[Pandas] 03 - DataFrame
DataFrame
Based on NumPy
Ref: Pandas and NumPy arrays explained
Ref: pandas: powerful Python data analysis toolkit【开发者文档】
- dataframe 转化成 array
df=df.values
- array 转化成 dataframe
import pandas as pd df = pd.DataFrame(df)
数据集直接转换为dataframe格式。
import pandas as pd
iris_df = pd.DataFrame(iris.data, columns = iris.feature_names)
表格基本操作
COMP9318/L1 - Pandas-1.ipynb
COMP9318/L1 - Pandas-2.ipynb
COMP9318/L1 - numpy-fundamentals.ipynb
一、初始化
初始化 index & columns
类似于倒排表,column相当于words. index就是doc id.
df = pd.DataFrame([10, 20, 30, 40], columns=['numbers'], index=['a', 'b', 'c', 'd'])
df
Output:
| numbers | |
|---|---|
| a | 10 |
| b | 20 |
| c | 30 |
| d | 40 |
时间序列
以“月”为间隔单位。
dates = pd.date_range('2015-1-1', periods=9, freq='M')
df.index = dates
df
Output:
DatetimeIndex(['2015-01-31', '2015-02-28', '2015-03-31', '2015-04-30',
'2015-05-31', '2015-06-30', '2015-07-31', '2015-08-31',
'2015-09-30'],
dtype='datetime64[ns]', freq='M')
| No1 | No2 | No3 | No4 | |
|---|---|---|---|---|
| 2015-01-31 | -0.173893 | 0.744792 | 0.943524 | 1.423618 |
| 2015-02-28 | -0.388310 | -0.494934 | 0.408451 | -0.291632 |
| 2015-03-31 | 0.675479 | 0.256953 | -0.458723 | 0.858815 |
| 2015-04-30 | -0.046759 | -2.548551 | 0.454668 | -1.011647 |
| 2015-05-31 | -0.938467 | 0.636606 | -0.237240 | 0.854314 |
| 2015-06-30 | 0.134884 | -0.650734 | 0.213996 | -1.969656 |
| 2015-07-31 | 1.046851 | -0.016665 | -0.488270 | 1.377827 |
| 2015-08-31 | 0.482625 | 0.176105 | -0.681728 | -1.057683 |
| 2015-09-30 | -1.675402 | 0.364292 | 0.897240 | -0.629711 |
二、添加数据
添加一列
类似dict的添加方式。
# (1) 其他col默认
df['floats'] = (1.5, 2.5, 3.5, 4.5) # (2) 自定义
df['names'] = pd.DataFrame(['Yves', 'Felix', 'Francesc'], index=['a', 'b', 'c'])
添加一行
类似list的添加方式。
df = df.append(pd.DataFrame({'numbers': 100, 'floats': 5.75, 'names': 'Henry'}, index=['z',]))
添加一行,再添加一列
# 1.1.1 使用vstack增加一行含缺失值的样本(nan, nan, nan, nan), reshape相当于升维度
nan_tmp = array([nan, nan, nan, nan]).reshape(1,-1)
print(nan_tmp)
# 1.1.2 合并两个array
iris.data = vstack((iris.data, array([nan, nan, nan, nan]).reshape(1,-1))) ##########################################################################################
# 1.2.1 使用hstack增加一列表示花的颜色(0-白、1-黄、2-红),花的颜色是随机的,意味着颜色并不影响花的分类
random_feature = choice([0, 1, 2], size=iris.data.shape[0]).reshape(-1,1)
# 1.2.2 合并两个array
iris.data = hstack((random_feature, iris.data))
添加csv文件
df = pd.read_csv('./asset/lecture_data.txt', sep='\t') # to read an excel file, use read_excel()
df.head() # 头五个数据
df.describe() # 统计量信息
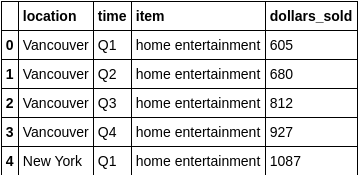
三、查找 select
查找某一个元素
是通过“key" 并非row number。
定位的套路是:row number --> key --> row context --> target
.index, .loc, liloc
df.index # the index values df.loc[['a', 'd']] # selection of multiple indices
df.loc[df.index[1:3]] # 获得索引键值,再得到请求的行。
以上是先获得“某行”;以下是先确定“某列”,再定位“某行”。
df['No2'].iloc[3]
遍历每一行元素
两个方案:itertuples()应该比iterrows()快
import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}]
df = pd.DataFrame(inp)
print(df)
-------------------------------------------------------------------
# 开始遍历,俩个方式等价
for index, row in df.iterrows():
print(row["c1"], row["c2"]) for row in df.itertuples(index=True, name='Pandas'):
print(getattr(row, "c1"), getattr(row, "c2"))
Ref: Iterate over rows in a dataframe in Pandas
拿出某一列元素
这一列的值展示。
In [9]: df.loc[df.index[:]]
Out[9]:
c1 c2
0 10 100
1 11 110
2 12 120 In [10]: df.loc[df.index[:],'c2']
Out[10]:
0 100
1 110
2 120
Name: c2, dtype: int64
列统计
(1) 这一列的 "类型统计"。
# permit_status - Outcome
status_cts = df_train.permit_status.value_counts(dropna=False)
print(status_cts)
# Complete 358
# Cancelled 31
# In Process 7
# Comments:
# - Complete v not (Cancelled or In Process) as binary outcome
(2) 这一列的 "统计量"。
# attendance
attendance_null_ct = df_train.attendance.isnull().sum()
print(attendance_null_ct) #
print(df_train.attendance.describe())
# count 393.000000
# mean 3716.913486
# std 16097.152814
# min 15.000000
# 25% 200.000000
# 50% 640.000000
# 75% 1800.000000
# max 204000.000000
筛选 WHERE
# 列出某一属性的行
f[df['location'] == 'Vancouver'].head() # 更为复杂的条件
df[(df['location'] == 'Vancouver') & (df['time'] != 'Q1') & (df['dollars_sold'] > 500)]
三、合并 join
Ref: JOIN和UNION区别
Ref: What is the difference between join and merge in Pandas?
Pandas写法
这个及其类似SQL JOIN. how = 'inner/left/right/outer'。
df.join(pd.DataFrame([1, 4, 9, 16, 25],
index=['a', 'b', 'c', 'd', 'y'],
columns=['squares',]), how='inner')
JOIN用于按照ON条件联接两个表,主要有四种:
| INNER JOIN | 内部联接两个表中的记录,仅当至少有一个同属于两表的行符合联接条件时,内联接才返回行。我理解的是只要记录不符合ON条件,就不会显示在结果集内。 |
| LEFT JOIN / LEFT OUTER JOIN | 外部联接两个表中的记录,并包含左表中的全部记录。如果左表的某记录在右表中没有匹配记录,则在相关联的结果集中右表的所有选择列表列均为空值。理解为即使不符合ON条件,左表中的记录也全部显示出来,且结果集中该类记录的右表字段为空值。 |
| RIGHT JOIN / RIGHT OUTER JOIN | 外部联接两个表中的记录,并包含右表中的全部记录。简单说就是和LEFT JOIN反过来。 |
| FULL JOIN / FULL OUTER JOIN | 完整外部联接返回左表和右表中的所有行。就是LEFT JOIN和RIGHT JOIN和合并,左右两表的数据都全部显示。 |
SQL写法(参考)
两张表:msp, party。
内连接inner join
SELECT msp.name, party.name FROM msp JOIN party ON party=code
SELECT msp.name, party.name FROM msp inner JOIN party ON party=code 左连接left join
SELECT msp.name, party.name FROM msp LEFT JOIN party ON party=code 右连接right join
SELECT msp.name, party.name FROM msp RIGHT JOIN party ON msp.party=party.code 全连接(full join)
SELECT msp.name, party.name FROM msp FULL JOIN party ON msp.party=party.code
join和union的区别
合并两表,保留共有列。
pd.concat([df2,df3]) pd.concat([df2,df3]).drop_duplicates()
四、预处理 之 Apply
Ref: Pandas的Apply函数——Pandas中最好用的函数

假如我们想要得到表格中的PublishedTime和ReceivedTime属性之间的时间差数据,就可以使用下面的函数来实现:
import pandas as pd
import datetime # 用来计算日期差的包 def dataInterval(data1, data2):
# 以某种格式提取时间信息为可计算的形式
d1 = datetime.datetime.strptime(data1, '%Y-%m-%d')
d2 = datetime.datetime.strptime(data2, '%Y-%m-%d')
delta = d1 - d2
return delta.days def getInterval(arrLike): # 用来计算日期间隔天数的调用的函数
PublishedTime = arrLike['PublishedTime']
ReceivedTime = arrLike['ReceivedTime']
days = dataInterval(PublishedTime.strip(), ReceivedTime.strip()) # 注意去掉两端空白
return days if __name__ == '__main__':
fileName = "NS_new.xls";
df = pd.read_excel(fileName)
df['TimeInterval'] = df.apply(getInterval , axis = 1)
表格数据分析
一、Basic Analytics
df.sum()
df.mean()
df.cumsum()
df.describe()
np.sqrt(abs(df))
np.sqrt(abs(df)).sum()
二、分组统计
原始数据
| No1 | No2 | No3 | No4 | Quarter | |
|---|---|---|---|---|---|
| 2015-01-31 | -0.173893 | 0.744792 | 0.943524 | 1.423618 | Q1 |
| 2015-02-28 | -0.388310 | -0.494934 | 0.408451 | -0.291632 | Q1 |
| 2015-03-31 | 0.675479 | 0.256953 | -0.458723 | 0.858815 | Q1 |
| 2015-04-30 | -0.046759 | -2.548551 | 0.454668 | -1.011647 | Q2 |
| 2015-05-31 | -0.938467 | 0.636606 | -0.237240 | 0.854314 | Q2 |
| 2015-06-30 | 0.134884 | -0.650734 | 0.213996 | -1.969656 | Q2 |
| 2015-07-31 | 1.046851 | -0.016665 | -0.488270 | 1.377827 | Q3 |
| 2015-08-31 | 0.482625 | 0.176105 | -0.681728 | -1.057683 | Q3 |
| 2015-09-30 | -1.675402 | 0.364292 | 0.897240 | -0.629711 | Q3 |
"一维" 分组
三行数据为一组,然后按组统计。
groups = df.groupby('Quarter')
groups.mean()
"二维" 分组
group by 两个columns后的情况。
df['Odd_Even'] = ['Odd', 'Even', 'Odd', 'Even', 'Odd', 'Even', 'Odd', 'Even', 'Odd']
groups = df.groupby(['Quarter', 'Odd_Even'])
groups.mean()
| Quarter | Odd_Even | No1 | No2 | No3 | No4 |
|---|---|---|---|---|---|
| Q1 | Even | -0.388310 | -0.494934 | 0.408451 | -0.291632 |
| Odd | 0.250793 | 0.500873 | 0.242400 | 1.141217 | |
| Q2 | Even | 0.044063 | -1.599643 | 0.334332 | -1.490651 |
| Odd | -0.938467 | 0.636606 | -0.237240 | 0.854314 | |
| Q3 | Even | 0.482625 | 0.176105 | -0.681728 | -1.057683 |
| Odd | -0.314275 | 0.173813 | 0.204485 | 0.374058 |
另一个例子:
type_cat_cts = (
df_train
.groupby([df_train.permit_type, df_train.event_category.isnull()])
.size())
print(type_cat_cts)
# permit_type event_category
# Charter Vessel True 10
# Special Event False 325
# Valet Parking True 61
# Comments:
# - present iff Special Event
分组统计
We use agg() to apply multiple functions at once, and pass a list of columns to groupby() to grouping multiple columns
df.groupby(['location','item']).agg({'dollars_sold': [np.mean,np.sum]})
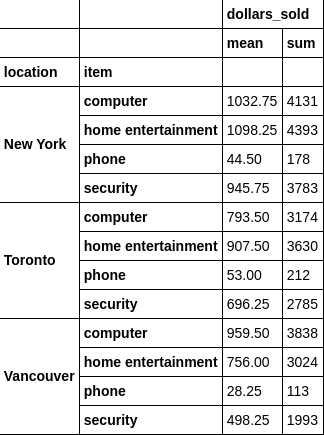
三、数据透视表(Pivot Table)
更多内容,参考:https://github.com/DBWangGroupUNSW/COMP9318/blob/master/L1%20-%20Pandas-2.ipynb
原始数据
如果想做二次更为细分的统计,可以借助pivot_table。
二级列分组
table = pd.pivot_table(df, index = 'location', columns = 'time', aggfunc=np.sum)
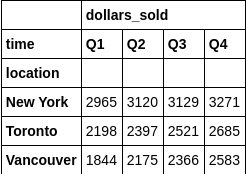
pd.pivot_table(df, index = ['location', 'item'], columns = 'time', aggfunc=np.sum, margins=True)
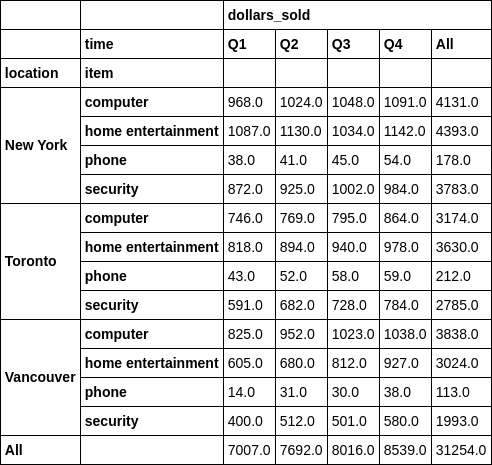
四、表格可视化
%matplotlib inline
df.cumsum().plot(lw=2.0, grid=True) # 线的粗度是2.0
# tag: dataframe_plot
# title: Line plot of a DataFrame object

实战练习
预处理:金融数据展示
一、数据初看
打开文档
Ref: https://github.com/yhilpisch/py4fi/blob/master/jupyter36/source/tr_eikon_eod_data.csv

# data from Thomson Reuters Eikon API
raw = pd.read_csv('source/tr_eikon_eod_data.csv',
index_col=0, parse_dates=True)
raw.info()
只查看一列
# (1) 想看其中的哪一列
data = pd.DataFrame(raw['.SPX'])
data.columns = ['Close'] # (2) 看个别数据,再看总体数据(数据多只能通过figure看)
data.tail()
data['Close'].plot(figsize=(8, 5), grid=True);
# tag: dax
# title: Historical DAX index levels
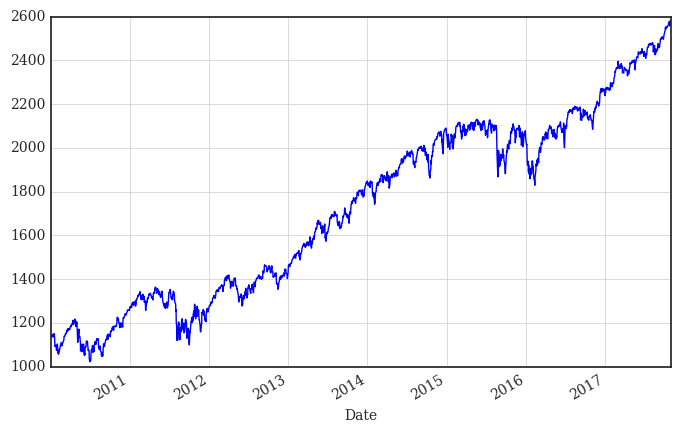
二、进一步查看窗口数据
差值:window size = 2
shift 为1,默认下拉表格位置,也就是表示“上一个值”。
%time data['Return'] = np.log(data['Close'] / data['Close'].shift(1))
data['Return'].plot(figsize=(8, 5), grid=True);
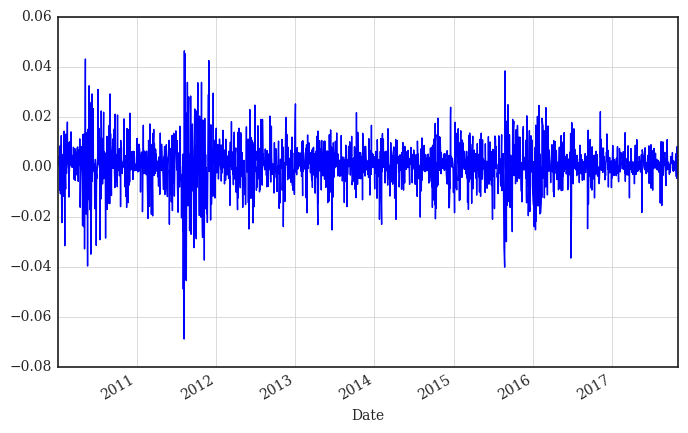
平滑:window size > 2
窗口期数据的“统计量”计算。
data['42d'] = data['Close'].rolling(window=42).mean()
data['252d'] = data['Close'].rolling(window=252).mean()
data[['Close', '42d', '252d']].plot(figsize=(8, 5), grid=True)
# tag: dax_trends
# title: The S&P index and moving averages
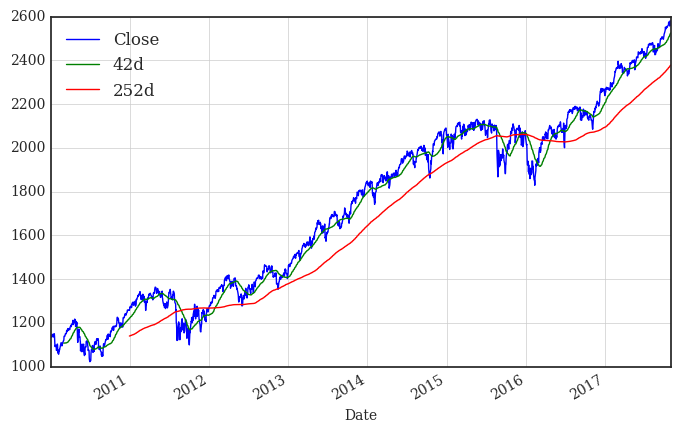
三、多列数据同时显示
两列数据上下显示出来。
data[['Close', 'Return']].plot(subplots=True, style='b', figsize=(8, 5), grid=True);
# tag: dax_returns
# title: The S&P 500 index and daily log returns
训练模型:Regression Analysis
一、准备数据
/* 略 */
二、训练数据
一般的思路,可能选择:scikit learning;当然,NumPy也提供了一些基本的功能。
训练 training
xdat = rets['.SPX'].values
ydat = rets['.VIX'].values
reg = np.polyfit(x=xdat, y=ydat, deg=1)
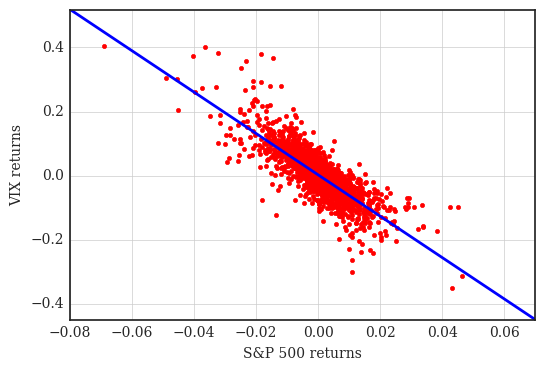
预测并可视化
plt.plot(xdat, ydat, 'r.')
ax = plt.axis() # grab axis values
x = np.linspace(ax[0], ax[1] + 0.01) ------------------------------------------
# 画出预测趋势
plt.plot(x, np.polyval(reg, x), 'b', lw=2)
plt.grid(True)
plt.axis('tight')
plt.xlabel('S&P 500 returns')
plt.ylabel('VIX returns')
# tag: scatter_rets
# title: Scatter plot of log returns and regression line
高频数据
一、引入的问题
思考:High Frequency首先会带来怎么样的问题?
index时间,在秒级以下仍然有很多的数据,但对目前的分析而言其实意义不是很大。
Bid Ask Mid
2017-11-10 13:59:59.716 1.16481 1.16481 1.164810
2017-11-10 13:59:59.757 1.16481 1.16482 1.164815
2017-11-10 14:00:00.005 1.16482 1.16482 1.164820
2017-11-10 14:00:00.032 1.16482 1.16483 1.164825
2017-11-10 14:00:00.131 1.16483 1.16483 1.164830
二、重采样 resampling
这个类似:先分段,再用“统计量”替换“原来的密集的数据”;与窗口策略小有不同。
eur_usd_resam = eur_usd.resample(rule='1min', label='last').last()
eur_usd_resam.head()
End.
[Pandas] 03 - DataFrame的更多相关文章
- Pandas | 03 DataFrame 数据帧
数据帧(DataFrame)是二维数据结构,即数据以行和列的表格方式排列. 数据帧(DataFrame)的功能特点: 潜在的列是不同的类型 大小可变 标记轴(行和列) 可以对行和列执行算术运算 结构体 ...
- python 数据处理学习pandas之DataFrame
请原谅没有一次写完,本文是自己学习过程中的记录,完善pandas的学习知识,对于现有网上资料的缺少和利用python进行数据分析这本书部分知识的过时,只好以记录的形势来写这篇文章.最如果后续工作定下来 ...
- Pandas之Dataframe叠加,排序,统计,重新设置索引
Pandas之Dataframe索引,排序,统计,重新设置索引 一:叠加 import pandas as pd a_list = [df1,df2,df3] add_data = pd.concat ...
- pandas中DataFrame对象to_csv()方法中的encoding参数
当使用pd.read_csv()方法读取csv格式文件的时候,常常会因为csv文件中带有中文字符而产生字符编码错误,造成读取文件错误,在这个时候,我们可以尝试将pd.read_csv()函数的enco ...
- pandas(DataFrame)
DataFrame是二维数据结构,即数据以行和列的表格方式排列!特点:潜在的列是不同的类型,大小可变,标记行和列,可以对列和行执行算数运算. 其中Name,Age即为对应的Columns,序号0,1, ...
- Python3 Pandas的DataFrame数据的增、删、改、查
Python3 Pandas的DataFrame数据的增.删.改.查 一.DataFrame数据准备 增.删.改.查的方法有很多很多种,这里只展示出常用的几种. 参数inplace默认为False,只 ...
- Python3 Pandas的DataFrame格式数据写入excle文件、json、html、剪贴板、数据库
Python3 Pandas的DataFrame格式数据写入excle文件.json.html.剪贴板.数据库 一.DataFrame格式数据 Pandas是Python下一个开源数据分析的库,它提供 ...
- python. pandas(series,dataframe,index) method test
python. pandas(series,dataframe,index,reindex,csv file read and write) method test import pandas as ...
- pandas取dataframe特定行/列
1. 按列取.按索引/行取.按特定行列取 import numpy as np from pandas import DataFrame import pandas as pd df=DataFram ...
随机推荐
- c中自增自减的妙用
#include <stdio.h> int main() { ; printf("%d,%d,%d,%d",i++;i--;++i;--i); /*运算从右往左运算 ...
- Java 8 为什么会引入lambda 表达式?
Java 8 为什么会引入lambda ? 在Java8出现之前,如果你想传递一段代码到另一个方法里是很不方便的.你几乎不可能将代码块到处传递,因为Java是一个面向对象的语言,因此你要构建一个属于某 ...
- Flink的JobManager启动(源码分析)
都知道Flink中的角色分为Jobmanager,TaskManger 在启动脚本里面已经找到了jobmanager的启动类org.apache.flink.runtime.entrypoint.St ...
- 通过视图实现自定义查询<持续完善中。。。>
目前实现: ----普通查询路径 /viewShow/viewShow/list.htm ----Echarts查询路劲 /viewShow/viewShow/echarts.htm 1.自定义查询条 ...
- hive 四种表,分区表,内部,外部表,桶表
Hive四大表类型内部表.外部表.分区表和桶表 一.概述 总体上Hive有四种表:外部表,内部表(管理表),分区表,桶表.分别对应不同的需求.下面主要讲解各种表的适用情形.创建和加载数据方法. 二.具 ...
- 基于Docker搭建Jumpserver堡垒机操作实践
一.背景 笔者最近想起此前公司使用过的堡垒机系统,觉得用的很方便,而现在的公司并没有搭建此类系统,想着以后说不定可以用上:而且最近也有点时间,因此来了搭建堡垒机系统的兴趣,在搭建过程中参考了比较多的文 ...
- 逆向破解之160个CrackMe —— 026
CrackMe —— 026 160 CrackMe 是比较适合新手学习逆向破解的CrackMe的一个集合一共160个待逆向破解的程序 CrackMe:它们都是一些公开给别人尝试破解的小程序,制作 c ...
- 转载-SpringBoot开发案例之整合日志管理
转载:https://cloud.tencent.com/developer/article/1097579 有一种力量无人能抵挡,它永不言败生来倔强.有一种理想照亮了迷茫,在那写满荣耀的地方. 00 ...
- GIS基础知识 - 坐标系、投影、EPSG:4326、EPSG:3857
最近接手一个GIS项目,需要用到 PostGIS,GeoServer,OpenLayers 等工具组件,遇到一堆地理信息相关的术语名词,在这里做一个总结. 1. 大地测量学 (Geodesy) 大地测 ...
- 矩阵快速幂 hud 1575 Tr A 模板 *
Tr A Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...