Python + opencv 实现图片文字的分割
实现步骤:
1、通过水平投影对图形进行水平分割,获取每一行的图像;
2、通过垂直投影对分割的每一行图像进行垂直分割,最终确定每一个字符的坐标位置,分割出每一个字符;
先简单介绍一下投影法:分别在水平和垂直方向对预处理(二值化)的图像某一种像素进行统计,对于二值化图像非黑即白,我们通过对其中的白点或者黑点进行统计,根据统计结果就可以判断出每一行的上下边界以及每一列的左右边界,从而实现分割的目的。
下面通过Python+opencv来实现该功能
首先来实现水平投影:
import cv2
import numpy as np '''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
#图像高与宽
(h,w)=image.shape
#长度与图像高度一致的数组
h_ = [0]*h
#循环统计每一行白色像素的个数
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
cv2.imshow('hProjection2',hProjection) return h_ if __name__ == "__main__":
#读入原始图像
origineImage = cv2.imread('test.jpg')
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
cv2.imshow('binary',img)
#水平投影
H = getHProjection(img)

通过上面的水平投影,根据其白色小山峰的起始位置就可以界定出每一行的起始位置,从而把每一行分割出来。

获得每一行图像之后,可以对其进行垂直投影
def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
#图像高与宽
(h,w) = image.shape
#长度与图像宽度一致的数组
w_ = [0]*w
#循环统计每一列白色像素的个数
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
#绘制垂直平投影图像
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
cv2.imshow('vProjection',vProjection)
return w_

通过垂直投影可以获得每一个字符左右的起始位置,这样也就可以获得到每一个字符的具体坐标位置,即一个矩形框的位置。
下面是实现的全部代码:
import cv2
import numpy as np '''水平投影'''
def getHProjection(image):
hProjection = np.zeros(image.shape,np.uint8)
#图像高与宽
(h,w)=image.shape
#长度与图像高度一致的数组
h_ = [0]*h
#循环统计每一行白色像素的个数
for y in range(h):
for x in range(w):
if image[y,x] == 255:
h_[y]+=1
#绘制水平投影图像
for y in range(h):
for x in range(h_[y]):
hProjection[y,x] = 255
cv2.imshow('hProjection2',hProjection) return h_ def getVProjection(image):
vProjection = np.zeros(image.shape,np.uint8);
#图像高与宽
(h,w) = image.shape
#长度与图像宽度一致的数组
w_ = [0]*w
#循环统计每一列白色像素的个数
for x in range(w):
for y in range(h):
if image[y,x] == 255:
w_[x]+=1
#绘制垂直平投影图像
for x in range(w):
for y in range(h-w_[x],h):
vProjection[y,x] = 255
#cv2.imshow('vProjection',vProjection)
return w_ if __name__ == "__main__":
#读入原始图像
origineImage = cv2.imread('test.jpg')
# 图像灰度化
#image = cv2.imread('test.jpg',0)
image = cv2.cvtColor(origineImage,cv2.COLOR_BGR2GRAY)
cv2.imshow('gray',image)
# 将图片二值化
retval, img = cv2.threshold(image,127,255,cv2.THRESH_BINARY_INV)
cv2.imshow('binary',img)
#图像高与宽
(h,w)=img.shape
Position = []
#水平投影
H = getHProjection(img) start = 0
H_Start = []
H_End = []
#根据水平投影获取垂直分割位置
for i in range(len(H)):
if H[i] > 0 and start ==0:
H_Start.append(i)
start = 1
if H[i] <= 0 and start == 1:
H_End.append(i)
start = 0
#分割行,分割之后再进行列分割并保存分割位置
for i in range(len(H_Start)):
#获取行图像
cropImg = img[H_Start[i]:H_End[i], 0:w]
#cv2.imshow('cropImg',cropImg)
#对行图像进行垂直投影
W = getVProjection(cropImg)
Wstart = 0
Wend = 0
W_Start = 0
W_End = 0
for j in range(len(W)):
if W[j] > 0 and Wstart ==0:
W_Start =j
Wstart = 1
Wend=0
if W[j] <= 0 and Wstart == 1:
W_End =j
Wstart = 0
Wend=1
if Wend == 1:
Position.append([W_Start,H_Start[i],W_End,H_End[i]])
Wend =0
#根据确定的位置分割字符
for m in range(len(Position)):
cv2.rectangle(origineImage, (Position[m][0],Position[m][1]), (Position[m][2],Position[m][3]), (0 ,229 ,238), 1)
cv2.imshow('image',origineImage)
cv2.waitKey(0)
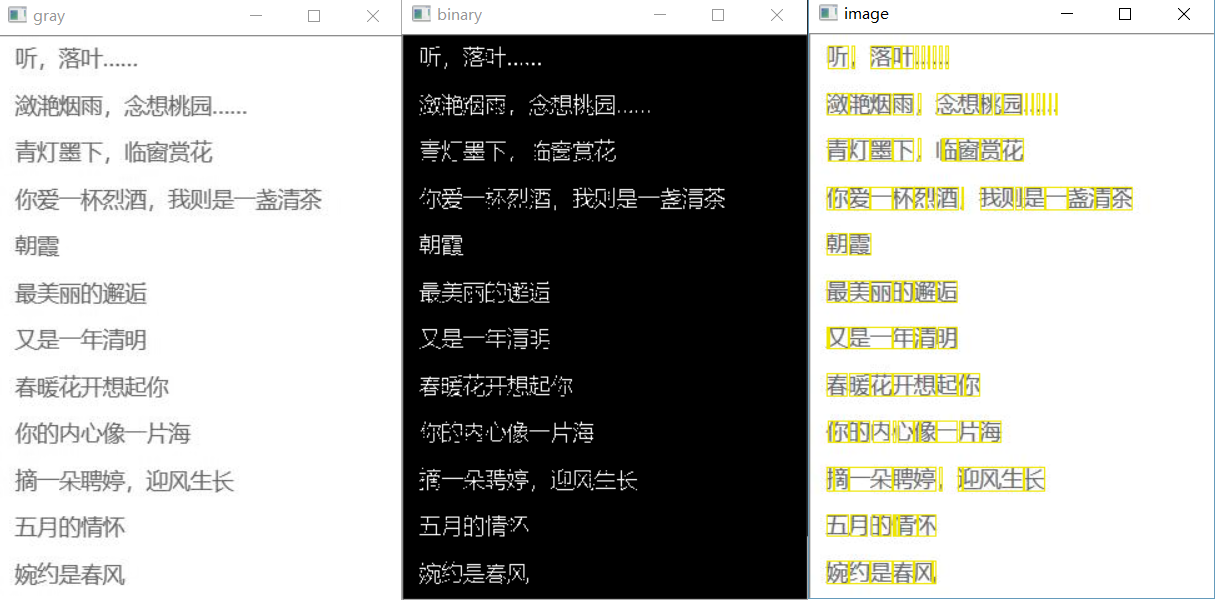
从分割的结果上看,基本上实现了图片中文字的分割。但由于中文结构复杂性,对于一些文字的分割并不理想,比如“叶”、“桃”等字会出现过度分割现象;对于有粘连的两个字会出现分割不够的现象,比如上图中的“念想”。不过可以从图像预处理(腐蚀),边界判断阈值的调整等方面进行优化。
Python + opencv 实现图片文字的分割的更多相关文章
- Python+OpenCV竖版古籍文字分割
在做图片文字分割的时候,常用的方法有两种.一种是投影法,适用于排版工整,字间距行间距比较宽裕的图像:还有一种是用OpenCV的轮廓检测,适用于文字不规则排列的图像. 1. 思路 一开始想偷个懒,直接用 ...
- python opencv show图片,debug技巧
debug的时候可以直接把图片画出来debug. imshow函数就是python opencv的展示图片的函数,第一个是你要起的图片名,第二个是图片本身.waitKey函数是用来展示图片多久的,默认 ...
- Python图像处理之图片文字识别(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同 ...
- python实现中文图片文字识别--OCR about chinese text--tesseract
0.我的环境: win7 32bits python 3.5 pycharm 5.0 1.相关库 安装pillow: pip install pillow 安装tesseract: tesseract ...
- python opencv 读取图片 返回图片某像素点的b,g,r值
转载:https://blog.csdn.net/weixin_41799483/article/details/80884682 #coding=utf-8 #读取图片 返回图片某像素点的b,g ...
- Python opencv resize图片并保存原有的图像比例
参考链接:https://www.jianshu.com/p/3092835eab61 现有的图像是高瘦高瘦的,所以直接resize成矩形不合适.改变了整个结构. 所以采用的是先resize再padd ...
- Python OpenCV 显示图片,图片分类
def divide_image(path,g_path1,g_path0): img_lst = os.listdir(path) for i in img_lst: print('类别1,类别0' ...
- 用 Python 和 OpenCV 检测图片上的条形码
用 Python 和 OpenCV 检测图片上的的条形码 这篇博文的目的是应用计算机视觉和图像处理技术,展示一个条形码检测的基本实现.我所实现的算法本质上基于StackOverflow 上的这个问 ...
- Python人工智能之图片识别,Python3一行代码实现图片文字识别
1.Python人工智能之图片识别,Python3一行代码实现图片文字识别 2.tesseract-ocr安装包和中文语言包 注意:
随机推荐
- 关于前端jsonp跨域和一个简单的node服务搭建
先讲下概念 同源策略:是一种约定,浏览器最核心最基本的安全功能,(同域名,同协议,同端口)为同源 跨域: 跨(跳):范围 域 (源):域名,协议,端口 域名:ip的一种昵称(为了更好记住ip地址)如: ...
- zookeeper学习之原理
一.zookeeper 是什么 Zookeeper是一个分布式协调服务,可用于服务发现,分布式锁,分布式领导选举,配置管理等.这一切的基础,都是Zookeeper提供了一个类似于Linux文件系统的树 ...
- CentOS搭建php + nginx环境
更新Centos的yum源 yum update 安装EPEL源和REMI源 yum install epel-release yum install http://rpms.remirepo.net ...
- css_transition_animation(内含贝赛尔曲线详解)
区别: transition也叫过渡动画,主要是用于让一个元素从一种状态过渡到另一种状态效果,常用于主动触发的效果.例如移动端的页面切换(很常用).button点击效果(也很常见). animatio ...
- Python连载35-死锁问题以及解决方式
一.死锁问题 例子 import threading import time lock_1 = threading.Lock() lock_2 = threading.Lock() def f ...
- js 取两位小数
var totalPrice = (product.unitPrice * product.nums).toFixed(2);
- asp net core mvc 跨域ajax解决方案
1.配置服务端 在Startup文件中国配置Cors策略: IEnumerable<Client> clients= Configuration.GetSection("Clie ...
- webpack多页面应用打包问题-新增页面打包JS影响旧有JS资源
webpack多页面应用打包问题:如果在项目里新增页面,pages目录中插入一个页面文件,然后打包代码,在webpack3中,新增页面文件上方文件打包出来的JS文件内容全部会改变,点击查看比对,发现问 ...
- 关于ASP.NET中WEBAPI中POST请求中FromBody修饰的string类型的参数服务器端获取不到值FromBody空值的简单解决方法
其实解决办法很简单,就是POST请求的时候,来自实体的参数,content-type:application/x-www-form-urlencoded情况下,是默认按照键值对来解析的,比如param ...
- Java日志框架总结
1. 前言 从写代码开始,就陆陆续续接触到了许多日志框架,较常用的属于LOG4J,LogBack等.每次自己写项目时,就copy前人的代码或网上的demo.配置log4j.properties或者lo ...