C#使用Redis实现网站统计访问数或点赞数功能!
1.安装.net操作Redis需要的NuGet包:
这里推荐使用:StackExchange.Redis,在程序包管理器控制台输入命令install-package stackexchange.redis
2.在Action下编写实现代码:
public class HomeController : Controller
{
private readonly static string keyPerfix = "Test_ClickTotal_";
// GET: Home
public async Task<ActionResult> Index(int Id=)
{
using (ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("localhost:6379"))
{
IDatabase db = redis.GetDatabase(); //Redis默认有15个数据库,GetDatabase()中参数代表将数据存入那个数据中
await db.StringIncrementAsync(keyPerfix+Id,); //使用StringIncrementAsync来进行计数,效率很高 string total = await db.StringGetAsync(keyPerfix + Id); //增加之后在读取出来
ClickTotalModel totalModel = new ClickTotalModel { Total=Convert.ToInt32(total)};
return View(totalModel);
} }
}
3.调试结果:
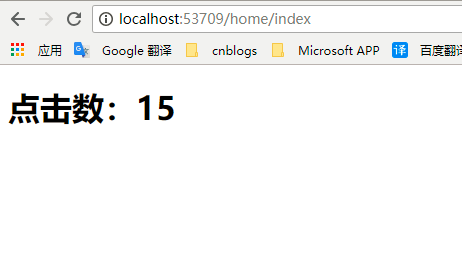
每次刷新进入界面时,点击数都会增加一次.
4.当然有个问题,实际应用中一个用户或一个IP在一段时间内或永久时间只能算访问一次,后面的访问将不计入总数中:
public class HomeController : Controller
{
private readonly static string keyPerfix = "Test_ClickTotal_";
// GET: Home
public async Task<ActionResult> Index(int Id = )
{
using (ConnectionMultiplexer redis = ConnectionMultiplexer.Connect("localhost:6379"))
{
IDatabase db = redis.GetDatabase(); //Redis默认有15个数据库,GetDatabase()中参数代表将数据存入那个数据中 if (await db.KeyExistsAsync(keyPerfix + Request.UserHostAddress + Id) == false) //keyPerfix+访问者的IP地址+Id为 key,记录这个IP是否点击过
{
//说明没有找到
await db.StringIncrementAsync(keyPerfix + Id, ); //使用StringIncrementAsync来进行计数,效率很高 //这里就增加一条已经访问过的记录,key值要上面判断格式一致,value值随意,第三个参数表示一天后这条记录就失效
await db.StringSetAsync(keyPerfix + Request.UserHostAddress + Id, "true", TimeSpan.FromDays()); string total = await db.StringGetAsync(keyPerfix + Id); //增加之后在读取出来
ClickTotalModel totalModel = new ClickTotalModel { Total = Convert.ToInt32(total) };
return View(totalModel);
}
else
{
//直接读出来
string total = await db.StringGetAsync(keyPerfix + Id);
ClickTotalModel totalModel = new ClickTotalModel { Total = Convert.ToInt32(total) };
return View(totalModel);
} } }
}
我这个实现的方法是:通过IP为键值插入一条数据,有效时间为一天,计数前先判断是否该IP记录是否存在,存在的话就不计入总数。
C#使用Redis实现网站统计访问数或点赞数功能!的更多相关文章
- Shell 命令行统计 apache 网站日志访问IP以及IP归属地
Shell 命令行统计 apache 网站日志访问IP以及IP归属地 我的一个站点用 apache 服务跑着,积攒了很多的日志.我想用 shell 看看有哪些人访问过我的站点,并且他来自哪里. 因为日 ...
- 学习笔记_过滤器应用_1(分ip统计网站的访问次数)
分ip统计网站的访问次数 ip count 192.168.1.111 2 192.168.1.112 59 统计工作需要在所有资源之前都执行,那么就可以放到Filter中了. 我们这个过滤器不打算做 ...
- Java web 实现 之 Filter分析ip统计网站的访问次数
统计工作需要在所有资源之前都执行,那么就可以放到Filter中了. 我们这个过滤器不打算做拦截操作!因为我们只是用来做统计的. 用什么东西来装载统计的数据.Map<String,Integer& ...
- 网站统计中的数据收集原理及实现(share)
转载自:http://blog.codinglabs.org/articles/how-web-analytics-data-collection-system-work.html 网站数据统计分析工 ...
- 使用nginx lua实现网站统计中的数据收集
导读网站数据统计分析工具是各网站站长和运营人员经常使用的一种工具,常用的有 谷歌分析.百度统计和腾讯分析等等.所有这些统计分析工具的第一步都是网站访问数据的收集.目前主流的数据收集方式基本都是基于ja ...
- 网站统计IP PV UV实现原理
网站流量统计可以帮助我们分析网站的访问和广告来访等数据,里面包含很多数据的,比如访问试用的系统,浏览器,ip归属地,访问时间,搜索引擎来源,广告效果等.原来是一样的,这次先实现了PV,UV,IP三个重 ...
- 网站统计IP PV UV
###我只是一个搬运工 网站流量统计可以帮助我们分析网站的访问和广告来访等数据,里面包含很多数据的,比如访问使用的系统,浏览器,ip归属地,访问时间,搜索引擎来源,广告效果等. PV(访问量):Pag ...
- 怎么区分PV、IV、UV以及网站统计名词解释(pv、曝光、点击)
PV(Page View)访问量,即页面访问量,每打开一次页面PV计数+1,刷新页面也是. IV(Internet Protocol)访问量指独立IP访问数,计算是以一个独立的IP在一个计算时段内访问 ...
- 一个典型的MapRuduce实例------webcount(网站统计访客信息)
统计某一特定网站的某个时辰访客人数 所用版本:hadoop2.6.5 数据样式如下: 111.111.111.111 - - [16/Dec/2012:05:32:50 -0500] "GE ...
随机推荐
- git的使用(二)
GITHUB 简介 github可以是全世界最大的同性交友网站,其实就是和百度云一个性质. gitHub于2008年4月10日正式上线,除了git代码仓库托管及基本的 Web管理界面以外,还提供了订阅 ...
- ssh 到服务器然后输入中文保存到本地变成乱码
很有可能是 默认的编码导致的 尝试执行 echo $LANG 如果是 en_US vim 输入中文有较大概率是 GBK 编码 尝试把这个加入到 ~/.bashrc export LANG=zh_CN. ...
- 201871010112-梁丽珍《面向对象程序设计(java)》第十一周学习总结
项目 内容 这个作业属于哪个课程 https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 https://www.cnblogs.com/nwnu-daizh/p ...
- CF1245 A. Good ol' Numbers Coloring(java与gcd)
题意:给定数字A和数字B,问是否满足gcd(A,B)==1. 思路:可以直接写函数gcd.也可以用大数自带的gcd功能. 代码1: /* @author nimphy @create 2019-11- ...
- thymeleaf实现热部署
热部署可以在修改页面之后,不重新启动服务器也能查看修改效果. 1.导入依赖,我用的是gradle,使用maven的可以去https://mvnrepository.com/寻找对应的依赖 compil ...
- openlayers在底图上添加静态icon
越学习openlayer你会发现openlayer是真的很强大,今天记录一下学习的成果,需求是做那种室内的CAD的场景然后里面展示人员icon并且实时展示人员的位置信息,以及点击弹出对应人员的一些位置 ...
- [CODEVS4632][BZOJ4326]运输计划
题目描述 Description 公元 2044 年,人类进入了宇宙纪元.L 国有 n 个星球,还有 n−1 条双向航道,每条航道建立在两个星球之间,这 n−1 条航道连通了 L 国的所有星球.小 P ...
- string方法介绍
#_*_coding:utf-8_*_#作者:王佃元#日期:2019/12/9#string操作print('hello'*2) #乘法操作,输出对应次数print('helloworld'[2:]) ...
- 徒手实现lower_bound和upper_bound
STL中lower_bound和upper_bound的使用方法:STL 二分查找 lower_bound: ; ; //初始化 l ,为第一个合法地址 ; //初始化 r , 地址的结束地址 int ...
- [LeetCode] 721. Accounts Merge 账户合并
Given a list accounts, each element accounts[i] is a list of strings, where the first element accoun ...