Redis实现实时热点查询
Redis内存淘汰
定义:
指的是用户存储的一些键被可以被Redis主动地从实例中删除,从而产生读miss的情况
机制存在原因:
Redis最常见的两种应用场景为缓存和持久存储
首先要明确的一个问题是内存淘汰策略更适合于那种场景?是持久存储还是缓存?
内存的淘汰机制的初衷是为了更好地使用内存,用一定的缓存miss来换取内存的使用效率。
作为Redis用户,我如何使用Redis提供的这个特性呢?看看下面配置
配置文件
我们可以通过配置redis.conf中的maxmemory这个值来开启内存淘汰功能,此外可以选择设置淘汰策略maxmemory-policy
maxmemory的意义:
客户端发起了需要申请更多内存的命令(如set)。
Redis检查内存使用情况,如果已使用的内存大于maxmemory ,则开始根据用户配置的不同淘汰策略来淘汰内存(key),从而换取一定的内存。
如果上面都没问题,则这个命令执行成功。
maxmemory值即意义,默认的策略为noeviction策略:
0:为0表示我们对Redis的内存使用没有限制。
noeviction:当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
allkeys-lru:在主键空间中,优先移除最近未使用的key。
volatile-lru:在设置了过期时间的键空间中,优先移除最近未使用的key。
allkeys-random:在主键空间中,随机移除某个key。
volatile-random:在设置了过期时间的键空间中,随机移除某个key。
volatile-ttl:在设置了过期时间的键空间中,具有更早过期时间的key优先移除。
什么是主键空间和设置了过期时间的键空间,举个例子,
当有一批键存储在Redis中,就会生成一张哈希存储这批键及其值。
此外某些键设置了过期时间,就会存储到另外一个哈希表中,这个哈希表中的值对应的是键被设置的过期时间。设置了过期时间的键空间为主键空间的子集。
maxmemory-policy值即意义、适用场景
但是这个值填什么呢?为解决这个问题,我们需要了解我们的应用请求对于Redis中存储的数据集的访问方式以及我们的诉求是什么。
同时Redis也支持Runtime修改淘汰策略,这使得我们不需要重启Redis实例而实时的调整内存淘汰策略。0
allkeys-lru:如果我们的应用对缓存的访问符合幂律分布(也就是存在相对热点数据),或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择allkeys-lru策略。
allkeys-random:如果我们的应用对于缓存key的访问概率相等,则可以使用这个策略。
volatile-ttl:这种策略使得我们可以向Redis提示哪些key更适合被eviction。
另外,volatile-lru策略和volatile-random策略,适合我们将一个Redis实例既应用于缓存和又应用于持久化存储的时候,然而我们也可以通过使用两个Redis实例来达到相同的效果,值得一提的是将key设置过期时间实际上会消耗更多的内存,因此我们建议使用allkeys-lru策略从而更有效率的使用内存。
Redis的存储机制有两种AOF Snapshot
Snapshot工作原理:
将数据先存储在内存,然后当数据累计达到某些设定的伐值的时候,就会触发一次DUMP操作,将变化的数据一次性写入数据文件(RDB文件)。
AOF 工作原理:
将数据先存在内存,但是在存储的时候会使用调用fsync来完成对本次写操作的日志记录(一个基于Redis网络交互协议的文本文件)。
AOF调用fsync也不是说全部都是无阻塞的,在某些系统上可能出现fsync阻塞进程的情况,对于这种情况可以通过配置修改,但默认情况不要修改。
AOF最关键的配置就是关于调用fsync追加日志文件的频率(有两种),两个配置各有所长后面分析。
由于是采用日志追加的方式来持久化数据,所以引出了第二个日志的概念:rewrite. 后面介绍它的由来。
存储模式性能和安全比较:
(1)在性能上,Snapshot方式的性能是要明显高于AOF方式的,原因有两点:
a Snapshot采用2进制方式存储数据,数据文件比较小,加载快速.
b 存储的时候是按照配置中的save策略来存储,每次都是聚合很多数据批量存储,写入的效率很好,而AOF则一般都是工作在实时存储或者准实时模式下。相对来说存储的频率高,效率却偏低。
(2)数据安全:AOF数据安全性高于Snapshot存储,原因:
Snapshot存储是基于累计批量的思想, 也就是说在允许的情况下,累计的数据越多那么写入效率也就越高, 但是数据的累计是靠时间的积累完成的, 如果数据长时间不写入RDB,Redis又遇到了崩溃,那么没有写入的数据就无法恢复了。
AOF方式偏偏相反,根据AOF配置的存储频率的策略可以做到最少的数据丢失和较高的数据恢复能力。
Redis中的Rewrite的功能
AOF的存储是按照记录日志的方式去工作的,那么成千上万的数据插入必然导致日志文件的扩大,Redis这个时候会根据配置合理触发Rewrite操作。
所谓Rewrite就是将日志文件中的所有数据都重新写到另外一个新的日志文件中,但是不同的是,对于老日志文件中对于Key的多次操作,只保留最终的值的那次操作记录到日志文件中,从而缩小日志文件的大小。
这里有两个配置需要注意(两个条件需要同时满足。):
auto-aof-rewrite-percentage 100 (当前写入日志文件的大小占到初始日志文件大小的某个百分比时触发Rewrite)
auto-aof-rewrite-min-size 64mb (本次Rewrite最小的写入数据良)
Redis内存优化理解
(1)string和int存储优化:
在Redis中如果存储的是“123”,Redis是能够识别出来这是一个数字并且按照数字来存储,节省存储空间。
当然除了这个优化之外,Redis内部会构建一个数字池,默认是10000,如果是在这个池子的数字就只需要用一个简单的索引来引用进来就可以,而不需要把重复的数字都分开存储。数字池的大小可以调整源代码的宏:REDIS_SHARED_INTEGERS来扩大和缩小池子的大小。
(2)复杂类型的存储优化,比如Map,List,Set等。
这些集合都有一个特点可大可小,根据实际场景来定,一般情况下如果这些集合所包含的Entry不多,并且每个Entry所包含的Value不是很长的情况下,Redis内部使用紧凑格式来存储数据,紧凑格式存储数据在查询场景的算法复杂度是O(N),而类似Map或者Set他们的查询算法复杂度都是O(1)那为什么要这么做呢 ?
为了能够节省内存空间,在N很小的时候其实和O(1)没什么区别。所以这里不的不介绍紧凑格式的代表ZIPMap,他的数据结构是这样:
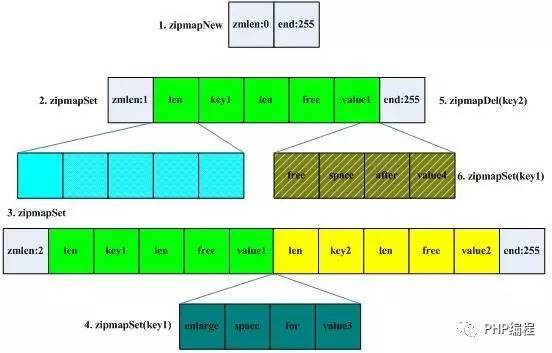
可以看出,这个结构中初始情况只有2个字节,随着操作的增加它会变长,其中最关键的是一个关于Free这个字段的理解,以Map为例,如果新插入一个Key,那么对应ZipMap就会多出来一长串数据:。从图中可以看到插入key1的时候只有绿色的一串,当key2插入的时候就会又出来一个类似的黄色结构串。
free的功能是在插入的时候用来冗余空间的,当key所对应的数值发生变化的时候,如果数据变的比之前短了,那么free的长度就变大,这个时候不需要做ZipMap的resize操作,如果数据长度变长了,并且在free能够足以支持新数据的范围之内,那么free就被利用起来,并且也不需要做Resize。这个时候会有空间的浪费或者说碎片。空间换时间,没什么好说的。当然Redis的代码中还有另外一个参数ZIPMAP_VALUE_MAX_FREE,这个参数可以用来设置如果Free的大小超过了这个值,那么ZipMap会发生Resize(收缩),从而节约空间
文章参考
(1)《Redis淘汰机制》 https://blog.csdn.net/fengyuhan123/article/details/81773888
Redis实现实时热点查询的更多相关文章
- 双汇大数据方案选型:从棘手的InfluxDB+Redis到毫秒级查询的TDengine
双汇发展多个分厂的能源管控大数据系统主要采用两种技术栈:InfluxDB/Redis和Kafka/Redis/HBase/Flink,对于中小型研发团队来讲,无论是系统搭建,还是实施运维都非常棘手.经 ...
- Redis 如何分析慢查询操作?
什么是慢查询 和mysql的慢SQL日志分析一样,redis也有类似的功能,来帮助定位一些慢查询操作. Redis slowlog是Redis用来记录查询执行时间的日志系统. 查询执行时间指的是不包括 ...
- 阿里云 oss实时日志查询
实时日志查询 更新时间:2019-01-29 10:31:49 编辑 · 本页目录 开启实时日志查询 查询实时日志 参考文档 用户在访问 OSS 的过程中,会产生大量的访问日志.实时日志查询功能将 O ...
- jQuery搜索框输入实时进行查询
在手机上,我们期望在搜索框中输入数据,能够实时更新查询出来的内容,不需要按回车. 实现方式为: $(".search").bind("input propertychan ...
- 基于Redis、Storm的实时数据查询实践
通过算法小组给出的聚合文件,我们需要实现一种业务场景,通过用户的消费地点的商户ID与posId,查询出他所在的商圈,并通过商圈地点查询出与该区域的做活动的商户,并与之进行消息匹配,推送相应活动信息到用 ...
- 缓存雪崩、穿透如何解决,如何确保Redis只缓存热点数据?
缓存雪崩如何解决? 缓存穿透如何解决? 如何确保Redis缓存的都是热点数据? 如何更新缓存数据? 如何处理请求倾斜? 实际业务场景下,如何选择缓存数据结构 缓存雪崩 缓存雪崩简单说就是所有请求都从缓 ...
- 用Kibana和logstash快速搭建实时日志查询、收集与分析系统
Logstash是一个完全开源的工具,他可以对你的日志进行收集.分析,并将其存储供以后使用(如,搜索),您可以使用它.说到搜索,logstash带有一个web界面,搜索和展示所有日志. kibana ...
- 使用Redis实现实时排行榜
游戏中存在各种各样的排行榜,比如玩家的等级排名.分数排名等.玩家在排行榜中的名次是其实力的象征,位于榜单前列的玩家在虚拟世界中拥有无尚荣耀,所以名次也就成了核心玩家的追求目标. 一个典型的游戏排行榜包 ...
- 利用Redis cache优化app查询速度实践
注意:本篇文章译自speeding up existing app with a redis cache,如需要转载请注明出处. 发现问题 在应用解决方法之前,我们需要对我们面对的问题有一个清晰的认识 ...
随机推荐
- (21) 树莓派使用python调用命令行 python中调用linux命令及os.system的返回值
cmd = "sudo shutdown -h now"; os.system(cmd)
- Hibernate——离线查询
1.Criteria查询方式: (1)一般方式: 缺点:每一次查询dao层都需要书写对应的方法,离线查询可以解决这个问题. (2)离线方式: 2.离线查询 用DetachedCriteria来构造查询 ...
- 我的.NET之路
有时感觉知识比较零散,做个总结形成自己的知识体系,方便查阅[持续更新...] C#语法特性 .Net FrameWork发展史 C# 语言版本发展史 1.NET体系结构 [C#与.NET的关系.公共语 ...
- eclipse隐藏的列编辑
作为开发人员,应该大部分都懂列编辑模式,最早接触使用列编辑模式是用UE,后来用了notepad++,列编辑模式也很顺手. 以前用eclipse编辑代码想用列编辑时还以为它不支持就打开notepad++ ...
- 【luoguP3000】 [USACO10DEC]牛的健美操Cow Calisthenics
题目链接 二分答案,判断需要断几条边,用\(f[i]\)表示以\(i\)为根的子树断边后的最长路径,对于一个点\(u\),存在\(f[v]>mid\)时就删到\(v\)的边\(f[v1]+f[v ...
- 第10组 Alpha冲刺(4/4)
队名:凹凸曼 组长博客 作业博客 组员实践情况 童景霖 过去两天完成了哪些任务 文字/口头描述 继续学习Android studio和Java 制作剩余界面前端 展示GitHub当日代码/文档签入记录 ...
- Java 整数间的除法运算如何保留所有小数位?
1.情景展示 double d = 1/10; System.out.println(d); 返回的结果居然是0.0!这是怎么回事儿? 2.原因分析 第一步:你会发现用运算结果也可以用int类型接 ...
- c# 画正态分布图
/// <summary> /// 提供正态分布的数据和图片 /// </summary> public class StandardDistribution { /// &l ...
- 【Beta】Scrum meeting 9
目录 写在前面 进度情况 任务进度表 Beta-1阶段燃尽图 遇到的困难 照片 commit记录截图 文档集合仓库 后端代码仓库 技术博客 写在前面 例会时间:5.13 22:30-22:45 例会地 ...
- SpringBoot激活profiles
多环境是最常见的配置隔离方式之一,可以根据不同的运行环境提供不同的配置信息来应对不同的业务场景,在SpringBoot内支持了多种配置隔离的方式,可以激活单个或者多个配置文件. 激活Profiles的 ...