的入门教程:中国大学MOOC的<python网络爬虫与信息提取>,是由北京理工的副教授嵩天老 ...
- python库:bs4,BeautifulSoup库、Requests库
Beautiful Soup https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ Beautiful Soup 4.2.0 文档 htt ...
随机推荐
- ThreadLocal小试牛刀
ThreadLocal中保存的数据只能被当前线程私有,不被其它线程可见 证明 声明一个全局的变量threadLocal,初始值为1,通过3个线程对其进行访问修改设置,理论上threadLocal的最终 ...
- Leetcode Tags(5)Hash Table
一.500. Keyboard Row 给定一个单词列表,只返回可以使用在键盘同一行的字母打印出来的单词. 输入: ["Hello", "Alaska", &q ...
- 在vue中使用Ueditor
今天研究的主角是:UEditor UEditor是由百度WEB前端研发部开发的所见即所得的开源富文本编辑器,具有轻量.可定制.用户体验优秀等特点. 版本有很多 我用的是:[1.4.3.3 PHP 版本 ...
- SAP Web Service简介与配置方法
[版权声明]本文为博主原创文章,转载请在明显位置注明出处. 一. SAP Web Service简介 二. SAP Web Service配置准备工作 1. 通过RZ10配置服务器名称和其他参数 2. ...
- 在VMware下进行的Windows2008操作系统虚拟机的安装
一.VMware虚拟机的安装 首先你需要拥有一款软件VMware,这是一款虚拟机安装软件.Vmware比起Vbox收费较贵,占用资源大,但是拥有大量的资源以及拥有克隆技术,适合新手学习使用,较为专业. ...
- Zookeeper作为配置中心使用说明
为了保证数据高可用,那么我们采用Zookeeper作为配置中心来保存数据.SpringCloud对Zookeeper的集成官方也有说明:spring_cloud_zookeeper 这里通过实践的方式 ...
- 深入理解C#第三版部分内容
最近,粗略的读了<深入理解C#(第三版)>这本技术书,书中介绍了C#不同版本之间的不同以及新的功能. 现在将部分摘录的内容贴在下面,以备查阅. C#语言特性: 1.C#2.0 C#2的主 ...
- T1
老师的作业提示里说有难题,也有水题,果真很水... 单纯的模拟加暴力 #include<iostream> using namespace std; int n; ; int cow[ma ...
- 爬虫学习--Day4(网页采集器的实现)
#UA: User-Agent {请求载体的身份标识}#(反爬机制)UA检测:门户网站的服务器回检测对应请求的载体身份标识,如果检测到请求的载体身份为某一款浏览器就说明该请求时一个正常的请求.但是,如 ...
- python入门斐波那契数列之迭代,递归
迭代 def fab(n): a1=1 a2=1 a3=1 if n < 1 : print("输入有误!") return -1 while n-2 > 0 : a3 ...