二十二、mysql索引原理详解
背景
使用mysql最多的就是查询,我们迫切的希望mysql能查询的更快一些,我们经常用到的查询有:
按照id查询唯一一条记录
按照某些个字段查询对应的记录
查找某个范围的所有记录(between and)
对查询出来的结果排序
mysql的索引的目的是使上面的各种查询能够更快。
一、预备知识
什么是索引?
上一篇中有详细的介绍,可以过去看一下:什么是索引?
索引的本质:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
磁盘中数据的存取
以机械硬盘来说,先了解几个概念。
扇区:磁盘存储的最小单位,扇区一般大小为512Byte。
磁盘块:文件系统与磁盘交互的的最小单位(计算机系统读写磁盘的最小单位),一个磁盘块由连续几个(2^n)扇区组成,块一般大小一般为4KB。
磁盘读取数据:磁盘读取数据靠的是机械运动,每次读取数据花费的时间可以分为寻道时间、旋转延迟、传输时间三个部分,寻道时间指的是磁臂移动到指定磁道所需要的时间,主流磁盘一般在5ms以下;旋转延迟就是我们经常听说的磁盘转速,比如一个磁盘7200转,表示每分钟能转7200次,也就是说1秒钟能转120次,旋转延迟就是1/120/2 = 4.17ms;传输时间指的是从磁盘读出或将数据写入磁盘的时间,一般在零点几毫秒,相对于前两个时间可以忽略不计。那么访问一次磁盘的时间,即一次磁盘IO的时间约等于5+4.17 = 9ms左右,听起来还挺不错的,但要知道一台500 -MIPS的机器每秒可以执行5亿条指令,因为指令依靠的是电的性质,换句话说执行一次IO的时间可以执行40万条指令,数据库动辄十万百万乃至千万级数据,每次9毫秒的时间,显然是个灾难。
mysql中的页
mysql中和磁盘交互的最小单位称为页,页是mysql内部定义的一种数据结构,默认为16kb,相当于4个磁盘块,也就是说mysql每次从磁盘中读取一次数据是16KB,要么不读取,要读取就是16KB,此值可以修改的。
数据检索过程
我们对数据存储方式不做任何优化,直接将数据库中表的记录存储在磁盘中,假如某个表只有一个字段,为int类型,int占用4个byte,每个磁盘块可以存储1000条记录,100万的记录需要1000个磁盘块,如果我们需要从这100万记录中检索所需要的记录,需要读取1000个磁盘块的数据(需要1000次io),每次io需要9ms,那么1000次需要9000ms=9s,100条数据随便一个查询就是9秒,这种情况我们是无法接受的,显然是不行的。
二、我们迫切的需求是什么?
我们迫切需要这样的数据结构和算法:
需要一种数据存储结构:当从磁盘中检索数据的时候能,够减少磁盘的io次数,最好能够降低到一个稳定的常量值
需要一种检索算法:当从磁盘中读取磁盘块的数据之后,这些块中可能包含多条记录,这些记录被加载到内存中,那么需要一种算法能够快速从内存多条记录中快速检索出目标数据
我们来找找,看是否能够找到这样的算法和数据结构。
我们看一下常见的检索算法和数据结构。
三、循环遍历查找
从一组无序的数据中查找目标数据,常见的方法是遍历查询,n条数据,时间复杂度为O(n),最快需要1次,最坏的情况需要n次,查询效率不稳定。
四、二分法查找
二分法查找也称为折半查找,用于在一个有序数组中快速定义某一个需要查找的数据。
原理是:
先将一组无序的数据排序(升序或者降序)之后放在数组中,此处用升序来举例说明:用数组中间位置的数据A和需要查找的数据F对比,如果A=F,则结束查找;如果A<F,则将查找的范围缩小至数组中A数据右边的部分;如果A>F,则将查找范围缩小至数组中A数据左边的部分,继续按照上面的方法直到找到F为止。
示例:
从下列有序数字中查找数字9,过程如下
[1,2,3,4,5,6,7,8,9]
第1次查找:[1,2,3,4,5,6,7,8,9]中间位置值为5,9>5,将查找范围缩小至5右边的部分:[6、7、8、9]
第2次查找:[6、7、8、9]中间值为8,9>8 ,将范围缩小至8右边部分:[9]
第3次查找:在[9]中查找9,找到了。
可以看到查找速度是相当快的,每次查找都会使范围减半,如果我们采用顺序查找,上面数据最快需要1次,最多需要9次,而二分法查找最多只需要3次,耗时时间也比较稳定。
二分法查找时间复杂度是:O(logN)(N为数据量),100万数据查找最多只需要20次(2^20=1048576)
二分法查找数据的优点:定位数据非常快,前提是:目标数组是有序的。
五、有序数组
如果我们将mysql中表的数据以有序数组的方式存储在磁盘中,那么我们定位数据步骤是:
取出目标表的所有数据,存放在一个有序数组中
如果目标表的数据量非常大,从磁盘中加载到内存中需要的内存也非常大
步骤取出所有数据耗费的io次数太多,步骤2耗费的内存空间太大,还有新增数据的时候,为了保证数组有序,插入数据会涉及到数组内部数据的移动,也是比较耗时的,显然用这种方式存储数据是不可取的。
六、链表
链表相当于在每个节点上增加一些指针,可以和前面或者后面的节点连接起来,就像一列火车一样,每节车厢相当于一个节点,车厢内部可以存储数据,每个车厢和下一节车厢相连。
链表分为单链表和双向链表。
单链表
每个节点中有持有指向下一个节点的指针,只能按照一个方向遍历链表,结构如下:
//单项链表
class Node1{
private Object data;//存储数据
private Node1 nextNode;//指向下一个节点
}
双向链表
每个节点中两个指针,分别指向当前节点的上一个节点和下一个节点,结构如下:
//双向链表
class Node2{
private Object data;//存储数据
private Node1 prevNode;//指向上一个节点
private Node1 nextNode;//指向下一个节点
}
链表的优点:
可以快速定位到上一个或者下一个节点
可以快速删除数据,只需改变指针的指向即可,这点比数组好
链表的缺点:
无法向数组那样,通过下标随机访问数据
查找数据需从第一个节点开始遍历,不利于数据的查找,查找时间和无序数据类似,需要全遍历,最差时间是O(N)
七、二叉查找树
二叉树是每个结点最多有两个子树的树结构,通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。二叉树有如下特性:
1、每个结点都包含一个元素以及n个子树,这里0≤n≤2。
2、左子树和右子树是有顺序的,次序不能任意颠倒,左子树的值要小于父结点,右子树的值要大于父结点。
数组[20,10,5,15,30,25,35]使用二叉查找树存储如下:
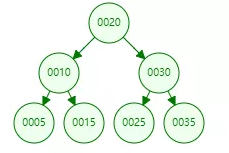
每个节点上面有两个指针(left,rigth),可以通过这2个指针快速访问左右子节点,检索任何一个数据最多只需要访问3个节点,相当于访问了3次数据,时间为O(logN),和二分法查找效率一样,查询数据还是比较快的。
但是如果我们插入数据是有序的,如[5,10,15,20,30,25,35],那么结构就变成下面这样:
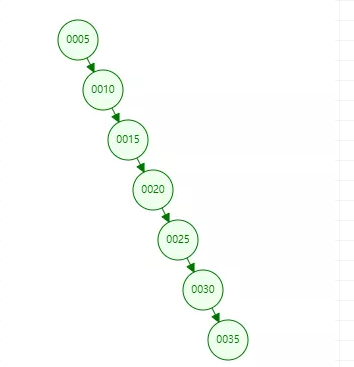
二叉树退化为了一个链表结构,查询数据最差就变为了O(N)。
二叉树的优缺点:
查询数据的效率不稳定,若树左右比较平衡的时,最差情况为O(logN),如果插入数据是有序的,退化为了链表,查询时间变成了O(N)
数据量大的情况下,会导致树的高度变高,如果每个节点对应磁盘的一个块来存储一条数据,需io次数大幅增加,显然用此结构来存储数据是不可取的
八、平衡二叉树(AVL树)
平衡二叉树是一种特殊的二叉树,所以他也满足前面说到的二叉查找树的两个特性,同时还有一个特性:
它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
平衡二叉树相对于二叉树来说,树的左右比较平衡,不会出现二叉树那样退化成链表的情况,不管怎么插入数据,最终通过一些调整,都能够保证树左右高度相差不大于1。
这样可以让查询速度比较稳定,查询中遍历节点控制在O(logN)范围内
如果数据都存储在内存中,采用AVL树来存储,还是可以的,查询效率非常高。不过我们的数据是存在磁盘中,用过采用这种结构,每个节点对应一个磁盘块,数据量大的时候,也会和二叉树一样,会导致树的高度变高,增加了io次数,显然用这种结构存储数据也是不可取的。
九、B-树
B杠树,千万不要读作B减树了,B-树在是平衡二叉树上进化来的,前面介绍的几种树,每个节点上面只有一个元素,而B-树节点中可以放多个元素,主要是为了降低树的高度。
一棵m阶的B-Tree有如下特性【特征描述的有点绕,看不懂的可以跳过,看后面的图】:
每个节点最多有m个孩子,m称为b树的阶
除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子
若根节点不是叶子节点,则至少有2个孩子
所有叶子节点都在同一层,且不包含其它关键字信息
每个非终端节点包含n个关键字(健值)信息
关键字的个数n满足:ceil(m/2)-1 <= n <= m-1
ki(i=1,…n)为关键字,且关键字升序排序
Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块。为了描述B-Tree,首先定义一条记录为一个二元组[key, data] ,key为记录的键值,对应表中的主键值,data为一行记录中除主键外的数据。对于不同的记录,key值互不相同。
B-Tree中的每个节点根据实际情况可以包含大量的关键字信息和分支,如下图所示为一个3阶的B-Tree:
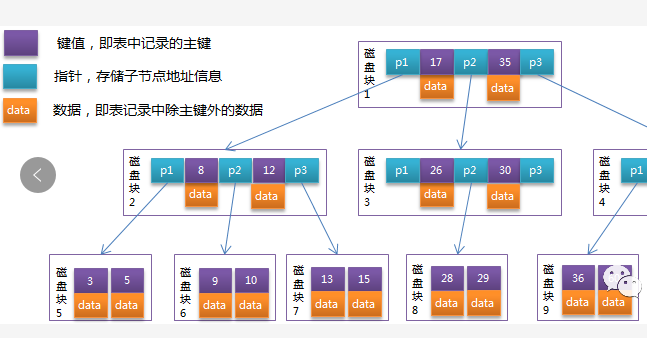
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个键将数据划分成的三个范围域,对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
比较关键字29在区间(17,35),找到磁盘块1的指针P2
根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
比较关键字29在区间(26,30),找到磁盘块3的指针P2
根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
在磁盘块8中的关键字列表中找到关键字29
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作,由于内存中的关键字是一个有序表结构,可以利用二分法快速定位到目标数据,而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。
B-树相对于avl树,通过在节点中增加节点内部数据的个数来减少磁盘的io操作。
上面我们说过mysql是采用页方式来读写数据,每页是16KB,我们用B-树来存储mysql的记录,每个节点对应mysql中的一页(16KB),假如每行记录加上树节点中的1个指针占160Byte,那么每个节点可以存储1000(16KB/160byte)条数据,树的高度为3的节点大概可以存储(第一层1000+第二层1000^2+第三层1000^3)10亿条记录,是不是非常惊讶,一个高度为3个B-树大概可以存储10亿条记录,我们从10亿记录中查找数据只需要3次io操作可以定位到目标数据所在的页,而页内部的数据又是有序的,然后将其加载到内存中用二分法查找,是非常快的。
可以看出使用B-树定位某个值还是很快的(10亿数据中3次io操作+内存中二分法),但是也是有缺点的:B-不利于范围查找,比如上图中我们需要查找[15,36]区间的数据,需要访问7个磁盘块(1/2/7/3/8/4/9),io次数又上去了,范围查找也是我们经常用到的,所以b-树也不太适合在磁盘中存储需要检索的数据。
十、b+树
先看个b+树结构图:
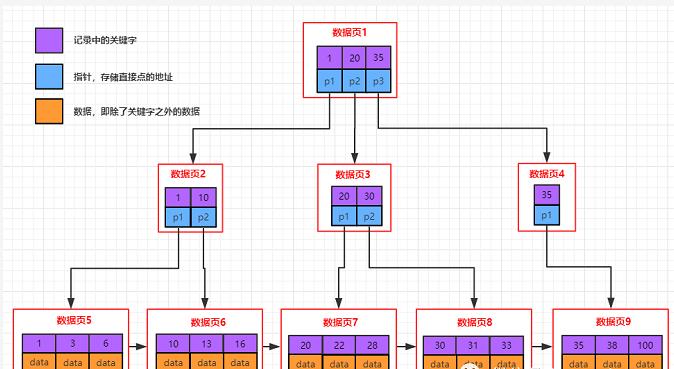
b+树的特征
每个结点至多有m个子女
除根结点外,每个结点至少有[m/2]个子女,根结点至少有两个子女
有k个子女的结点必有k个关键字
父节点中持有访问子节点的指针
父节点的关键字在子节点中都存在(如上面的1/20/35在每层都存在),要么是最小值,要么是最大值,如果节点中关键字是升序的方式,父节点的关键字是子节点的最小值
最底层的节点是叶子节点
除叶子节点之外,其他节点不保存数据,只保存关键字和指针
叶子节点包含了所有数据的关键字以及data,叶子节点之间用链表连接起来,可以非常方便的支持范围查找
b+树与b-树的几点不同
b+树中一个节点如果有k个关键字,最多可以包含k个子节点(k个关键字对应k个指针);而b-树对应k+1个子节点(多了一个指向子节点的指针)
b+树除叶子节点之外其他节点值存储关键字和指向子节点的指针,而b-树还存储了数据,这样同样大小情况下,b+树可以存储更多的关键字
b+树叶子节点中存储了所有关键字及data,并且多个节点用链表连接,从上图中看子节点中数据从左向右是有序的,这样快速可以支撑范围查找(先定位范围的最大值和最小值,然后子节点中依靠链表遍历范围数据)
B-Tree和B+Tree该如何选择?
B-Tree因为非叶子结点也保存具体数据,所以在查找某个关键字的时候找到即可返回。而B+Tree所有的数据都在叶子结点,每次查找都得到叶子结点。所以在同样高度的B-Tree和B+Tree中,B-Tree查找某个关键字的效率更高。
由于B+Tree所有的数据都在叶子结点,并且结点之间有指针连接,在找大于某个关键字或者小于某个关键字的数据的时候,B+Tree只需要找到该关键字然后沿着链表遍历就可以了,而B-Tree还需要遍历该关键字结点的根结点去搜索。
由于B-Tree的每个结点(这里的结点可以理解为一个数据页)都存储主键+实际数据,而B+Tree非叶子结点只存储关键字信息,而每个页的大小有限是有限的,所以同一页能存储的B-Tree的数据会比B+Tree存储的更少。这样同样总量的数据,B-Tree的深度会更大,增大查询时的磁盘I/O次数,进而影响查询效率。
十一、Mysql的存储引擎和索引
mysql内部索引是由不同的引擎实现的,主要说一下InnoDB和MyISAM这两种引擎中的索引,这两种引擎中的索引都是使用b+树的结构来存储的。
InnoDB中的索引
Innodb中有2种索引:主键索引(聚集索引)、辅助索引(非聚集索引)。
主键索引:每个表只有一个主键索引,叶子节点同时保存了主键的值也数据记录。
辅助索引:叶子节点保存了索引字段的值以及主键的值。
MyISAM引擎中的索引
不管是主键索引还是辅助索引结构都是一样的,叶子节点保存了索引字段的值以及数据记录的地址。
InnoDB数据检索过程
如果需要查询id=14的数据,只需要在左边的主键索引中检索就可以了。
如果需要搜索name='Ellison'的数据,需要2步:
先在辅助索引中检索到name='Ellison'的数据,获取id为14
再到主键索引中检索id为14的记录
辅助索引这个查询过程在mysql中叫做回表。
MyISAM数据检索过程
在索引中找到对应的关键字,获取关键字对应的记录的地址
通过记录的地址查找到对应的数据记录
我们用的最多的是innodb存储引擎,所以此处主要说一下innodb索引的情况,innodb中最好是采用主键查询,这样只需要一次索引,如果使用辅助索引检索,涉及到回表操作,比主键查询要耗时一些。
innodb中辅助索引为什么不像myisam那样存储记录的地址?
表中的数据发生变更的时候,会影响其他记录地址的变化,如果辅助索引中记录数据的地址,此时会受影响,而主键的值一般是很少更新的,当页中的记录发生地址变更的时候,对辅助索引是没有影响的。
我们来看一下mysql中页的结构,页是真正存储记录的地方,对应B+树中的一个节点,也是mysql中读写数据的最小单位,页的结构设计也是相当有水平的,能够加快数据的查询。
十二、页结构
mysql中页是innodb中存储数据的基本单位,也是mysql中管理数据的最小单位,和磁盘交互的时候都是以页来进行的,默认是16kb,mysql中采用b+树存储数据,页相当于b+树中的一个节点。
页的结构如下图:
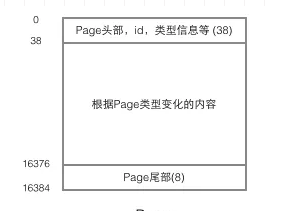
我们重点关注和数据组织结构相关的字段:Page的头部保存了两个指针,分别指向前一个Page和后一个Page,根据这两个指针我们很容易想象出Page链接起来就是一个双向链表的结构。
再看看Page的主体内容,我们主要关注行数据和索引的存储,他们都位于Page的User Records部分,User Records占据Page的大部分空间,User Records由一条一条的Record组成。在一个Page内部,单链表的头尾由固定内容的两条记录来表示,字符串形式的"Infimum"代表开头,"Supremum"代表结尾,这两个用来代表开头结尾的Record存储在System Records的,Infinum、Supremum和User Records组成了一个单向链表结构。最初数据是按照插入的先后顺序排列的,但是随着新数据的插入和旧数据的删除,数据物理顺序会变得混乱,但他们依然通过链表的方式保持着逻辑上的先后顺序.
innodb为了快速查找记录,在页中定义了一个称之为page directory的目录槽(slots),每个槽位占用两个字节(用于保存指向记录的地址),page directory中的多个slot组成了一个有序数组(可用于二分法快速定位记录,向下看),行记录被Page Directory逻辑的分成了多个块,块与块之间是有序的,能够加速记录的查找,如下图:
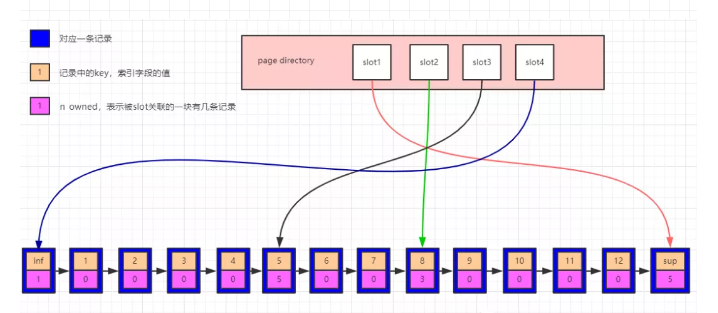
看上图,每个行记录的都有一个n_owned的区域(图中粉色区域),n_owned标识所属的slot这个这个块有多少条数据,伪记录Infimum的n_owned值总是1,记录Supremum的n_owned的取值范围为[1,8],其他用户记录n_owned的取值范围[4,8],并且只有每个块中最大的那条记录的n_owned才会有值,其他的用户记录的n_owned为0。
数据检索过程
在page中查询数据的时候,先通过b+树中查询方法定位到数据所在的页,然后将页内整体加载到内存中,通过二分法在page directory中检索数据,缩小范围,比如需要检索7,通过二分法查找到7位于slot2和slot3所指向的记录中间,然后从slot3指向的记录5开始向后向后一个个找,可以找到记录7,如果里面没有7,走到slot2向的记录8结束。
n_owned范围控制在[4,8]内,能保证每个slot管辖的范围内数据量控制在[4,8]个,能够加速目标数据的查找,当有数据插入的时候,page directory为了控制每个slot对应块中记录的个数([4,8]),此时page directory中会对slot的数量进行调整。
对page的结构总结一下
b+树中叶子页之间用双向链表连接的,能够实现范围查找
页内部的记录之间是采用单向链表连接的,方便访问下一条记录
为了加快页内部记录的查询,对页内记录上加了个有序的稀疏索引,叫页目录(page directory)
整体上来说mysql中的索引用到了b+树,链表,二分法查找,做到了快速定位目标数据,快速范围查找。
二十二、mysql索引原理详解的更多相关文章
- 二十三、mysql索引管理详解
一.索引分类 分为聚集索引和非聚集索引. 聚集索引 每个表有且一定会有一个聚集索引,整个表的数据存储在聚集索引中,mysql索引是采用B+树结构保存在文件中,叶子节点存储主键的值以及对应记录的数据,非 ...
- mysql进阶(二十六)MySQL 索引类型(初学者必看)
mysql进阶(二十六)MySQL 索引类型(初学者必看) 索引是快速搜索的关键.MySQL 索引的建立对于 MySQL 的高效运行是很重要的.下面介绍几种常见的 MySQL 索引类型. 在数 ...
- 0614MySQL的InnoDB索引原理详解
转自http://www.cnblogs.com/shijingxiang/articles/4743324.html MySQL的InnoDB索引原理详解 http://www.admin10000 ...
- (转)MySQL备份原理详解
MySQL备份原理详解 原文:http://www.cnblogs.com/cchust/p/5452557.html 备份是数据安全的最后一道防线,对于任何数据丢失的场景,备份虽然不一定能恢复百分之 ...
- 渗透测试学习 二十八、WAF绕过详解
大纲: WAF防护原理讲解 目录扫描绕过WAF 手工注入绕过WAF sqlmap绕过WAF 编写salmap绕过WAF 过WAF一句话编写讲解 菜刀连接绕过WAF webshell上传绕过WAF 提权 ...
- MySQL的InnoDB索引原理详解
摘要 本篇介绍下Mysql的InnoDB索引相关知识,从各种树到索引原理到存储的细节. InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM,文档).本着高效学习的目的,本篇 ...
- MySQL的InnoDB索引原理详解 (转)
摘要: 本篇介绍下Mysql的InnoDB索引相关知识,从各种树到索引原理到存储的细节. InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM,文档).本着高效学习的目的,本 ...
- Redis进阶实践之二十 Redis的配置文件使用详解
一.引言 写完上一篇有关redis使用lua脚本的文章,就有意结束Redis这个系列的文章了,当然了,这里的结束只是我这个系列的结束,但是要学的东西还有很多.但是,好多天过去了,总是感觉好像还缺点什么 ...
- MySQL索引优化详解
MySQL存储引擎简介 查看命令 a. 查看所使用的MySQL现在已提供什么存储引擎: mysql> show engines; b. 查看所使用的MySQL当前默认的存储引擎: mysql&g ...
随机推荐
- Spring cloud微服务安全实战-7-7自定义metrics监控指标(2)
Gauge用来显示单词一个数的 勾选,这里编程仪表盘 设置仪表盘的最大值.最小值 保存 直接保存 保存成功的提示 返回 这就是我们做的一个简单的仪表盘 这个不适合我们的counter,因为没有最大值 ...
- PAT 甲级 1077 Kuchiguse (20 分)(简单,找最大相同后缀)
1077 Kuchiguse (20 分) The Japanese language is notorious for its sentence ending particles. Person ...
- HTML-头部
HTML <head> 元素 <head> 元素是所有头部元素的容器.<head> 内的元素可包含脚本,指示浏览器在何处可以找到样式表,提供元信息,等等. 以下标签 ...
- express下使用ES6
//环境切换配置 package.json scripts:{ "service": "NODE_ENV=production PORT=3000 npm start&q ...
- [LeetCode] 342. Power of Four 4的次方数
Given an integer (signed 32 bits), write a function to check whether it is a power of 4. Example:Giv ...
- Kubernetes Pod应用的滚动更新(八)
一.环境准备 我们紧接上一节的环境,进行下面的操作,如果不清楚的,可以先查看上一篇博文. 滚动更新是一次只更新一小部分副本,成功后,再更新更多的副本,最终完成所有副本的更新.滚动更新的最大的好处是零停 ...
- polynomial&generating function学习笔记
生成函数 多项式 形如$\sum_{i=0}^{n}a_i x^i$的代数式称为n阶多项式 核函数 {ai}的核函数为f(x),它的生成函数为sigma(ai*f(i)*x^i) 生成函数的加减 {a ...
- Android Capabilities讲解
1.Capabilities介绍 可以看下之前代码里面设置的capabilities DesiredCapabilities capabilities =newDesiredCapabilities( ...
- 在ensp中RSTP基础设置
为什么我们要有rstp? rstp就是stp的加强版 实验模拟内容 搭建拓扑 相关参数(实验的时候看看自己的mac地址可能与我的并不同) 我们开始配置RSTP基本功能,由于交换机默认开启MSTP,所有 ...
- 微信小程序之自定义导航栏(可实现动态添加)以及swiper(swiper-item)实现自动切换,导航标题也跟着切换
<view class="movie-container"> <!-- 导航栏 --> <view > <scroll-view scro ...