zz1998_Efficient Backprop笔记
1998_Efficient Backprop笔记
A few practical tricks
1. Stochastic vs Batch learning


在最小值附近震荡的幅度与学习速率成比例,为了减小震荡,可以减小学习速率或者使用自适应的batch size。
有理论证明以下这种形式的学习速率最好:
其中t是类别数,c是一个常量,实际上,这个速率可能太快。
另一种消除噪声的方法是用mini-batch,就是开始用一个小的batch size,然后随着训练进行增加。但是如何增加和调整学习速率一样困难。
2. Shuffling the examples
网络从未知样本学习最快,因此要在每一次迭代选择最不熟悉的样本。这个方法只适用于SGD,最简单的方式是选择连续的不同类的样本。

3. Normalizing the inputs

4. The Sigmoid


用对称的sigmoid函数有一个潜在的问题,那就是误差平面会变得很平坦,因此应该避免用很小的值初始化weights。
5. Choosing Target Values

6. Initializing the weights

7. Choosing Learning Rates
一般情况下权重向量震荡时减小学习速率,而始终保持稳定的方向则增加,但是不适用于SGD和online learning,因为他们始终在震荡。

Momentum:
其中u是momentum的强度,当误差平面是非球形(nonspherical),它增加了收敛速度因为它减小了高曲率方向的step,从而在低曲率部分增加了学习速率的影响。它通常在batch learning中比SGD更有效。
Adaptive Learning Rates:


这个方法实际上很容易实现,其实就是track公式18中的矩阵,平均梯度r。这个矩阵的norm控制学习速率的大小。
8. Radial Basis Functions vs Sigmoid Units
RBF神经网络:
sigmoid单元可以覆盖整个输入空间,但是一个RBF单元只能覆盖一个小的局部空间,因此它的学习更快。但是在高维空间中它需要更多的单元去覆盖整个空间,因此RBF适合作为高层而sigmoid适合作为低层单元。
Convergence of Gradient Descent
1. A little theory
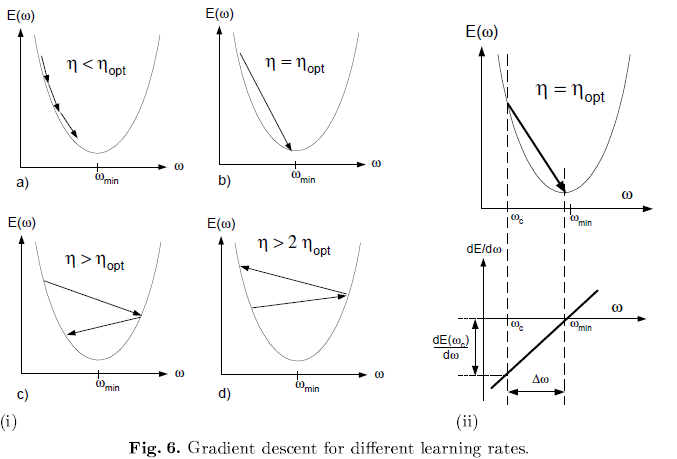
具体理论分析见文章。
结论:
如果对所有的weight约定一个学习速率,那么

2. Two examples
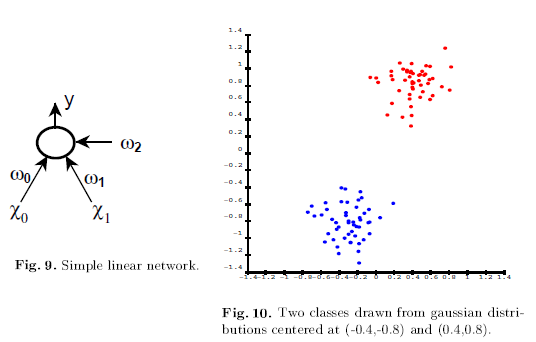

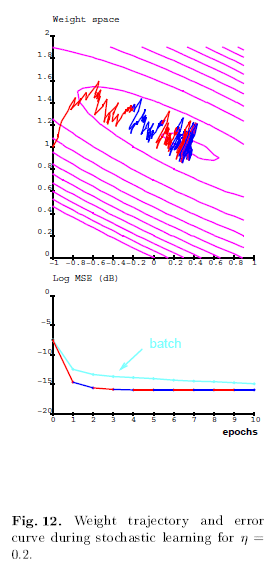
b. Multilayer Network


3. 以上的理论可以证明这几个tricks:
zz1998_Efficient Backprop笔记的更多相关文章
- Deep Learning 16:用自编码器对数据进行降维_读论文“Reducing the Dimensionality of Data with Neural Networks”的笔记
前言 论文“Reducing the Dimensionality of Data with Neural Networks”是深度学习鼻祖hinton于2006年发表于<SCIENCE > ...
- MXNet设计笔记之:深度学习的编程模式比较
市面上流行着各式各样的深度学习库,它们风格各异.那么这些函数库的风格在系统优化和用户体验方面又有哪些优势和缺陷呢?本文旨在于比较它们在编程模式方面的差异,讨论这些模式的基本优劣势,以及我们从中可以学到 ...
- 神经网络与深度学习笔记 Chapter 1.
转载请注明出处:http://www.cnblogs.com/zhangcaiwang/p/6875533.html sigmoid neuron 微小的输入变化导致微小的输出变化,这种特性将会使得学 ...
- CS231n官方笔记授权翻译总集篇发布
CS231n简介 CS231n的全称是CS231n: Convolutional Neural Networks for Visual Recognition,即面向视觉识别的卷积神经网络.该课程是斯 ...
- CS231n课程笔记翻译8:神经网络笔记 part3
译者注:本文智能单元首发,译自斯坦福CS231n课程笔记Neural Nets notes 3,课程教师Andrej Karpathy授权翻译.本篇教程由杜客翻译完成,堃堃和巩子嘉进行校对修改.译文含 ...
- CS231n课程笔记翻译5:反向传播笔记
译者注:本文智能单元首发,译自斯坦福CS231n课程笔记Backprop Note,课程教师Andrej Karpathy授权翻译.本篇教程由杜客翻译完成,堃堃和巩子嘉进行校对修改.译文含公式和代码, ...
- 【cs231n】反向传播笔记
前言 首先声明,以下内容绝大部分转自知乎智能单元,他们将官方学习笔记进行了很专业的翻译,在此我会直接copy他们翻译的笔记,有些地方会用红字写自己的笔记,本文只是作为自己的学习笔记.本文内容官网链接: ...
- 基于3D卷积神经网络的人体行为理解(论文笔记)(转)
基于3D卷积神经网络的人体行为理解(论文笔记) zouxy09@qq.com http://blog.csdn.net/zouxy09 最近看Deep Learning的论文,看到这篇论文:3D Co ...
- 笔记:CS231n+assignment1(作业一)
CS231n的课后作业非常的好,这里记录一下自己对作业一些笔记. 一.第一个是KNN的代码,这里的trick是计算距离的三种方法,核心的话还是python和machine learning中非常实用的 ...
随机推荐
- SLAM中的非线性优化
总结一下SLAM中关于非线性优化的知识. 先列出参考: http://jacoxu.com/jacobian%E7%9F%A9%E9%98%B5%E5%92%8Chessian%E7%9F%A9%E9 ...
- Paper | Non-Local ConvLSTM for Video Compression Artifact Reduction
目录 1. 方法 1.1 框图 1.2 NL流程 1.3 加速版NL 2. 实验 3. 总结 [这是MFQE 2.0的第一篇引用,也是博主学术生涯的第一篇引用.最重要的是,这篇文章确实抓住了MFQE方 ...
- 解惑:如何使用SecureCRT上传和下载文件、SecureFX乱码问题
解惑:如何使用SecureCRT上传和下载文件.SecureFX乱码问题 一.前言 很多时候在windows平台上访问Linux系统的比较好用的工具之一就是SecureCRT了,下面介绍一下这个软件的 ...
- (三十九)golang--反序列化
反序列化:是指将json字符串反序列化成原来的数据类型. import ( "encoding/json" "fmt" ) type monster struc ...
- vue+element 动态表单验证
公司最近的项目有个添加动态表单的需求,总结一下我在表单验证上遇到的一些坑. 如图是功能的需求,这个功能挺好实现的,但是表单验证真是耗费了我一些功夫. vue+element在表单验证上有一些限制,必须 ...
- C++:Special Member Functions
Special Member Functions 区别于定义类的行为的普通成员函数,类内有一类特殊的成员函数,它们负责类的构造.拷贝.移动.销毁. 构造函数 构造函数控制对象的初始化过程,具体来说,就 ...
- hdu-6071 Lazy Running
In HDU, you have to run along the campus for 24 times, or you will fail in PE. According to the rule ...
- K8S集群集成harbor(1.9.3)服务并配置HTTPS
一.简介 简介请参考:https://www.cnblogs.com/panwenbin-logs/p/10218099.html 二.安装Harbor主机环境及安装要求 主机环境: OS: Cent ...
- MySQL分析数据运行状态利器【show full processlist】
原文地址:https://www.cnblogs.com/shihuc/p/8733460.html 今天的主角是: SHOW [FULL] PROCESSLIST show full process ...
- python语法01
在某.py文件中调用其他.py文件中的内容. 全局变量的使用. 线程的使用. if name == 'main': 的作用 新建两个python脚本文件 f1File.py ""& ...