15、Work原理及源码分析
一、Work原理
1、图解
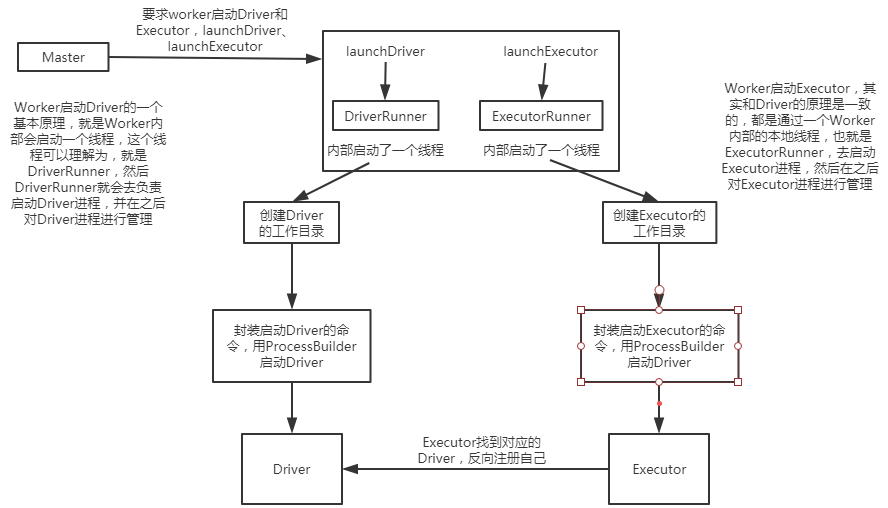
Worker启动Driver的一个基本原理,就是Worker内部会启动一个线程,这个线程可以理解为,就是DriverRunner,然后DriverRunner就会去负责启动Driver进程,
并在之后对Driver进程进行管理; Worker启动Executor,其实和Driver的原理是一致的,都是通过一个Worker内部的本地线程,也就是ExecutorRunner,去启动Executor进程,然后在之后
对Executor进程进行管理;
二、源码分析
1、Driver的启动
###org.apache.spark.deploy.worker/Worker.scala
case LaunchDriver(driverId, driverDesc) => {
logInfo(s"Asked to launch driver $driverId")
// 创建DriverRunner
val driver = new DriverRunner(
conf,
driverId,
workDir,
sparkHome,
driverDesc.copy(command = Worker.maybeUpdateSSLSettings(driverDesc.command, conf)),
self,
akkaUrl)
// 将driver加入本地缓存
drivers(driverId) = driver
// 开始DriverRunner
driver.start()
// 加上Driver要使用的资源
coresUsed += driverDesc.cores
memoryUsed += driverDesc.mem
}
###org.apache.spark.deploy.worker/DriverRunner.scala
###driver.start()方法
def start() = {
// 启动一个java线程
new Thread("DriverRunner for " + driverId) {
// java线程体
override def run() {
try {
// 创建Driver的工作目录
val driverDir = createWorkingDirectory()
// 下载用户上传的jar(java/scala,用maven打的jar包)
val localJarFilename = downloadUserJar(driverDir)
def substituteVariables(argument: String): String = argument match {
case "{{WORKER_URL}}" => workerUrl
case "{{USER_JAR}}" => localJarFilename
case other => other
}
// TODO: If we add ability to submit multiple jars they should also be added here
// 构建ProcessBuilder,传入了driver的启动命令,需要的内存大小等信息
val builder = CommandUtils.buildProcessBuilder(driverDesc.command, driverDesc.mem,
sparkHome.getAbsolutePath, substituteVariables)
// 启动Driver
launchDriver(builder, driverDir, driverDesc.supervise)
}
catch {
case e: Exception => finalException = Some(e)
}
// 对driver的退出状态做一些处理
val state =
if (killed) {
DriverState.KILLED
} else if (finalException.isDefined) {
DriverState.ERROR
} else {
finalExitCode match {
case Some(0) => DriverState.FINISHED
case _ => DriverState.FAILED
}
}
finalState = Some(state)
// 这个DriverRunner线程,向它所属的worker的actor,发送一个DriverStateChanged的事件
worker ! DriverStateChanged(driverId, state, finalException)
}
}.start()
}
###org.apache.spark.deploy.worker/DriverRunner.scala
###downloadUserJar()方法
private def downloadUserJar(driverDir: File): String = {
// hadoop jar里的Path
val jarPath = new Path(driverDesc.jarUrl)
// 拿到hadoop配置
val hadoopConf = SparkHadoopUtil.get.newConfiguration(conf)
// 获取HDFS的FileSystem
val jarFileSystem = jarPath.getFileSystem(hadoopConf)
// 创建本地目录
val destPath = new File(driverDir.getAbsolutePath, jarPath.getName)
val jarFileName = jarPath.getName
val localJarFile = new File(driverDir, jarFileName)
val localJarFilename = localJarFile.getAbsolutePath
// 如果jar在本地不存在
if (!localJarFile.exists()) { // May already exist if running multiple workers on one node
logInfo(s"Copying user jar $jarPath to $destPath")
// 用FileUtil将jar拷贝到本地
FileUtil.copy(jarFileSystem, jarPath, destPath, false, hadoopConf)
}
// 如果拷贝完了,发现jar还不存在,那么就抛出异常
if (!localJarFile.exists()) { // Verify copy succeeded
throw new Exception(s"Did not see expected jar $jarFileName in $driverDir")
}
localJarFilename
}
###org.apache.spark.deploy.worker/DriverRunner.scala
###launchDriver()方法
private def launchDriver(builder: ProcessBuilder, baseDir: File, supervise: Boolean) {
builder.directory(baseDir)
def initialize(process: Process) = {
// Redirect stdout and stderr to files
// 重定向stdout和stderr输出流到文件中
val stdout = new File(baseDir, "stdout")
CommandUtils.redirectStream(process.getInputStream, stdout)
val stderr = new File(baseDir, "stderr")
val header = "Launch Command: %s\n%s\n\n".format(
builder.command.mkString("\"", "\" \"", "\""), "=" * 40)
Files.append(header, stderr, UTF_8)
CommandUtils.redirectStream(process.getErrorStream, stderr)
}
runCommandWithRetry(ProcessBuilderLike(builder), initialize, supervise)
}
###org.apache.spark.deploy.worker/Worker.scala
###DriverStateChanged
case DriverStateChanged(driverId, state, exception) => {
state match {
// 如果Driver的状态是错误、完成、杀死、失败,就移除Driver
case DriverState.ERROR | DriverState.FINISHED | DriverState.KILLED | DriverState.FAILED =>
removeDriver(driverId, state, exception)
case _ =>
throw new Exception(s"Received unexpected state update for driver $driverId: $state")
}
}
###org.apache.spark.deploy.worker/Worker.scala
###Executor的启动
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name))
// Create the executor's working directory
// 创建Executor本地工作目录
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
}
// Create local dirs for the executor. These are passed to the executor via the
// SPARK_LOCAL_DIRS environment variable, and deleted by the Worker when the
// application finishes.
val appLocalDirs = appDirectories.get(appId).getOrElse {
Utils.getOrCreateLocalRootDirs(conf).map { dir =>
Utils.createDirectory(dir).getAbsolutePath()
}.toSeq
}
appDirectories(appId) = appLocalDirs
// 创建ExecutorRunner
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
akkaUrl,
conf,
appLocalDirs, ExecutorState.LOADING)
// 把Executor加入本地缓存
executors(appId + "/" + execId) = manager
// 启动ExecutorRunner
manager.start()
// 加上Executor要使用的资源
coresUsed += cores_
memoryUsed += memory_
// 向master返回一个ExecutorStateChanged消息
master ! ExecutorStateChanged(appId, execId, manager.state, None, None)
} catch {
case e: Exception => {
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
master ! ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None)
}
}
}
###org.apache.spark.deploy.worker/DriverRunner.scala
###manager.start()
def start() {
// 创建一个java线程
workerThread = new Thread("ExecutorRunner for " + fullId) {
override def run() { fetchAndRunExecutor() }
}
workerThread.start()
// Shutdown hook that kills actors on shutdown.
shutdownHook = new Thread() {
override def run() {
killProcess(Some("Worker shutting down"))
}
}
Runtime.getRuntime.addShutdownHook(shutdownHook)
}
###org.apache.spark.deploy.worker/DriverRunner.scala
###fetchAndRunExecutor()
def fetchAndRunExecutor() {
try {
// Launch the process
// 封装一个ProcessBuilder
val builder = CommandUtils.buildProcessBuilder(appDesc.command, memory,
sparkHome.getAbsolutePath, substituteVariables)
val command = builder.command()
logInfo("Launch command: " + command.mkString("\"", "\" \"", "\""))
builder.directory(executorDir)
builder.environment.put("SPARK_LOCAL_DIRS", appLocalDirs.mkString(","))
// In case we are running this from within the Spark Shell, avoid creating a "scala"
// parent process for the executor command
builder.environment.put("SPARK_LAUNCH_WITH_SCALA", "0")
// Add webUI log urls
val baseUrl =
s"http://$publicAddress:$webUiPort/logPage/?appId=$appId&executorId=$execId&logType="
builder.environment.put("SPARK_LOG_URL_STDERR", s"${baseUrl}stderr")
builder.environment.put("SPARK_LOG_URL_STDOUT", s"${baseUrl}stdout")
process = builder.start()
// 重定向输出流到文件
// 将Executor的InputStream和ErrorStream输出的信息分别重定向到本地工作目录的stdout文件和stderr文件
val header = "Spark Executor Command: %s\n%s\n\n".format(
command.mkString("\"", "\" \"", "\""), "=" * 40)
// Redirect its stdout and stderr to files
val stdout = new File(executorDir, "stdout")
stdoutAppender = FileAppender(process.getInputStream, stdout, conf)
val stderr = new File(executorDir, "stderr")
Files.write(header, stderr, UTF_8)
stderrAppender = FileAppender(process.getErrorStream, stderr, conf)
// Wait for it to exit; executor may exit with code 0 (when driver instructs it to shutdown)
// or with nonzero exit code
// 调用process的waitFor()方法,启动Executor进程
val exitCode = process.waitFor()
//executor执行完之后拿到返回状态
state = ExecutorState.EXITED
val message = "Command exited with code " + exitCode
// 向ExecutorRunner线程所属的worker actor,发送ExecutorStateChanged消息
worker ! ExecutorStateChanged(appId, execId, state, Some(message), Some(exitCode))
} catch {
case interrupted: InterruptedException => {
logInfo("Runner thread for executor " + fullId + " interrupted")
state = ExecutorState.KILLED
killProcess(None)
}
case e: Exception => {
logError("Error running executor", e)
state = ExecutorState.FAILED
killProcess(Some(e.toString))
}
}
}
###org.apache.spark.deploy.worker/Worker.scala
case ExecutorStateChanged(appId, execId, state, message, exitStatus) =>
// 直接向master也发送一个ExecutorStateChanged消息
master ! ExecutorStateChanged(appId, execId, state, message, exitStatus)
val fullId = appId + "/" + execId
// 如果Executor状态是finished
if (ExecutorState.isFinished(state)) {
executors.get(fullId) match {
case Some(executor) =>
logInfo("Executor " + fullId + " finished with state " + state +
message.map(" message " + _).getOrElse("") +
exitStatus.map(" exitStatus " + _).getOrElse(""))
// 将executor从内存缓存中移除
executors -= fullId
finishedExecutors(fullId) = executor
// 释放Executor占用的内存和cpu资源
coresUsed -= executor.cores
memoryUsed -= executor.memory
case None =>
logInfo("Unknown Executor " + fullId + " finished with state " + state +
message.map(" message " + _).getOrElse("") +
exitStatus.map(" exitStatus " + _).getOrElse(""))
}
maybeCleanupApplication(appId)
}
###org.apache.spark.deploy.master/Master.scala
case ExecutorStateChanged(appId, execId, state, message, exitStatus) => {
// 找到Executor对应的Application,然后再反过来通过Application内部的Executor缓存获取Executor信息
val execOption = idToApp.get(appId).flatMap(app => app.executors.get(execId))
execOption match {
case Some(exec) => {
// 如果有值
val appInfo = idToApp(appId)
exec.state = state
if (state == ExecutorState.RUNNING) { appInfo.resetRetryCount() }
// 向driver同步发送ExecutorUpdated消息
exec.application.driver ! ExecutorUpdated(execId, state, message, exitStatus)
// 判断,如果Executor完成了
if (ExecutorState.isFinished(state)) {
// Remove this executor from the worker and app
logInfo(s"Removing executor ${exec.fullId} because it is $state")
// 从Application缓存中移除Executor
appInfo.removeExecutor(exec)
// 从运行Executor的Worker的缓存中移除Executor
exec.worker.removeExecutor(exec)
// 判断 如果Executor的退出状态是非正常的
val normalExit = exitStatus == Some(0)
// Only retry certain number of times so we don't go into an infinite loop.
if (!normalExit) {
// 判断Application当前的重试次数,是否达到了最大值,最大值是10
// 也就是说,Executor反复调度都是失败,那么认为Application也失败了
if (appInfo.incrementRetryCount() < ApplicationState.MAX_NUM_RETRY) {
// 重新进行调度
schedule()
} else {
// 否则,进行移除Application操作
val execs = appInfo.executors.values
if (!execs.exists(_.state == ExecutorState.RUNNING)) {
logError(s"Application ${appInfo.desc.name} with ID ${appInfo.id} failed " +
s"${appInfo.retryCount} times; removing it")
removeApplication(appInfo, ApplicationState.FAILED)
}
}
}
}
}
case None =>
logWarning(s"Got status update for unknown executor $appId/$execId")
}
}
15、Work原理及源码分析的更多相关文章
- ConcurrentHashMap实现原理及源码分析
ConcurrentHashMap实现原理 ConcurrentHashMap源码分析 总结 ConcurrentHashMap是Java并发包中提供的一个线程安全且高效的HashMap实现(若对Ha ...
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- HashMap实现原理及源码分析之JDK8
继续上回HashMap的学习 HashMap实现原理及源码分析之JDK7 转载 Java8源码-HashMap 基于JDK8的HashMap源码解析 [jdk1.8]HashMap源码分析 一.H ...
- 【OpenCV】SIFT原理与源码分析:方向赋值
<SIFT原理与源码分析>系列文章索引:http://www.cnblogs.com/tianyalu/p/5467813.html 由前一篇<关键点搜索与定位>,我们已经找到 ...
- 每天学会一点点(HashMap实现原理及源码分析)
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希 ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- (转)ReentrantLock实现原理及源码分析
背景:ReetrantLock底层是基于AQS实现的(CAS+CHL),有公平和非公平两种区别. 这种底层机制,很有必要通过跟踪源码来进行分析. 参考 ReentrantLock实现原理及源码分析 源 ...
- 【OpenCV】SIFT原理与源码分析:DoG尺度空间构造
原文地址:http://blog.csdn.net/xiaowei_cqu/article/details/8067881 尺度空间理论 自然界中的物体随着观测尺度不同有不同的表现形态.例如我们形 ...
- 《深入探索Netty原理及源码分析》文集小结
<深入探索Netty原理及源码分析>文集小结 https://www.jianshu.com/p/239a196152de
随机推荐
- [洛谷P2056][ZJOI2007]捉迷藏(2019-7-20考试)
题目大意:有一棵$n(n\leqslant10^6)$个点的树,上面所有点是黑点,有$m$次操作: $C\;u$:把点$u$颜色翻转 $G$:问树上最远的两个黑点的距离,若没有黑点输出$0$ 题解:有 ...
- Jupyter Notebook的配置(密码端口+远程登陆+nbextension)
1 生成配置文件 linux和mac系统打开终端 windows系统打开anaconda自带的终端 jupyter notebook --generate-config 此时系统会生成 ~/.jupy ...
- vscode 连接远程服务器 sftp
1.在vscode 应用商店搜索 sftp 下载安装 2.ctrl+shift+p 搜索sftp:config 生成sftp.json 3.配置你的服务器信息{ "name": & ...
- JavaTCP粘包、拆包
import java.nio.ByteBuffer; import io.netty.bootstrap.ServerBootstrap; import io.netty.buffer.ByteBu ...
- js获取项目名称
//获取路径 var pathName=window.document.location.pathname; //截取,得到项目名称 var projectName=pathName.substrin ...
- Python接口自动化基础---session关联接口
登录一个系统之后,如果需要在登录状态下进行一些操作,那么需要怎样保持会话呢? 可以使用Session() 举例如下: import requests s=requests.Session() url1 ...
- Hibernate中Session.get()/load()之区别
原文链接http://sunxin1001.iteye.com/blog/292090 Session.load/get方法均可以根据指定的实体类和id从数据库读取记录,并返回与之对应的实体对象.其区 ...
- TCP_Wrappers基础知识介绍
1. TCP_Wrappers基础知识介绍 TCP_Wrappers是在 Solaris, HP_UX以及 Linux中广泛流行的免费软件.它被设计为一个介于外来服务请求和系统服务回应的中间处理软件. ...
- 【转】高性能网络编程3----TCP消息的接收
这篇文章将试图说明应用程序如何接收网络上发送过来的TCP消息流,由于篇幅所限,暂时忽略ACK报文的回复和接收窗口的滑动. 为了快速掌握本文所要表达的思想,我们可以带着以下问题阅读: 1.应用程序调用r ...
- 大数据技术之Hadoop3.1.2版本完全分布式部署
大数据技术之Hadoop3.1.2版本完全分布式部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.主机环境准备 1>.操作系统环境 [root@node101.yinz ...