mysql group by 的用法解析
1. group by的常规用法
group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤。
- 聚合函数max
- select max(user_id),grade from user_info group by grade ;

这条sql的含义很明确,将数据按照grade字段分组,查询每组最大的user_id以及当前组内容。注意,这里分组条件是grade,查询的非聚合条件也是grade。这里不产生冲突。
having
select max(user_id),grade from user_info group by grade having grade>'A'
这条sql与上面例子中的基本相同,不过后面跟了having过滤条件。将grade不满足’>A’的过滤掉了。注意,这里分组条件是grade,查询的非聚合条件也是grade。这里不产生冲突。
2. group by的非常规用法
- select max(user_id),id,grade from user_info group by grade
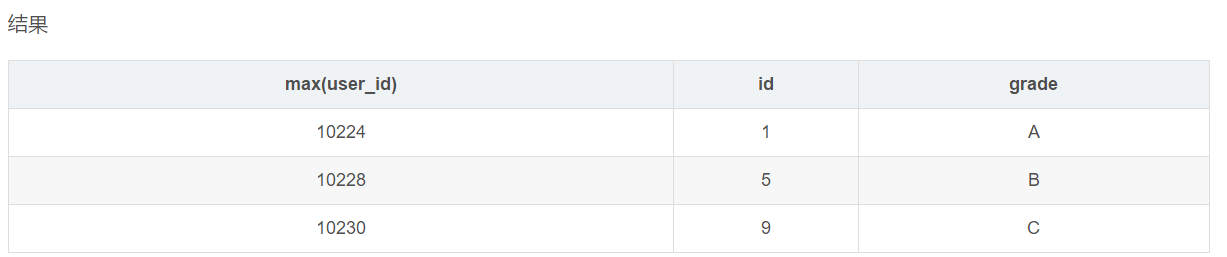
这条sql的结果就值得讨论了,与上述例子不同的是,查询条件多了id一列。数据按照grade分组后,grade一列是相同的,max(user_id)按照数据进行计算也是唯一的,id一列是如何取值的?看上述的数据结果,
推论:id是物理内存的第一个匹配项。
究竟是与不是需要继续探讨。修改数据
- 修改id按照上述数据结果,将id=1,改为id=99,执行sql后结论:

显然,与上述例子的结果不同。第一条数据id变成了99,查出的结果第一条数据的id从1变成了2。表明,id这个非聚合条件字段的取值与数据写入的时间无关,因为id=1的记录是先于id=2存在的,修改的数据不过是修改了这条数据的内容。结合mysql的数据存储理论,由于id是主键,所以数据在检索是是按照主键排序后进行过滤的,因此
推论:id字段的选取是按照mysql存储的检索数据匹配的第一条。
将id改为1后恢复了原始结果,无法推翻上述推论。
更改查询条件- select max(user_id),user_id,id,grade from user_info group by grade

将数据user_id改为10999后,执行结果为
结论
- 当group by 与聚合函数配合使用时,功能为分组后计算
- 当group by 与having配合使用时,功能为分组后过滤
- 当group by 与聚合函数,同时非聚合字段同时使用时,非聚合字段的取值是第一个匹配到的字段内容,即id小的条目对应的字段内容。
mysql group by 的用法解析的更多相关文章
- mysql中group by 的用法解析
1. group by的常规用法 group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤. 假设现有数据库表如下 ...
- mysql group by的用法 注意
group by 用法: 官方的解释:select 后面的字段必须出现在 group by 后面, 除非是聚合,sum,或者count 但是如果 是多表联查, SELECT c.`name` A ...
- mysql中limit的用法实例解析
mysql中limit的用法解析. 在mysql中,select * from table limit m,n.其中m是指记录开始的index,从0开始,n是指从第m条开始,取n条. 例如: mysq ...
- mysql group by 用法解析(详细)
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供 有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的 ...
- (转载)mysql group by 用法解析(详细)
(转载)http://blog.tianya.cn/blogger/post_read.asp?BlogID=4221189&PostID=47881614 mysql distinct 去重 ...
- 转:mysql group by 用法解析(详细)
group by 用法解析 group by语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表. SELECT子句中的列名必须为分组列或列函数.列函数对于GROUP BY子 ...
- group by 用法解析
group by 用法解析 group by语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表. SELECT子句中的列名必须为分组列或列函数.列函数对于GROUP BY子 ...
- sql中的group by 和 having 用法解析
转载博客:http://www.cnblogs.com/wang-123/archive/2012/01/05/2312676.html --sql中的group by 用法解析:-- Group B ...
- sql中group by 和having 用法解析
--sql中的group by 用法解析:-- Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”.--它的作用是通过一定的规则将一个数据集划分成若干个小的 ...
随机推荐
- 设计模式-Adapter(结构型模式)针对第三方库 函数 接口不匹配的问题,分为类模式 与 对象模式 两种
以下代码来源: 设计模式精解-GoF 23种设计模式解析附C++实现源码 //****************************类模式的Adaptr*********************** ...
- Mybatis智能标签
一.ProviderDao层 //智能标签案例 //智能标签多条件查询 public List<Provider> providerTest(@Param("proCode&qu ...
- manage.py相关命令
python manage.py makemigrations <app_name> 在对应app下的migrations目录下,生成XXXX_initial.py文件,该XXXX_ini ...
- 《细说PHP》第四版 样章 第18章 数据库抽象层PDO 10
18.8 设计完美分页类 数据记录列表几乎出现在Web项目的每个模块中,假设一张表中有十几万条记录,我们不可能一次全都显示出来,当然也不能仅显示几十条.为了解决这样的矛盾,通常在读取时设置以分页的形 ...
- 错误InnoDB:Attemptedtoopenapreviouslyopenedtablespace.
2013-08-04 13:48:22 760 [ERROR] InnoDB: Attempted to open a previously opened tablespace. Previous t ...
- 定时任务之SpringSchedule的注意事项
在我们现在的项目中,或多或少的都会涉及到定时任务,Spring在3.0之后引入了SpringSchedule,这让我们在使用Spring的时候,可以很容易的整合SpringSchedule.但是好用归 ...
- MongoDB for OPS 03:分片 shard 集群
写在前面的话 上一节的复制集也就是主从能够解决我们高可用和数据安全性问题,但是无法解决我们的性能瓶颈问题.所以针对性能瓶颈,我们需要采用分布式架构,也就是分片集群,sharding cluster! ...
- Razor_06 列表的查询
Razor_06 列表的查询 列表的查询 同步/AJAX 查询 分局部视图[强类型] system.text.Json Ajax 返回 Json 数据 , System.Text.Json .循环引 ...
- Python GUI开发,效率提升10倍的方法!
1 框架简介 这个框架的名字叫 PySimpleGUI,它完全基于Python语言,能非常方便地开发GUI界面,代码量相比现有框架减少50%到90%.并且,它提供了极为友好的Python风格的接口,大 ...
- C#中对文件进行选择对话框打开和保存对话框进行复制
场景 通过文件选择对话框选择文件 复制文件到指定路径 注: 博客主页: https://blog.csdn.net/badao_liumang_qizhi 关注公众号霸道的程序猿获取编程相关电子书.教 ...