HDFS基本原理
一、什么是HDFS
HDFS即Hadoop分布式文件系统(Hadoop Distributed Filesystem),以流式数据访问模式来存储超大文件,它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS放宽了一部分POSIX约束,来实现流式读取文件系统数据的目的。HDFS在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的。
二、HDFS架构
个HDFS集群包含一个单独的NameNode和多个DataNode。HDFS采用一种称为rack-aware的策略。Rack1 和Rack2
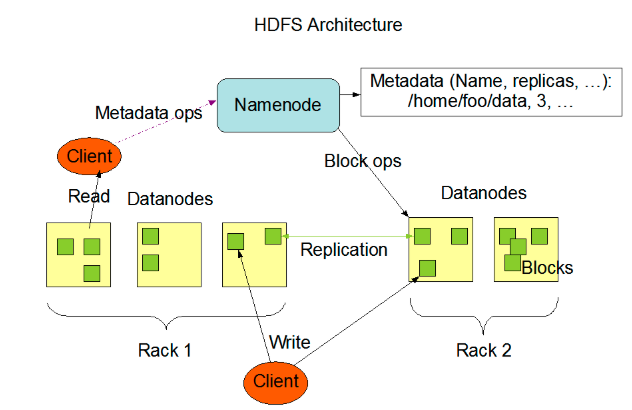
备份数据的存放:备份数据的存放是HDFS可靠性和性能的关键。HDFS采用一种称为rack-aware的策略来决定备份数据的存放。通过一个称为Rack Awareness的过程,NameNode决定每个DataNode所属rack id。缺省情况下,一个block块会有三个备份,一个在NameNode指定的DataNode上,一个在指定DataNode非同一rack的DataNode上,一个在指定DataNode同一rack的DataNode上。这种策略综合考虑了同一rack失效、以及不同rack之间数据复制性能问题。
副本的选择:为了降低整体的带宽消耗和读取延时,HDFS会尽量读取最近的副本。如果在同一个rack上有一个副本,那么就读该副本。如果一个HDFS集群跨越多个数据中心,那么将首先尝试读本地数据中心的副本。安全模式:系统启动后先进入安全模式,此时系统中的内容不允许修改和删除,直到安全模式结束。安全模式主要是为了启动检查各个DataNode上数据块的安全性
三、HDFS核心组件详解
*********************************************************NameNode**************************************************
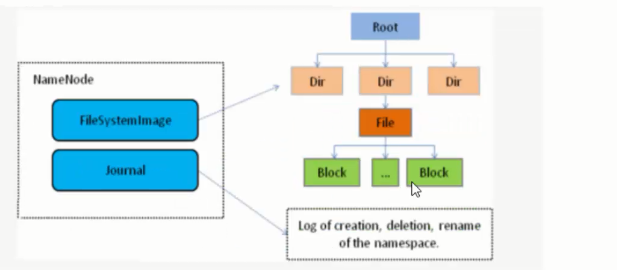
1、NameNode是HDFS的核心模块,也是HDFS架构的master。NomeNode一点宕机则整个HDFS服务不可用。
2、NameNode仅仅存储HDFS的元数据:文件系统中的文件目录结构,并且能跟踪整个集群中的文件。
3、NameNode不存储实际的文件数据,实际数据是存储在DataNode中,他存储的是文件分块的基础数据;能通过文件获取文件的快列表及其分布在哪些dataNode上。
4、NameNode并不会将文件的分块数据持久化存储,这些信息会在HDFS启动时由各个dataNode上报过来。他把这些数据存入内存中。并且会定时对内存中的数据进行快照。所以对于NameNode节点的机器内存应该大一些。
5、NameNode在hadoop 2.0版本之前是单点的,Hadoop 2.0版本才提出了高可用 (High Availability, HA) 解决方案,并且经过多个版本的迭代更新,已经广泛应用于生产环境。
*********************************************************DataNode**************************************************
1、DataNode:HDFS的Slave节点,存储文件实际的数据,负责将数据落入磁盘。所以DataNode节点需要较大的磁盘。
2、DataNode在启动时会将自己发布到NameNode上,并上报自己持有的数据块表。定期向NameNode发送心跳,如果NameNode长时间没有接受到DataNode发送的心跳,NameNode就会认为该DataNode以及失效,将其剔除集群。心跳参数dfs.heartbeat.interval=3(默认3秒发送一次心跳)
3、当某个DateNode宕机后,不会影响数据和集群的可用性。NameNode会安排其他DataNode进行副本复制接管他的工作。
4、DataNode会定时上报自己负责的数据块列表。
*********************************************************Secondary NameNode**************************************************
SecondaryNameNode有两个作用,一是镜像备份,二是日志与镜像的定期合并。两个过程同时进行,称为checkpoint. 镜像备份的作用:备份fsimage(fsimage是元数据发送检查点时写入文件);日志与镜像的定期合并的作用:将Namenode中edits日志和fsimage合并,防止如果Namenode节点故障,namenode下次启动的时候,会把fsimage加载到内存中,应用edit log,edit log往往很大,导致操作往往很耗时。
四、HDFS操作流程
**************************************************文件上传流程******************************************
1、客户端发起写文件请求 hadoop fs -put
2、nameNode检查上传文件的命名空间是否存在(就是检测文件目录结构是否存在),创建者是否有权限进行操作。然后返回状态高数客户端你可以上传数据
3、客户端按照分块配置大小将文件分块。然后请求NameNode我要上传blk1,副本数是三个,这个文件一共分割了5块。
4、NameNode检测自己管理下的DateNodes是否满足要求,然后返回给客户端三台DateNode节点信息(存储策略是机架模式)。
5、Client端根据返回的DataNode信息选择一个离自己最近的一个DataNode节点,创建pipeLine(数据传输管道),DataNode1->DataNode2创建pipeLine,DataNode2->DataNode3创建pipeLine;DataNode3通过这一串管道传递给client数据传输管道已经建立完毕。
6、client端创建Stream流(以packet为单位传输数据 64kb)上传数据。
7、DataNode1接受并保持源源不断的packet,然后把packet源源不断的传递给DataNode2,DataNode2也做相应的操作。
8、DataNode也通过pipeLine发送ACK认证数据是否接收完毕。
9、第一个数据块上传完毕后client端开始上传第二个数据块
*********************************************************文件的获取流程****************************************
1、client 发起 hadoop fs -get请求
2、NomeNode检查该文件的信息,文件的分块信息和每个分块所对应哪个DateNode,,以及备份信息和备份信息所在哪个DataNode。把这些信息返回给client端。(返回原则也是机架原则,根据网络拓扑将距离最近的DataNode排在前边返回)
3、根据NameNode的信息,请求各个文件块对应的DataNode节点获取文件数据。
4、合并下载过来的数据块,形成一个完整的文件。
HDFS基本原理的更多相关文章
- HDFS基本原理及数据存取实战
---------------------------------------------------------------------------------------------------- ...
- HDFS基本原理总结
HDFS由三个基本组件组成:NameNode,SecondaryName,DataNode,其思想类似于Linux的文件系统,可以进行类比. 1.NameNode介绍: 1.管理整个文件系统的命名空间 ...
- 【图文详解】HDFS基本原理
本文主要详述了HDFS的组成结构,客户端上传下载的过程,以及HDFS的高可用和联邦HDFS等内容.若有不当之处还请留言指出. 当数据集大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区,并 ...
- Hadoop之HDFS(二)HDFS基本原理
HDFS 基本 原理 1,为什么选择 HDFS 存储数据 之所以选择 HDFS 存储数据,因为 HDFS 具有以下优点: 1.高容错性 数据自动保存多个副本.它通过增加副本的形式,提高容错性. 某一 ...
- hdfs的基本原理和基本操作总结
hdfs基本原理 Hadoop分布式文件系统(HDFS)被设计成适合执行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有非常多共同点. 但同一时候,它和 ...
- 最通熟易懂的Hadoop HDFS实践攻略
HDFS是用来解决什么问题?怎么解决的? 如何在命令行下操作HDFS? 如何使用Java API来操作HDFS? 在了解基本思路和操作方法后,进一步深究HDFS具体的读写数据流程 学习并实践本文教程后 ...
- Hadoop_HDFS_02
1. HDFS入门 1.1 HDFS基本概念 HDFS是Hadoop Distribute File System的简称, 意为: Hadoop分布式文件系统. 是Hadoop三大核心组件之一, 作为 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 定时脚本: 删除HDFS中的过期文件
1. 基本原理: 通过hadoop fs -ls *命令获取相关文件或目录的修改时间,然后与设定的过期时间进行比较,之后执行删除操作即可 2. 相关代码: #!/bin/bash source ~/. ...
随机推荐
- 微信小程序使用weui构建搜索栏(searchbar)+导航(navbar)
首先需要在lib目录中添加weui.wxss.searchbar和navbar结合主要解决两者的层次问题,即搜索框输入时,下方的检索结果能够覆盖住navbar.下面就开始发码啦: (1)wxml部分: ...
- linux基础学习(一)常用命令:date、pwd、cd、cal、who、wc等等
目录 @(基础命令) Tab键是linux系统中最重要的键之一了,它的功能是命令自动补全== [root@localhost ~]#date 1.用于显示当前的日期和时间 2/用于显示当前的日历 [r ...
- PHP接口自动化测试框架实现
在上一份工作中,我有一部分工作是在维护一套接口自动化测试,这一篇文章,我来介绍这套接口自动化框架的设计思路. 我们来看一个简单的PHP实现的超简单的接口. ... //报名验证 private fun ...
- C++ 基础语法 快速复习笔记---面对对象编程(2)
1.C++面对对象编程: a.定义: 类定义是以关键字 class 开头,后跟类的名称.类的主体是包含在一对花括号中.类定义后必须跟着一个分号或一个声明列表. 关键字 public 确定了类成员的访问 ...
- easyui入门
什么是easyui! easyui=jquery+html4(用来做后台的管理界面) 1.通过layout布局 我们先把该导的包导下 然后就是JSP页面布局 2.通过tree加载菜单 先来一个实体类 ...
- Html学习之五(嵌套之简单购物界面设计)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- css 文本外观属性(text) 和 字体样式属性(font)
css文本 text外观属性 color: 颜色值(red,blue)十六进制 ,rgb letter-spacing: 字间距 px,em word-spacing: 单词间距 对中文无效 line ...
- 《Linux内核原理与分析》教学进程
目录 2019-2020-1 <Linux内核原理与分析>教学进程 考核方案 第一周: 第二周: 第三周: 第四周: 第五周 第六周 第七周: 第八周 第九周 第十周 第十一周: 第十二周 ...
- vs2017 升级后无法启动 z
Visual Studio 2017 无法启动,进程中却有devenv.exe运行的解决办法 双击Visual Studio 2017,系统没有响应,在任务管理器中却发现devenv.exe 已经在运 ...
- STS 创建 Maven 项目填坑
用 STS 创建 Maven 项目并不复杂,只是其中有一些坑在里面,我在解决这些坑的时候发现很多人都遇到了相同的问题,因此把创建的步骤记录在这里.所有的步骤不外乎就是一些套路,并没有什么复杂的地方,只 ...