mysql group by 的用法解析
1. group by的常规用法
group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤。
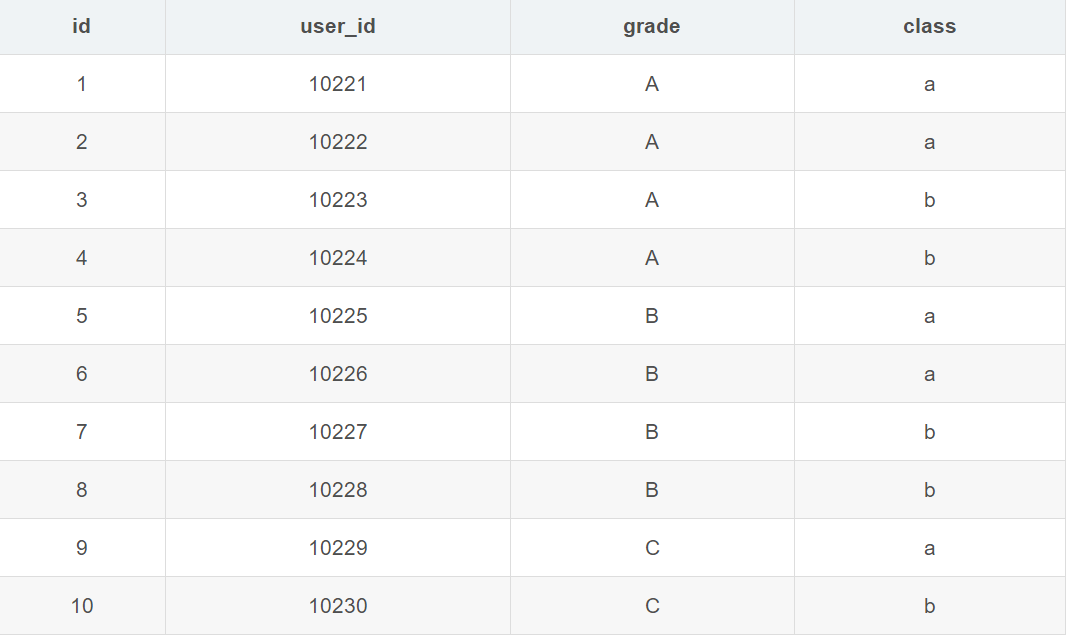
- 聚合函数max
- select max(user_id),grade from user_info group by grade ;

这条sql的含义很明确,将数据按照grade字段分组,查询每组最大的user_id以及当前组内容。注意,这里分组条件是grade,查询的非聚合条件也是grade。这里不产生冲突。
having
select max(user_id),grade from user_info group by grade having grade>'A'
这条sql与上面例子中的基本相同,不过后面跟了having过滤条件。将grade不满足’>A’的过滤掉了。注意,这里分组条件是grade,查询的非聚合条件也是grade。这里不产生冲突。
2. group by的非常规用法
- select max(user_id),id,grade from user_info group by grade
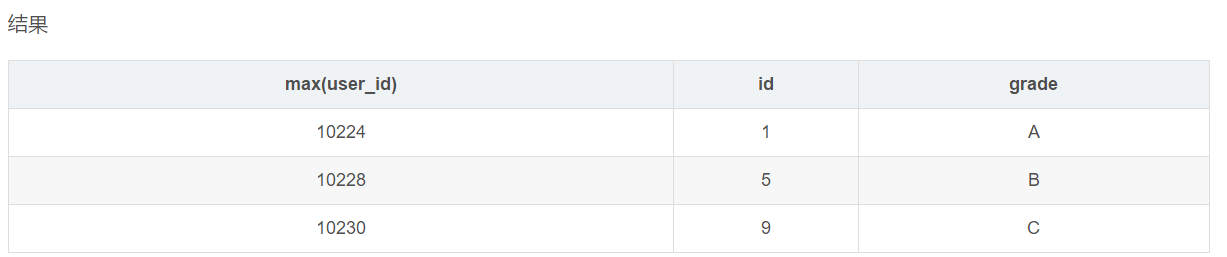
这条sql的结果就值得讨论了,与上述例子不同的是,查询条件多了id一列。数据按照grade分组后,grade一列是相同的,max(user_id)按照数据进行计算也是唯一的,id一列是如何取值的?看上述的数据结果,
推论:id是物理内存的第一个匹配项。
究竟是与不是需要继续探讨。修改数据
- 修改id按照上述数据结果,将id=1,改为id=99,执行sql后结论:

显然,与上述例子的结果不同。第一条数据id变成了99,查出的结果第一条数据的id从1变成了2。表明,id这个非聚合条件字段的取值与数据写入的时间无关,因为id=1的记录是先于id=2存在的,修改的数据不过是修改了这条数据的内容。结合mysql的数据存储理论,由于id是主键,所以数据在检索是是按照主键排序后进行过滤的,因此
推论:id字段的选取是按照mysql存储的检索数据匹配的第一条。
将id改为1后恢复了原始结果,无法推翻上述推论。
更改查询条件- select max(user_id),user_id,id,grade from user_info group by grade

将数据user_id改为10999后,执行结果为
结论
- 当group by 与聚合函数配合使用时,功能为分组后计算
- 当group by 与having配合使用时,功能为分组后过滤
- 当group by 与聚合函数,同时非聚合字段同时使用时,非聚合字段的取值是第一个匹配到的字段内容,即id小的条目对应的字段内容。
mysql group by 的用法解析的更多相关文章
- mysql中group by 的用法解析
1. group by的常规用法 group by的常规用法是配合聚合函数,利用分组信息进行统计,常见的是配合max等聚合函数筛选数据后分析,以及配合having进行筛选后过滤. 假设现有数据库表如下 ...
- mysql group by的用法 注意
group by 用法: 官方的解释:select 后面的字段必须出现在 group by 后面, 除非是聚合,sum,或者count 但是如果 是多表联查, SELECT c.`name` A ...
- mysql中limit的用法实例解析
mysql中limit的用法解析. 在mysql中,select * from table limit m,n.其中m是指记录开始的index,从0开始,n是指从第m条开始,取n条. 例如: mysq ...
- mysql group by 用法解析(详细)
在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供 有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重记录的 ...
- (转载)mysql group by 用法解析(详细)
(转载)http://blog.tianya.cn/blogger/post_read.asp?BlogID=4221189&PostID=47881614 mysql distinct 去重 ...
- 转:mysql group by 用法解析(详细)
group by 用法解析 group by语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表. SELECT子句中的列名必须为分组列或列函数.列函数对于GROUP BY子 ...
- group by 用法解析
group by 用法解析 group by语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表. SELECT子句中的列名必须为分组列或列函数.列函数对于GROUP BY子 ...
- sql中的group by 和 having 用法解析
转载博客:http://www.cnblogs.com/wang-123/archive/2012/01/05/2312676.html --sql中的group by 用法解析:-- Group B ...
- sql中group by 和having 用法解析
--sql中的group by 用法解析:-- Group By语句从英文的字面意义上理解就是“根据(by)一定的规则进行分组(Group)”.--它的作用是通过一定的规则将一个数据集划分成若干个小的 ...
随机推荐
- 【CodeForces】CodeForcesRound594 Div1 解题报告
点此进入比赛 \(A\):Ivan the Fool and the Probability Theory(点此看题面) 大致题意: 给一个\(n\times m\)的矩阵\(01\)染色,使得不存在 ...
- golang--redis基本介绍
redis(remote-dictionary-system)即远程字典服务器,是NoSQL数据库: 适合做缓存以及持久化: 免费开源,高性能的分布式内存数据库: redis的安装和使用: 下载Red ...
- UTF-8和BOM的一些说明
BOM的含义 BOM即Byte Order Mark字节序标记.BOM是为UTF-16和UTF-32准备的,用户标记字节序(byte order).拿UTF-16来举例,其是以两个字节为编码单元,在解 ...
- 最全各种系统版本的XPosed框架资料下载整理
由于XPosed在不同安卓系统版本中对应的版本不同,给很多新手造成极大困扰,本文作者经过几番努力,给大家整理了各个版本对应的xposed框架版本以及相关资料,并附上相关下载链接,希望对大伙有所帮助. ...
- HttpClient 如何设置超时时间
今天分享一个巨坑,就是 HttpClient.这玩意有多坑呢?就是每个版本都变,近日笔者深受其害. 先看一下代码,我要发送请求调用一个c++接口. public static String doPos ...
- Netty — 心跳检测和断线重连
一.前言 由于在通信层的网络连接的不可靠性,比如:网络闪断,网络抖动等,经常会出现连接断开.这样对于使用长连接的应用而言,当突然高流量冲击势必会造成进行网络连接,从而产生网络堵塞,应用响应速度下降,延 ...
- ZooKeeper(二):多个端口监听的建立逻辑解析
ZooKeeper 作为优秀的分布系统协调组件,值得一探究竟.它的启动类主要为: 1. 单机版的zk 使用 ZooKeeperServerMain 2. 集群版的zk 使用 QuorumPeerMai ...
- python爬虫:将数据保存到本地
一.python语句存储 1.with open()语句 with open(name,mode,encoding) as file: file.write() name:包含文件名称的字符串; mo ...
- java高并发系列 - 第11天:线程中断的几种方式
java高并发系列第11篇文章. 本文主要探讨一下中断线程的几种方式. 通过一个变量控制线程中断 代码: package com.itsoku.chat05; import java.util.con ...
- python基础(28):isinstance、issubclass、type、反射
1. isinstance和issubclass 1.1 isinstance isinstance(obj,cls)检查是否obj是否是类 cls 的对象 class Foo(object): pa ...