分布式系统中我们会对一些数据量大的业务进行分拆,分布式系统中唯一主键ID的生成问题
分布式全局唯一ID生成策略
https://www.cnblogs.com/vandusty/p/11462585.html
一、背景
分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表。因为数据量巨大一张表无法承接,就会对其进行分库分表。
但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题。
1.1 唯一ID的特性
- 整个系统
ID唯一; - ID是数字类型,而且是趋势递增;
- ID简短,查询效率快。
1.2 递增与趋势递增
| 递增 | 趋势递增 |
|---|---|
| 第一次生成的ID为12,下一次生成的ID是13,再下一次生成的ID是14。 | 什么是?如:在一段时间内,生成的ID是递增的趋势。如:再一段时间内生成的ID在【0,1000】之间,过段时间生成的ID在【1000,2000】之间。但在【0-1000】区间内的时候,ID生成有可能第一次是12,第二次是10,第三次是14。 |
二、方案
2.1 UUID
UUID全称:Universally Unique Identifier。标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:9628f6e9-70ca-45aa-9f7c-77afe0d26e05。
- 优点:
- 代码实现简单;
- 本机生成,没有性能问题;
- 因为是全球唯一的
ID,所以迁移数据容易。
- 缺点:
- 每次生成的
ID是无序的,无法保证趋势递增; UUID的字符串存储,查询效率慢;- 存储空间大;
ID本身无业务含义,不可读。
- 应用场景:
- 类似生成token令牌的场景;
- 不适用一些要求有趋势递增的ID场景,不适合作为高性能需求的场景下的数据库主键。
也有在线生成
UUID的网站,如果你的项目上用到了UUID,可以用来生成临时的测试数据。https://www.uuidgenerator.net/
2.2 MySQL主键自增
利用了MySQL的主键自增auto_increment,默认每次ID加1。
优点:
- 数字化,
ID递增; - 查询效率高;
- 具有一定的业务可读。
- 缺点:
- 存在单点问题,如果
MySQL挂了,就没法生成ID了; - 数据库压力大,高并发抗不住。
2.3 MySQL多实例主键自增
这个方案就是解决MySQL的单点问题,在auto_increment基本上面,设置step步长
如上,每台的初始值分别为1,2,3...N,步长为N(这个案例步长为4)
- 优点:解决了单点问题;
- 缺点:一旦把步长定好后,就无法扩容;而且单个数据库的压力大,数据库自身性能无法满足高并发。
- 应用场景:数据不需要扩容的场景。
2.4 基于Redis实现
单机:
Redis的incr函数在单机上是原子操作,可以保证唯一且递增。集群:单机
Redis可能无法支撑高并发。集群情况下,可以使用步长的方式。比如有5个Redis节点组成的集群,它们生成的ID分别为:
A: 1,6,11,16,21
B: 2,7,12,17,22
C: 3,8,13,18,23
D: 4,9,14,19,24
E: 5,10,15,20,25- 优点:有序递增,可读性强。
- 缺点:占用带宽,每次要向
Redis进行请求。
三、优化方案
3.1、改造数据库主键自增
数据库的自增主键的特性,可以实现分布式ID,适合做userId,正好符合如何永不迁移数据和避免热点? 但这个方案有严重的问题:
- 一旦步长定下来,不容易扩容;
- 数据库压力山大。
- 为什么压力大?
因为我们每次获取ID的时候,都要去数据库请求一次。那我们可以不可以不要每次去取?
可以请求数据库得到ID的时候,可设计成获得的ID是一个ID区间段。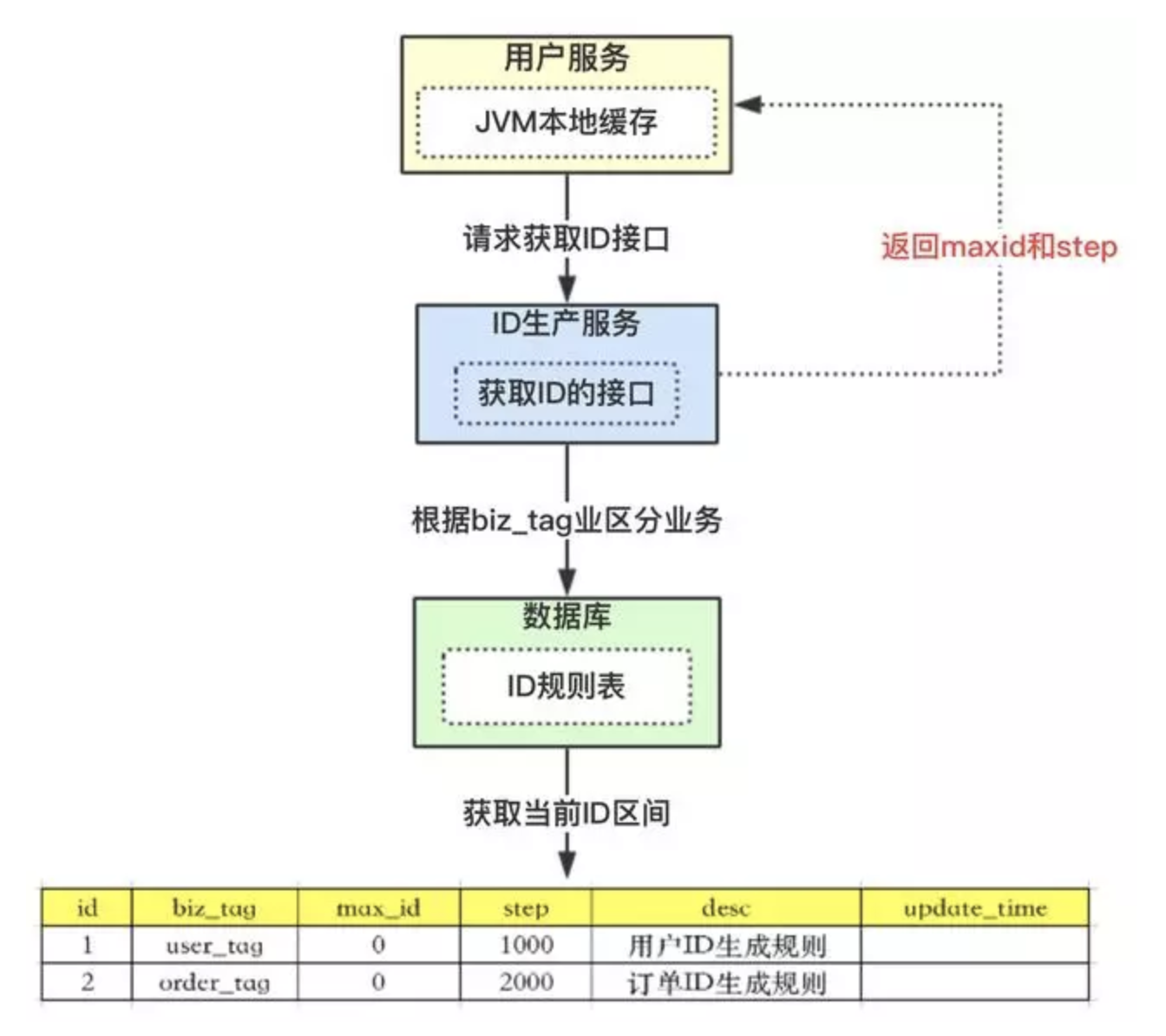
- 上图
ID规则表含义:
id表示为主键,无业务含义;biz_tag为了表示业务,因为整体系统中会有很多业务需要生成ID,这样可以共用一张表维护;max_id表示现在整体系统中已经分配的最大ID;desc描述;update_time表示每次取的ID时间;
- 整体流程:
- 【用户服务】在注册一个用户时,需要一个用户
ID;会请求【生成ID服务(是独立的应用)】的接口; - 【生成
ID服务】会去查询数据库,找到user_tag的id,现在的max_id为0,step=1000; - 【生成
ID服务】把max_id和step返回给【用户服务】;并且把max_id更新为max_id = max_id + step,即更新为1000; - 【用户服务】获得
max_id=0,step=1000; - 这个用户服务可以用
ID=【max_id + 1,max_id+step】区间的ID,即为【1,1000】; - 【用户服务】会把这个区间保存到
jvm中; - 【用户服务】需要用到
ID的时候,在区间【1,1000】中依次获取ID,可采用AtomicLong中的getAndIncrement方法; 如果把区间的值用完了,再去请求【生产
ID服务】接口,获取到max_id为1000,即可以用【max_id + 1,max_id+step】区间的ID,即为【1001,2000】。- 该方案就非常完美的解决了数据库自增的问题,而且可以自行定义
max_id的起点,和step步长,非常方便扩容; 也解决了数据库压力的问题,因为在一段区间内,是在
jvm内存中获取的,而不需要每次请求数据库。即使数据库宕机了,系统也不受影响,ID还能维持一段时间。
3.2 竞争问题
以上方案中,如果是多个用户服务,同时获取ID,同时去请求【ID服务】,在获取max_id的时候会存在并发问题。如:
用户服务
A,取到的max_id=1000;用户服务B取到的也是max_id=1000,那就出现了问题,ID重复了。
解决方案是:加分布式锁,保证同一时刻只有一个用户服务获取max_id。
3.3 突发阻塞问题
因为竞争问题,所有只有一个用户服务去操作数据库,其他二个会被阻塞。出现的现象就是一会儿突然系统耗时变长,怎么去解决?
- 双
buffer方案
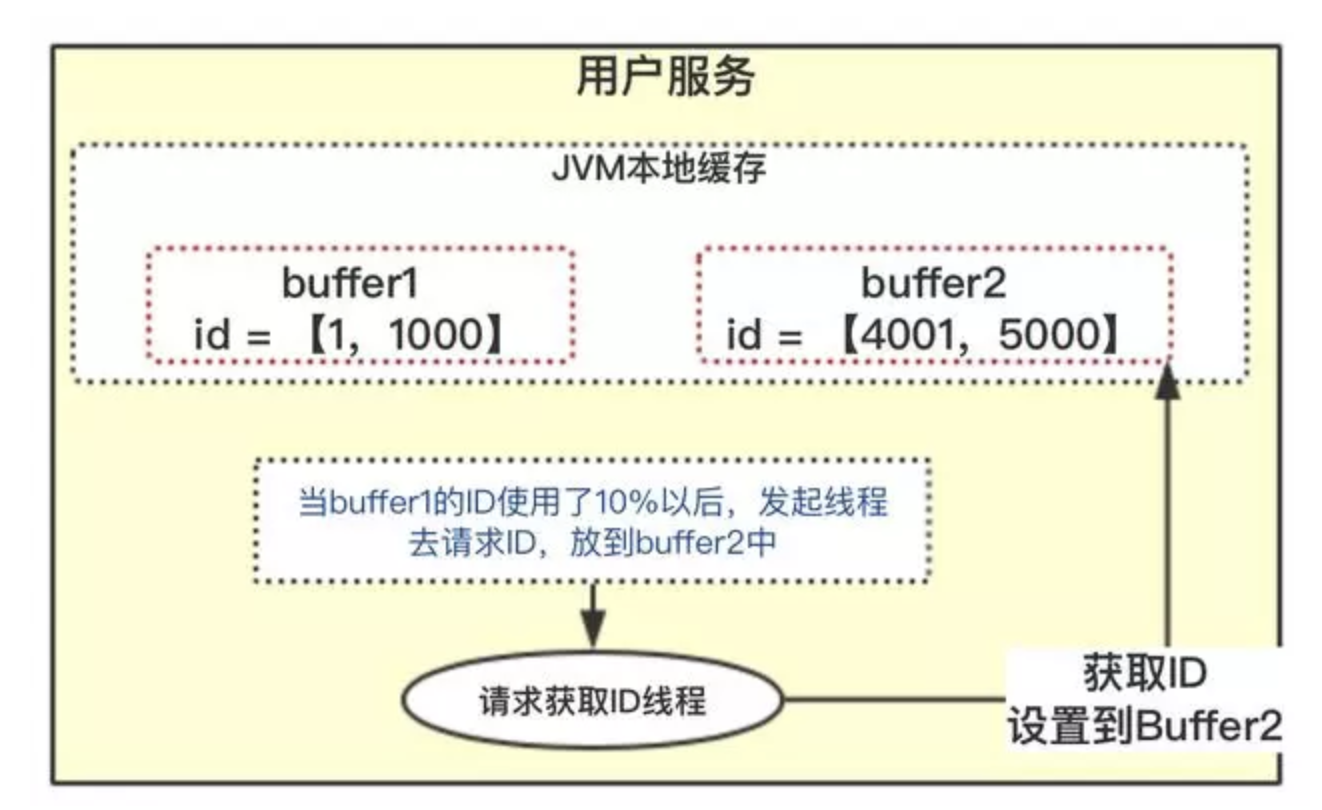
流程如下:
- 当前获取
ID在buffer1中,每次获取ID在buffer1中获取; - 当
buffer1中的ID已经使用到了100,也就是达到区间的10%; - 达到了
10%,先判断buffer2中有没有去获取过,如果没有就立即发起请求获取ID线程,此线程把获取到的ID,设置到buffer2中; - 如果
buffer1用完了,会自动切换到buffer2; buffer2用到10%了,也会启动线程再次获取,设置到buffer1中;- 依次往返。
3.4 总结
- 双
buffer的方案就达到了业务场景用的ID,都是在jvm内存中获得的,从此不需要到数据库中获取了,数据库宕机时长长点儿也没太大影响了。 - 因为会有一个线程,会观察什么时候去自动获取。两个
buffer之间自行切换使用,就解决了突发阻塞的问题。 - 如果用户服务A的本地缓存丢失了,重启以后这个区间的ID是不是都丢失了呢?因为再次获取是新的区间了吧。我觉得数据库存一个当前表的最大ID,ID服务每次启动获取这个最大ID并缓存,每个请求都直接加锁从内存+1返回也很快,再把当前最大ID推到队列同步到数据库(可以控制频率)
四、其他方式
还有一些其他的ID生成方案,比如:
- 滴滴:时间+起点编号+车牌号;
- 淘宝订单:时间戳+用户
ID - 其他电商:时间戳+下单渠道+用户
ID,有的会加上订单第一个商品的ID; MongoDB的ID:通过时间+机器码+pid+inc共12个字节,4+3+2+3的方式最终标识成一个24长度的十六进制字符。
分布式系统中我们会对一些数据量大的业务进行分拆,分布式系统中唯一主键ID的生成问题的更多相关文章
- 使用POI导出EXCEL工具类并解决导出数据量大的问题
POI导出工具类 工作中常常会遇到一些图表需要导出的功能,在这里自己写了一个工具类方便以后使用(使用POI实现). 项目依赖 <dependency> <groupId>org ...
- C#中使用MySqlCommand执行插入语句后获取该数据主键id值的方法
.net中要连接mysql数据库,需要引用MySql.Data.dll文件,这文件在mysql官网上有下载. 接着通过MySqlCommand执行插入语句后想要获取该数据主键id值的方法如下: lon ...
- 关于dedecms数据量大以后生成目录缓慢的问题解决
四月份的时候博客被封.我不知情.因为一直很忙,没有来得及看.前两天来看以后,发现居然被封,吓傻了我. 赶紧找原因,原来是转载了某个人的博文,被他举报了,然后就被封了. 觉得很伤心,毕竟这个博客陪伴了我 ...
- myBatis获取批量插入数据的主键id
在myBatis中获取刚刚插入的数据的主键id是比较容易的 , 一般来说下面的一句话就可以搞定了 , 网上也有很多相关资料去查. @Options(useGeneratedKeys = true, k ...
- Django 用散列隐藏数据库中主键ID
最近看到了一篇讲Django性能测试和优化的文章, 文中除了提到了很多有用的优化方法, 演示程序的数据库模型写法我觉得也很值得参考, 在这单独记录下. 原文的演示代码有些问题, 我改进了下, 这里可以 ...
- 使用mybatis插入自增主键ID的数据后返回自增的ID
在开发中碰到用户注册的功能需要用到用户ID,但是用户ID是数据库自增生成的,这种情况上网查询后使用下面的方式配置mybatis的insert语句可以解决: <insert id="in ...
- Mybatis 中获取添加的自增主键ID(针对mysql)
分享一篇博客,主要就是针对在我们使用SSM的时候,在.xml中获取<insert></insert> 时的自增主键Id,由于好久没有,这个时候使用,有点生疏,就在这里写个笔记, ...
- 高并发分布式环境中获取全局唯一ID[分布式数据库全局唯一主键生成]
需求说明 在过去单机系统中,生成唯一ID比较简单,可以使用MySQL的自增主键或者Oracle中的sequence, 在现在的大型高并发分布式系统中,以上策略就会有问题了,因为不同的数据库会部署到不同 ...
- mybatis插入数据后返回自增主键ID详解
1.场景介绍: 开发过程中我们经常性的会用到许多的中间表,用于数据之间的对应和关联.这个时候我们关联最多的就是ID,我们在一张表中插入数据后级联增加到关联表中.我们熟知的mybatis在插入数据后 ...
随机推荐
- 我为什么学习Haskell
说起来,Haskell真是相当冷门而小众的一门语言.在我工作第一年的时候,我平时从网络的一些学习资料上时不时看到有人提到这门语言.那时候的认识就是除了我们平时用的“面向对象语言 (OOP: Objec ...
- LIBRARY_PATH和LD_LIBRARY_PATH
LIBRARY_PATH是编译时指定的路径. LD_LIBRARY_PATH是运行时指定的动态链接库所在目录. 在运行一个可执行文件之前,可以通过ldd a.exe命令查看a.exe所依赖的动态链接库 ...
- git操作:撤销更改的文件
在没有git add之前: #撤销所有更改 git checkout . #撤销指定文件的更改 git checkout -- myfile.txt 在git add之后: git reset HEA ...
- Win10 默认用Windows照片查看程序打开图片
::复制以下内容到记事本: @echo off&cd\&color 0a&cls echo 恢复Win10照片查看器 reg add "HKLM\SOFTWARE\M ...
- windows,linux里的hosts文件
在解析主机名的IP地址时,会先访问本机的上hosts文件,这样先配置好就可以不通过DNS服务器就获得IP地址. linux vi /etc/hosts IP 空格 主机名 windows C:\Wi ...
- MySQL复制技术
MySQL高可用方案 投票选举机制,较复杂 MySQL本身没有提供replication failover的解决方案,自动切换需要依赖MHA脚本 可以有多台从库,从库可以做报表和备份 MySQL复制技 ...
- 201871010109-胡欢欢《面向对象程序设计(java)》第二周学习总结
开头: 项目 内容 这个作业属于哪个课程 <任课教师博客主页链接> https://www.cnblogs.com/nwnu-daizh/ 这个作业的要求在哪里 <作业链接地 ...
- Android APK开发 Drawable文件夹下的自定义Drawable文件
版本:2018/2/11 Drawable的分类 自定义Drawable SVG矢量图 个人总结的知识点外,部分知识点选自<Android开发艺术探索>-第六章 Drawable 1.Dr ...
- mybatis框架,使用foreach实现复杂结果的查询--循环集合数组
需求:假定现在查询出用户角色是2和3指定的用户列表信息,并进行展示 接口: /** * 需求:传入指定的用户角色,用户角色有1-n,获取这些用户角色下的用户列表信息 * @param roleids ...
- python 识别二维码内容的方法
识别二维码链接的方式有多种,那么如何用python 的方法实现识别呢? 请看如下代码: from pyzbar.pyzbar import decode from PIL import Image i ...