Googleplaystore数据分析
本次所用到的数据分析工具:numpy、pandas、matplotlib、seaborn
一、分析目的
假如接下来需要开发一款APP,想了解开发什么类型的APP会更受欢迎,此次分析可以对下一步计划进行指导。
二、分析维度
本次只对以下八个维度进行分析:
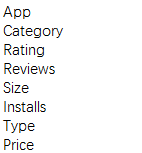
三、数据处理
1、数据介绍
googleplaystore:谷歌应用商店App相关信息
导入数据:
#导入分析包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('./googleplaystore.csv', usecols=(0, 1, 2, 3, 4, 5, 6))
#简单浏览下数据
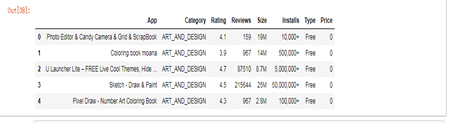
df.head()
#查看行列数量
df.shape
数据量:10841*8
数据概览:
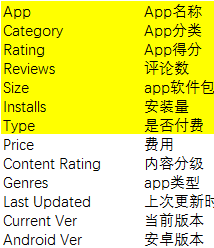
2、列名称理解:
3、数据清洗
# 查看各个列的非空数据量
df.count()
App 10841
Category 10841
Rating 9367
Reviews 10841
Size 10841
Installs 10841
Type 10840
Price 10841
dtype: int64 总共有10481条记录,可以看出Rating有很多null值。
清洗数据:
#App列:查看是否有重复值
pd.unique(df['App']).size
有9660条唯一值记录,重复值占总记录大概10%,为了不留下其他列的异常值,将需要删除的重复记录放在后面处理。
# Category列:
df['Category'].value_counts(dropna=False)
FAMILY 1972
GAME 1144
TOOLS 843
MEDICAL 463
BUSINESS 460
PRODUCTIVITY 424
PERSONALIZATION 392
COMMUNICATION 387
SPORTS 384
LIFESTYLE 382
FINANCE 366
HEALTH_AND_FITNESS 341
PHOTOGRAPHY 335
SOCIAL 295
NEWS_AND_MAGAZINES 283
SHOPPING 260
TRAVEL_AND_LOCAL 258
DATING 234
BOOKS_AND_REFERENCE 231
VIDEO_PLAYERS 175
EDUCATION 156
ENTERTAINMENT 149
MAPS_AND_NAVIGATION 137
FOOD_AND_DRINK 127
HOUSE_AND_HOME 88
LIBRARIES_AND_DEMO 85
AUTO_AND_VEHICLES 85
WEATHER 82
ART_AND_DESIGN 65
EVENTS 64
PARENTING 60
COMICS 60
BEAUTY 53
1.9 1
Name: Category, dtype: int64
这里的类别名称为1.9的明显是异常值,查看一下该条异常记录
df[df['Category'] == '1.9']

猜测是在处理数据是出现了错位的情况。
# 删除该条记录
df.drop(index=10472,inplace=True)
# rating列
df['Rating'].value_counts(dropna=False)
# 有1474条NaN值
# 用平均值填充
df['Rating'].fillna(value=df['Rating'].mean(),inplace=True)
# reviews列
df['Reviews'].value_counts(dropna=False)
# 查看是否有非数值型数据
df['Reviews'].str.isnumeric().sum()
#将Reviews转化为int型
df['Reviews'] = df['Reviews'].astype('i8')
由于前面删除了一条数据,现在总共有10840条数值型数据
# size列
df['Size'].value_counts(dropna=False)
以下是部分数据:
Varies with device 1695
11M 198
12M 196
14M 194
13M 191
15M 184
17M 160
19M 154
16M 149
26M 149
25M 143
20M 139
21M 138
10M 136
24M 136
18M 133
23M 117
# 将size替换成科学计数法以便于进一步分析
df['Size']=df['Size'].str.replace('M','e+6')
df['Size']=df['Size'].str.replace('k','e+3')
df['Size'].value_counts(dropna=False)
Varies with device 1695
11e+6 198
12e+6 196
14e+6 194
13e+6 191
15e+6 184
17e+6 160
19e+6 154
16e+6 149
26e+6 149
25e+6 143
20e+6 139
21e+6 138
24e+6 136
10e+6 136
18e+6 133
23e+6 117
22e+6 114
这时可以发现第一条记录不太符合要求,这时将该字符串用0代替,再将此替换为平均值(当然具体业务环境需要具体分析出现该情况的原因)
df['Size'] = df['Size'].str.replace('Varies with device', '0')
此时还需要进一步将Size列转换为int类型,以便于接下来的计算
df['Size'] = df['Size'].astype('f8').astype('i8')
0 1695
11000000 198
12000000 196
14000000 194
13000000 191
15000000 184
17000000 160
19000000 154
16000000 149
26000000 149
10000000 146
25000000 143
20000000 139
21000000 138
24000000 136
18000000 133
23000000 117
这里将Size为0的数据填充为平均值(这里合理的方法是将0以外的数据进行平均值处理)
df['Size'].replace(0, df[df['Size']!=0].Size.mean(), inplace=True)
21516529 1695
11000000 198
12000000 196
14000000 194
13000000 191
15000000 184
17000000 160
19000000 154
16000000 149
26000000 149
10000000 146
25000000 143
20000000 139
21000000 138
24000000 136
18000000 133
23000000 117
22000000 114
29000000 103
27000000 97
#查看分布
df.describe()

#Installs列
df['Installs'].value_counts()
1,000,000+ 1579
10,000,000+ 1252
100,000+ 1169
10,000+ 1054
1,000+ 907
5,000,000+ 752
100+ 719
500,000+ 539
50,000+ 479
5,000+ 477
100,000,000+ 409
10+ 386
500+ 330
50,000,000+ 289
50+ 205
5+ 82
500,000,000+ 72
1+ 67
1,000,000,000+ 58
0+ 14
0 1
Name: Installs, dtype: int64
将‘,’和‘+’进行替换,并转换为int类型
df['Installs'] = df['Installs'].str.replace('+', '')
df['Installs'] = df['Installs'].str.replace(',', '')
# 转换
df['Installs'] = df['Installs'].astype('i8')
转换后如下所示:
1000000 1579
10000000 1252
100000 1169
10000 1054
1000 907
5000000 752
100 719
500000 539
50000 479
5000 477
100000000 409
10 386
500 330
50000000 289
50 205
5 82
500000000 72
1 67
1000000000 58
0 15
Name: Installs, dtype: int64
#Type列:
df.info()
App 10840 non-null object
Category 10840 non-null object
Rating 10840 non-null float64
Reviews 10840 non-null int64
Size 10840 non-null int64
Installs 10840 non-null int64
Type 10839 non-null object
Price 10840 non-null object
Type列有一条na值,找出该记录,并删除:
df['Type'].value_counts(dropna=False)
df[df['Type'].isnull()]
df.drop(index=9148, inplace=True)
#Price列:
df['Price'].value_counts(dropna=False)
该列未出现异常值。
#删除App重复记录
df.drop_duplicates('App',inplace=True)
df.count()
App 9658
Category 9658
Rating 9658
Reviews 9658
Size 9658
Installs 9658
Type 9658
Price 9658
dtype: int64
清洗后的数据量为:9658*8
四、数据分析
从Category角度:
查看有多少个类别,以及哪些类别更受开发者欢迎;
pd.unique(df['Category']).size
# 总共有33个类别
group_by_category=df.groupby('Category')[['App']].count().sort_values('App',ascending=False)
group_by_category.rename(columns={'App':'App_count'},inplace=True)
group_by_category.index.values
f,axes=plt.subplots(figsize=(10,8))
sns.barplot(x=group_by_category['App_count'],y=group_by_category.index)
plt.show()

从上以上条形图可以看出娱乐、家庭以及工具类App最受开发者欢迎。
根据每个Category的平均安装量进行排序,观察哪些类别更受用户青睐:
df.groupby('Category').mean().sort_values('Installs', ascending=False)
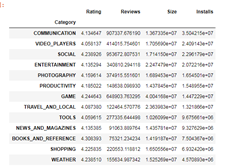
可以看出,娱乐社交类更受用户欢迎。
根据每个Category的评论进行排序,观察哪些类别评论更多:
df.groupby('Category').mean().sort_values('Reviews', ascending=False)

社交、游戏、视频类评论较多。
根据评分进行排序:是否与用户需求程度一致?
df.groupby('Category').mean().sort_values('Rating', ascending=False)
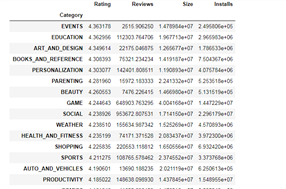
该结果明显和上述分析结果不一致,可能的原因是那些安装量更多的App用户体验感反而不太强,但这些又是用户离不开的产品,
还有可能是某一类别的部分评分低而拉低的平均评分,总之,开发者在开发新产品时需要注意用户体验感的满足,这样才会有更高的用
户黏性,因为一旦用户体验感不好,他们就会想办法找其他产品来代替。
从Type角度:
df.groupby('Type').count()

很明显,免费产品依然占主流啦,毕竟人都还是喜欢占便宜嘛,能用免费的就尽量不用收费的,不过从用户角度来看,如果产品让我特
别满意的情况下,还是很乐意使用收费产品的!
从Price角度:
df.groupby('Price').count().sort_values('App',ascending=False).head(10)
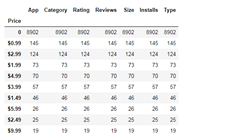
从该角度可以发现,其实开发者开发较多的也是免费产品,只有少数需要收费,而且收费越高的数量越少,这也刚好符合用户需求。
根据每个Category的平均Size进行排序:
df.groupby('Category').mean().sort_values('Size')
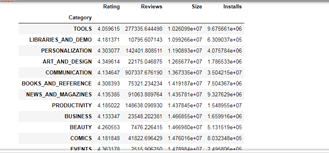
可以看到,工具类的安装内存是最小的,这可能是因为工具是人们需要经常使用的,因此希望装的小一些。
五、结论
通过对Googleplaystore相关数据的初步分析,可以看出用户需求量最大的是社交、娱乐等产品,免费产品依然占据主流地位。
另外,就是建议开发者开发一些主流产品时要特别注意用户体验,目前各种同类型的产品很多,增强用户体验是提升竞争力的
一个很重要的方式;最后,对于工具类产品,在保证质量的前提下,要尽量开发安装内存小的产品。
Googleplaystore数据分析的更多相关文章
- 利用Python进行数据分析 基础系列随笔汇总
一共 15 篇随笔,主要是为了记录数据分析过程中的一些小 demo,分享给其他需要的网友,更为了方便以后自己查看,15 篇随笔,每篇内容基本都是以一句说明加一段代码的方式, 保持简单小巧,看起来也清晰 ...
- 利用Python进行数据分析(10) pandas基础: 处理缺失数据
数据不完整在数据分析的过程中很常见. pandas使用浮点值NaN表示浮点和非浮点数组里的缺失数据. pandas使用isnull()和notnull()函数来判断缺失情况. 对于缺失数据一般处理 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- 利用Python进行数据分析(4) NumPy基础: ndarray简单介绍
一.NumPy 是什么 NumPy 是 Python 科学计算的基础包,它专为进行严格的数字处理而产生.在之前的随笔里已有更加详细的介绍,这里不再赘述. 利用 Python 进行数据分析(一)简单介绍 ...
- 利用Python进行数据分析(3) 使用IPython提高开发效率
一.IPython 简介 IPython 是一个交互式的 Python 解释器,而且它更加高效. 它和大多传统工作模式(编辑 -> 编译 -> 运行)不同的是, 它采用的工作模式是:执 ...
随机推荐
- 201871010119-帖佼佼《面向对象程序设计(java)》第二周学习总结
项目 内容 这个作业属于哪个课程 <任课教师博客主页链接> https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 <作业链接地址> ...
- centos7 启动停止命令
apache启动systemctl start httpd停止systemctl stop httpd重启systemctl restart httpd mysql启动systemctl start ...
- CSS | 自适应两栏布局方法
html代码: <div class="main"> <div class="left" style="background: #0 ...
- Fragment中不能使用自定义带参构造函数
通过Fragment自定义的静态方法将值从activity传到fragment中,然后就想到这样不是多次一举吗,为什么不直接写个带参构造函数将值传过去呢?试了一下,发现Fragment有参构造函数竟然 ...
- Mysql被黑客入侵及安全措施总结
情况概述 今天登陆在腾讯云服务器上搭建的 MySQL 数据库,发现数据库被黑了,黑客提示十分明显. MySQL 中只剩下两个数据库,一个是information_schema,另一个是黑客创建的PLE ...
- DG重启之后主备数据不同步
问题描述:本来配置好的DG第二天重启之后,发现主备库数据不能同步,在主库上执行日志切换以及创建表操作都传不到备库上,造成这种错误的原因是主库实例断掉后造成备库日志与主库无法实时接收 主库:orcl ...
- 安装SDK 6.0(二)
2==>安装SDK 6.0 打开安卓Android Studio 出现 Unable to access Android SDK add-on list 点击 Cancal 在点击Cancel ...
- Elasticsearch系列---初识Elasticsearch
Elasticsearch是什么? Elasticsearch简称ES,是一个基于Lucene构建的开源.分布式.Restful接口的全文搜索引擎,还是一个分布式文档数据库.天生就是分布式.高可用.可 ...
- Spring Boot 2.X(十三):邮件服务
前言 邮件服务在开发中非常常见,比如用邮件注册账号.邮件作为找回密码的途径.用于订阅内容定期邮件推送等等,下面就简单的介绍下邮件实现方式. 准备 一个用于发送的邮箱,本文是用腾讯的域名邮箱,可以自己搞 ...
- 3.java基础之关键字instanceof
1. instanceof 使用:对象引用名 instanceof 类名 作用:来判读引用的对象和类名是否兼容(是否继承该类,或爷爷辈的类) 例子: Team team = new Team(); t ...