基于SpringCloud实现Shard-Jdbc的分库分表模式,数据库扩容方案
本文源码:GitHub·点这里 || GitEE·点这里
一、项目结构
1、工程结构

2、模块命名
shard-common-entity: 公共代码块
shard-open-inte: 开放接口管理
shard-eureka-7001: 注册中心
shard-two-provider-8001: 8001 基于两台库的服务
shard-three-provider-8002:8002 基于三台库的服务
3、代码依赖结构
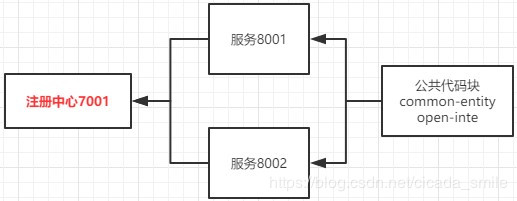
4、项目启动顺序
(1)shard-eureka-7001: 注册中心
(2)shard-two-provider-8001: 8001 基于两台库的服务
(3)shard-three-provider-8002:8002 基于三台库的服务
按照顺序启动,且等一个服务完全启动后,在启动下一个服务,不然可能遇到一些坑。
二、核心代码块
1、8001 服务提供一个对外服务
基于Feign的调用方式
作用:基于两台分库分表的数据查询接口。
import org.springframework.cloud.netflix.feign.FeignClient;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import shard.jdbc.common.entity.TableOne;
/**
* shard-two-provider-8001
* 对外开放接口
*/
@FeignClient(value = "shard-provider-8001")
public interface TwoOpenService {
@RequestMapping("/selectOneByPhone/{phone}")
TableOne selectOneByPhone(@PathVariable("phone") String phone) ;
}
2、8002 服务提供一个对外服务
基于Feign的调用方式
作用:基于三台分库分表的数据存储接口。
import org.springframework.cloud.netflix.feign.FeignClient;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import shard.jdbc.common.entity.TableOne;
/**
* 数据迁移服务接口
*/
@FeignClient(value = "shard-provider-8002")
public interface MoveDataService {
@RequestMapping("/moveData")
Integer moveData (@RequestBody TableOne tableOne) ;
}
3、基于8002服务数据查询接口
查询流程图
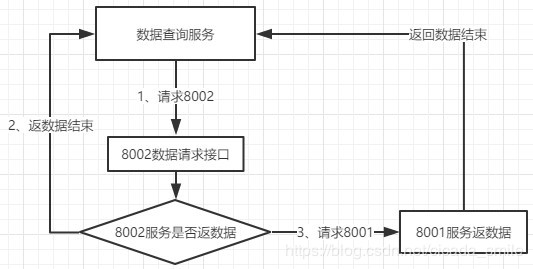
代码块
/**
* 8001 端口 :基于两台分库分表策略的数据查询接口
*/
@Resource
private TwoOpenService twoOpenService ;
@Override
public TableOne selectOneByPhone(String phone) {
TableOne tableOne = tableOneMapper.selectOneByPhone(phone);
if (tableOne != null){
LOG.info("8002 === >> tableOne :"+tableOne);
}
// 8002 服务没有查到数据
if (tableOne == null){
// 调用 8001 开放的查询接口
tableOne = twoOpenService.selectOneByPhone(phone) ;
LOG.info("8001 === >> tableOne :"+tableOne);
}
return tableOne ;
}
4、基于 8001 数据扫描迁移代码
迁移流程图
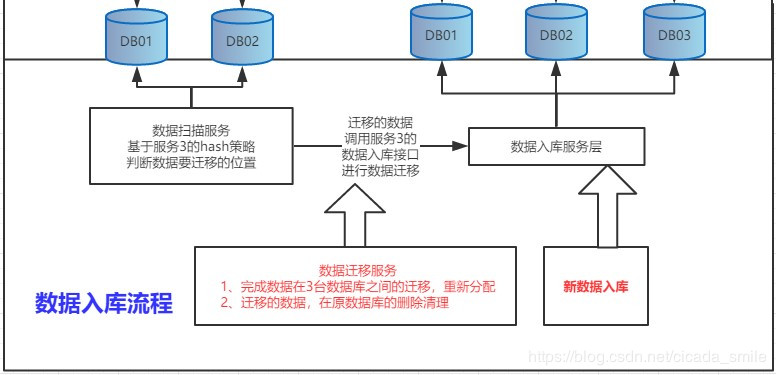
代码块
/**
* 8002 端口开放的数据入库接口
*/
@Resource
private MoveDataService moveDataService ;
/**
* 扫描,并迁移数据
* 以 库 db_2 的 table_one_1 表为例
*/
@Override
public void scanDataRun() {
String sql = "SELECT id,phone,back_one backOne,back_two backTwo,back_three backThree FROM table_one_1" ;
// dataTwoTemplate 对应的数据库:ds_2
List<TableOne> tableOneList = dataTwoTemplate.query(sql,new Object[]{},new BeanPropertyRowMapper<>(TableOne.class)) ;
if (tableOneList != null && tableOneList.size()>0){
int i = 0 ;
for (TableOne tableOne : tableOneList) {
String db_num = HashUtil.moveDb(tableOne.getPhone()) ;
String tb_num = HashUtil.moveTable(tableOne.getPhone()) ;
// 只演示向数据新加库 ds_4 迁移的数据
if (db_num.equals("ds_4")){
i += 1 ;
LOG.info("迁移总数数=>" + i + "=>库位置=>"+db_num+"=>表位置=>"+tb_num+"=>数据:【"+tableOne+"】");
// 扫描完成:执行新库迁移和旧库清理过程
moveDataService.moveData(tableOne) ;
// dataTwoTemplate.update("DELETE FROM table_one_1 WHERE id=? AND phone=?",tableOne.getId(),tableOne.getPhone());
}
}
}
}
三、演示执行流程
1、项目流程图

2、测试执行流程
(1)、访问8002 数据查询端口
http://127.0.0.1:8002/selectOneByPhone/phone20
日志输出:
8001 服务查询到数据
8001 === >> tableOne :+{tableOne}
(2)、执行8001 数据扫描迁移
http://127.0.0.1:8001/scanData
(3)、再次访问8002 数据查询端口
http://127.0.0.1:8002/selectOneByPhone/phone20
日志输出:
8002 服务查询到数据
8002 === >> tableOne :+{tableOne}
四、源代码地址
GitHub·地址
https://github.com/cicadasmile/spring-cloud-base
GitEE·地址
https://gitee.com/cicadasmile/spring-cloud-base

基于SpringCloud实现Shard-Jdbc的分库分表模式,数据库扩容方案的更多相关文章
- 架构组件:基于Shard-Jdbc分库分表,数据库扩容方案
本文源码:GitHub·点这里 || GitEE·点这里 一.数据库扩容 1.业务场景 互联网项目中有很多"数据量大,业务复杂度高,需要分库分表"的业务场景. 这样分层的架构 (1 ...
- MySQL 分库分表及其平滑扩容方案
转自:https://kefeng.wang/2018/07/22/mysql-sharding/ 众所周知,数据库很容易成为应用系统的瓶颈.单机数据库的资源和处理能力有限,在高并发的分布式系统中,可 ...
- (二)基于shard-jdbc中间件,实现数据分库分表
基于shard-jdbc中间件,实现数据分库分表 Sharding-JDBC简介 Sharding配置示意图 1.水平分割 1.1 水平分库 1.2 水平分表 2.Shard-jdbc中间件 2.1 ...
- 带你剖析淘宝TDDL——Matrix层的分库分表配置与实现
前言 在开始讲解淘宝的TDDL(Taobao Distribute Data Layer)技术之前,请允许笔者先吐槽一番.首先要开喷的是淘宝的社区支持做的无比的烂,TaoCode开源社区上面,几乎从来 ...
- 使用TiDB把自己写分库分表方案推翻了
背景 在日益数据量增长的情况下,影响数据库的读写性能,我们一般会有分库分表的方案和使用newSql方案,newSql如TIDB.那么为什么需要使用TiDB呢?有什么情况下才用TiDB呢?解决传统分库分 ...
- 一文快速入门分库分表中间件 Sharding-JDBC (必修课)
书接上文 <一文快速入门分库分表(必修课)>,这篇拖了好长的时间,本来计划在一周前就该写完的,结果家庭内部突然人事调整,领导层进行权利交接,随之宣布我正式当爹,紧接着家庭地位滑落至第三名, ...
- 分库分表神器 Sharding-JDBC,几千万的数据你不搞一下?
今天我们介绍一下 Sharding-JDBC框架和快速的搭建一个分库分表案例,为讲解后续功能点准备好环境. 一.Sharding-JDBC 简介 Sharding-JDBC 最早是当当网内部使用的一款 ...
- 分库分表 or NewSQL数据库?终于看懂应该怎么选!【转】
最近与同行科技交流,经常被问到分库分表与分布式数据库如何选择,网上也有很多关于中间件+传统关系数据库(分库分表)与NewSQL分布式数据库的文章,但有些观点与判断是我觉得是偏激的,脱离环境去评价方案好 ...
- Mysql之Mycat读写分离及分库分表
## 什么是mycat ```basic 1.一个彻底开源的,面向企业应用开发的大数据库集群 2.支持事务.ACID.可以替代MySQL的加强版数据库 3.一个可以视为MySQL集群的企业级数据库,用 ...
随机推荐
- ORACLE存储过程详解
1.定义 所谓存储过程(Stored Procedure),就是一组用于完成特定数据库功能的SQL语句集,该SQL语句集经过编译后存储在数据库系统中.在使用时候,用户通过指定已经定义的存储过程名字并给 ...
- js方法中参数传过来的值包含括号
前提,传递的id为变量值,比如从后台获取数据循环,在每个循环里调用shenpi()方法,假设传的id包含括号,例如 20190329100833(更正) 这样的数据,那么直接调用会报错,控制台会报错: ...
- CCF-CSP题解 201809-3 元素选择器
题目要求写一个简易的CSS Selector. 首先用结构体\(<lev,label[],hasId,id[]>\)存储元素.其中\(lev\)表示元素在html树中的深度(这个是因为逻辑 ...
- highreport报表工具功能介绍
目前国产报表工具大部分都是Java版本,例如润乾和帆软,而C#写的报表工具国内还没有,介绍一款VS2010(C#)写的国产报表工具(highreport),采用类Excel设计,零代码实现复杂报表展示 ...
- Linux下修改MySQL数据库数据文件路径
使用rpm安装方式安装完MySQL数据库后,数据文件的默认路径为/var/lib/mysql,然而根目录并不适合用于存储数据文件. 原路径:/var/lib/mysql 目标路径:/home/mysq ...
- 元类, pymysql
元类, pymysql 一.元类 自定义元类 ''' 1.什么是元类? - 类的类就是type,其实type就是元类 2.元类的作用? 3.如何创建元类以及使用? ''' # # 1.一切皆对象 # ...
- How we implemented consistent hashing efficiently
原文链接https://medium.com/ably-realtime/how-to-implement-consistent-hashing-efficiently-fe038d59fff2 我们 ...
- Graylog 笔记
安装 基本上有3种方式,1 yum安装2 rpm安装3 docker安装 yum安装 yum安装,参照官方文档是最好的:http://docs.graylog.org/en/3.0/pages/ins ...
- Fabric-Ca使用
Fabric-Ca的概念不再解释了,这里只说明使用方法: 前置条件 Go语言1.10+版本 GOPATH环境变量正确设置 已安装libtool和libtdhl-dev包 Ubuntu系统 通过以下命令 ...
- 分布式图数据库 Nebula RC2 发布:增强了 CSV Importer 功能
Nebula Graph 是开源的分布式图数据库,可应用于知识图谱.社交推荐.风控.IoT 等场景. 本次 RC2 主要新增 GO FROM ... REVERSELY 和 GROUP BY 等语句, ...