Python-beautifulsoup库
#beautifulsoup库的安装
pip install beautifulsoup4
python -m pip install --upgrage pip
from bs4 import BeautifulSoup #----------------beautifulsoup库的使用--------------------------------------
import requests
from bs4 import BeautifulSoup
url = "http://python123.io/ws/demo.html"
r = requests.get(url)
# print(r.text)
demo = r.text
soup = BeautifulSoup(demo,"html.parser") #熬一锅`粥
#print(soup.prettify()) #打印这锅粥 #下行遍历函数:.contents() .children()用于循环 .descendants()
soup.head #获取head标签
soup.head.contents #获取head的子节点,返回类型是列表
soup.body.contents #
len(soup.body.contents) #terurn 5
soup.body.contents[2]
print('以下输出子节点:')
for child in soup.body.children:
print('##',child)
print('以下输出子孙节点:')
for child in soup.body.descendants:
print('**',child) #---上行遍历 .parent .parents(用于循环)
soup.title.parent #return <head><title>This is a python demo page</title></head>
soup.html.parents #返回 html所有内容
soup.parent #返回为空
print('以下输出父节点:')
for par in soup.a.parents:
if par is None:
print('$$$',par)
else:
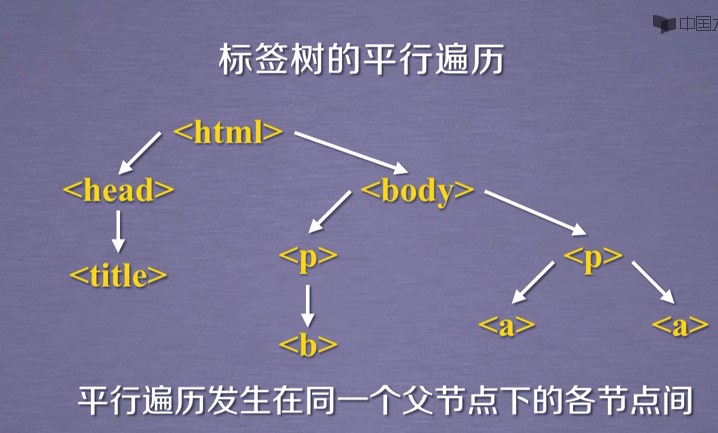
print('%',par.name) #----平行遍历----
# 向后.next_sibling 向前.previous_sibling 加 s 用于遍历
#title 与 p标签 不构成平行关系
soup.a.next_sibling #return ' and ' 所以<a>标签的下一个标签不一定是<a>标签,需要判断
soup.a.next_sibling.next_sibling #return <a ...</a> soup.a.previous_sibling
soup.a.previous_sibling.previous_sibling
print('以下输出下行遍历:')
for sibling in soup.a.next_siblings:
print('##',sibling)
print('以下输出上行遍历:')
for sibling in soup.a.previous_siblings:
print('**',sibling)

Python-beautifulsoup库的更多相关文章
- python BeautifulSoup库的基本使用
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree). 它提供简单又常用的导航(navigating),搜索以 ...
- python BeautifulSoup库用法总结
1. Beautiful Soup 简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.pyt ...
- Python BeautifulSoup库的用法
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的Python库,它通过解析器把文档解析为利于人们理解的文档导航模式,有利于查找和修改文档. BeautifulSoup3目前已经 ...
- Python爬虫-- BeautifulSoup库
BeautifulSoup库 beautifulsoup就是一个非常强大的工具,爬虫利器.一个灵活又方便的网页解析库,处理高效,支持多种解析器.利用它就不用编写正则表达式也能方便的实现网页信息的抓取 ...
- Python爬虫小白入门(三)BeautifulSoup库
# 一.前言 *** 上一篇演示了如何使用requests模块向网站发送http请求,获取到网页的HTML数据.这篇来演示如何使用BeautifulSoup模块来从HTML文本中提取我们想要的数据. ...
- python爬虫从入门到放弃(六)之 BeautifulSoup库的使用
上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器. beautifulSoup ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
- python下载安装BeautifulSoup库
python下载安装BeautifulSoup库 1.下载https://www.crummy.com/software/BeautifulSoup/bs4/download/4.5/ 2.解压到解压 ...
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
最近在看爬虫相关的东西,一方面是兴趣,另一方面也是借学习爬虫练习python的使用,推荐一个很好的入门教程:中国大学MOOC的<python网络爬虫与信息提取>,是由北京理工的副教授嵩天老 ...
- python库:bs4,BeautifulSoup库、Requests库
Beautiful Soup https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/ Beautiful Soup 4.2.0 文档 htt ...
随机推荐
- Kafka 权威指南阅读笔记(第三章,第四章)
Kafka 第三章,第四章阅读笔记 Kafka 发送消息有三种方式:不关心结果的,同步方式,异步方式. Kafka 的异常主要有两类:一种是可重试异常,一种是无需重试异常. 生产者的配置: acks ...
- Apache 4.x HttpClient
public static Map callRequest(String requestUrl, Method method, Map<String, String> data) thro ...
- win7重装系统经验总结报告(2013年6月29日凌晨1:45)
win7重装系统经验总结报告(2013年6月29日凌晨1:45) 步骤: 1.考虑被重做的电脑是否有重要文件在C盘.有则转移到D盘等非系统盘. 2.看该电脑是2GB内存还是4GB以上内存. 3.准备好 ...
- unity UI事件
由于工作需要到持续按键,所以了解了一下unity UI事件,本文主要转载于http://www.cnblogs.com/zou90512/p/3995932.html?utm_source=tuico ...
- django-URL实例命名空间(十一)
每生成一个地址,都是一个实例.使用实例命名空间,针对于一个app而言. book/views.py from django.http import HttpResponse from django.s ...
- jquery获取dom属性方法
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 对于Serializable的理解
对于Serializable的理解 Last Edited: Apr 04, 2019 2:53 PM Tags: java 开始 序列化:把Java对象转换为字节序列的过程. 反序列化:把字节序列恢 ...
- Linux下安装db2V9.7
vi /etc/hosts(127.0.0.1 localhost192.168.1.53 linux-wmv8) vi /etc/services db2inst1 50000/tcp(加在最后) ...
- Golang 实现华为云 DMS 签名
构造请求 首先构造请求,也就是要对哪个具体接口进行访问,需要提供什么必要的参数.在构造请求(点击查看中可以看到,对 DMS 服务来说必要的请求构成包括以下部分 请求URI,例如 https://dms ...
- Java创建线程的四种方式
Java创建线程的四种方式 1.继承Thread类创建线程 定义Thread类的子类,并重写该类的run方法,run()方法的内容就是该线程执行的内容 创建Thread子类的实例,即创建了线程对象. ...