(转载)Universal Correspondence Network
转载自:Chris Choy's blog
Universal Correspondence Network
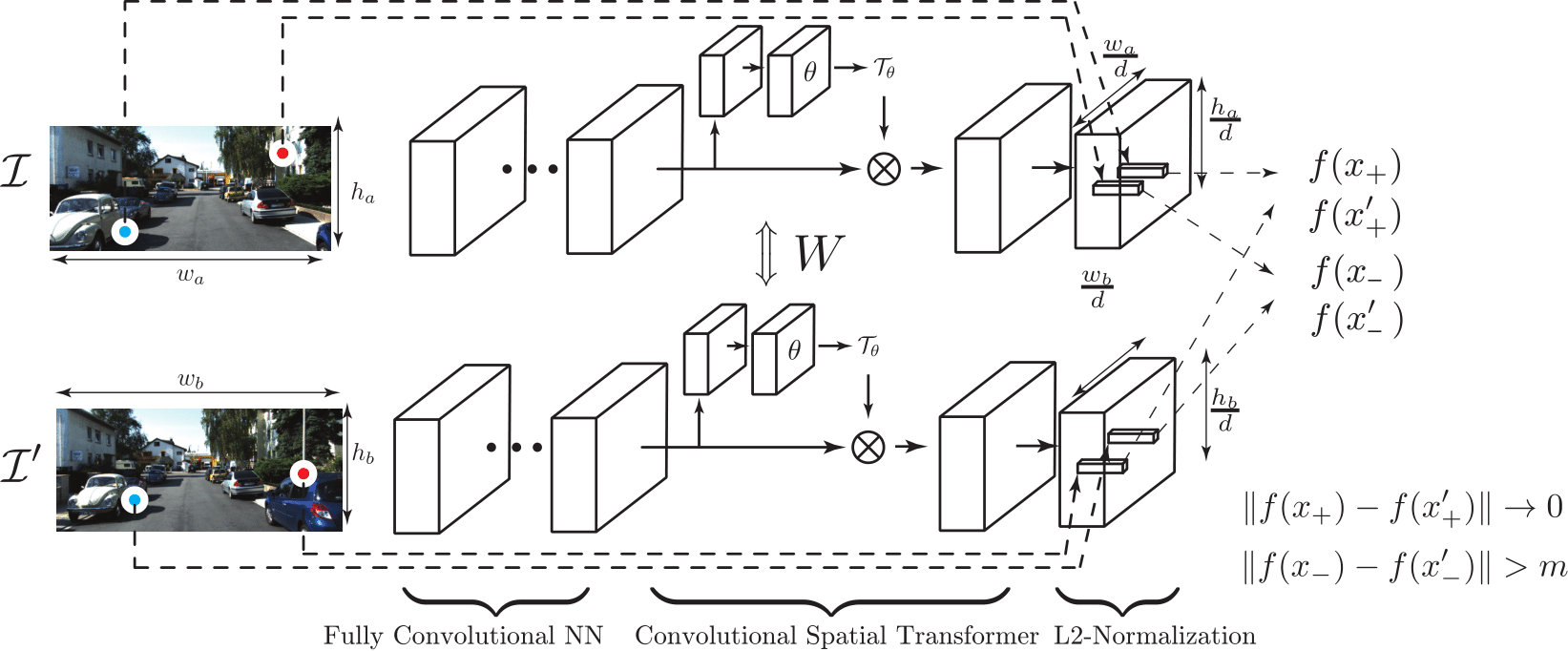
In this post, we will give a very high-level overview of the paper in layman’s terms. I’ve received some questions regarding what the Universal Correspondence Network (UCN) is and the limitations of it. This post will answer some of the questions and hopefully facilitate research on derivatives applications of correspondences.
Patch Similarity
Measuring the similarity of image patches is a basic element of high level operations, such as 3D reconstruction, tracking, registration, etc. The most common and widely used patch similarity is probably “geometric similarity”. In the geometric similarity, we are interested in finding image patches from two different cameras of the same 3D point.
For instance, in stereo vision, we are observing a scene from two different cameras. Since the cameras are placed a certain distance apart, images from two cameras give us different observations of the same scene. We are interested in finding image patches from respective viewpoints that correspond to the same 3D point in the scene.
Another type of similarity is “semantic correspondence”. As the name suggests, in this problem, we are interested in finding the same semantic parts. For instance a left paw of a dog and a left paw of a cat are semantically, and functionally equivalent. In the semantic similarity, we are interested in finding image patches of the same semantic object.
Measuring Patch Similarity
Traditionally, measuring similarity is done by measuring the distance of features extracted from corresponding image patches. However, such features require a lot of hand design and heuristics which results in sub-optimal performance. After the series of successes of CNNs on replacing a lot of hand-designed steps in Computer Vision applications, CNN-base similarity measures have been introduced as well.
In CNN base patch similarity measure, a Convolutional Neural Network takes two image patches as inputs and generates a score that measures the likelihood of the patch similarity. However, since the network has to take both patches, the time complexity of the comparison is O(N2)O(N2) where NN is the number of patches.
Instead, some methods cache the CNN outputs for each patch and only use Fully Connected layer feed forward passes O(N2)O(N2) times. Still, the neural network feed forward passes are expensive compare to simple distance operations.
Another type of CNN uses intermediate FC outputs as surrogate features, but metric operations (distance) on this space is not defined. In another word, the target task of such neural networks is based on metric operation (distance), but the neural network does not know the concept when it is trained.
Universal Correspondence Network
To improve all of points mentioned in the previous section, we propose incorporating three concepts into a neural network.
- Deep Metric Learning for Patch Similarity
- Fully Convolutional Feature Extraction
- Convolutional Spatial Transformer
Deep Metric Learning for Patch Similarity
To minimize the number of CNN feed forward passes, many researchers introduced various techniques. In this paper, we propose using deep metric learning for patch similarity. Metric Learning is a type of learning algorithm that allows the ML model to form a metric space where metric operations are interpretable (i.e. distance). In essence, metric learning starts from a set of constraints that forces similar objects to be closer to each other and dissimilar objects to be at least a margin apart. Since the distance operations are encoded in the learning, using distance during testing (target task) yields meaningful results.
(Disclaimer) During the review process, Li et al.1 independently proposed combining metric learning with a neural network for patch similarity. However, the network is geared toward reconstruction framework and uses patch-wise feature extraction, whereas the UCN uses Fully Convolutional feature extraction.
Fully Convolutional Feature Extraction
Unlike previous approaches where CNNs only takes a pair of fixed-sized patches, we propose a fully convolutional neural network to speed up the feature extraction. Advantage of using a fully convolutional neural network is that the network can reuse the computations for overlapping image patches (Long et al.2).
For example, if we extract image patches and use a patch-based CNN, even if there is an overlap among patches, we have to compute all activations again from scratch. Whereas if we use a fully convolutional neural network, we can reuse computation for all overlapping regions and thus can speed up computation.
However, this may leads to fixed fovea size and rotation which can be fixed by incorporating the spatial transformer network (next section).
Convolutional Spatial Transformer Layer
One of the most successful hand-designed features in Computer Vision is probably the SIFT feature (D. Lowe3). Though the feature itself is based on pooling and aggregation of simple edge strengths, the way the feature is extracted is also a part of the feature and affects the performance greatly.
The extraction process tries to normalize features so that the viewpoint does not affect the feature too much. This process is the patch normalization. Specifically, given a strong gradient direction in an image patch, the feature find the optimal rotation as well as the scale and then computes features using the right coordinate system using the optimal rotation and scale. We implement the same idea in a neural network by adopting the Spatial Transformer Network into the UCN (Jaderberg et al.4). The UCN, however, is fully convolutional and the features are dense. For this, we propose the Convolutional Spatial Transformer that applies independent transformation to each and every feature.
What UCN can and cannot do
We designed a network for basic feature extraction and basic feature extraction only. This is not a replacement for high-level filtering processes that use extra supervision/inputs such as Epipolar geometry. Rather, we provide a base network for future research and thus the base network should not be confused with a full blown framework for a specific application.
One of the questions that I got at NIPS is why we did not compare with stereo vision. This question might have arisen because we used stereo benchmarks to measure the performance of the raw features for geometric correspondence task. However, as mentioned before, the raw feature does not use extra inputs and is not equivalent to a full system that makes use of extra inputs and constraints specific for stereo vision: Epipolar Line search, which significantly reduces the search space from an entire image to a line, and post processing filtering stages. More detailed explanation is provided in the following section.
Stereo Vision
For the baseline comparisons, we did not use full systems that make use of extra inputs: camera intrinsic and extrinsic parameters. If you remember how painful the cameras calibrationl was when you took a Computer Vision class, you might see that camera extrinsic parameters and intrinsic parameters are strong extra inputs. Further, such extra inputs allow you to drastically reduce the search space for geometric correspondence.
Such constraint is known as the Epipolar constraint and is a powerful constraint that comes at a price. Since our framework is not a specialized for a stereo vision, we did not compare with systems that make use of this extra input/supervision.
Instead, we use all latest hand-designed features, FC layer features, and deep matching5 since all of those do not use extra camera parameters. In this paer, we focus only on the quality of the features that can be used for more complex systems.
In addition, in UCN, to show the quality of the feature, we simply used the most stupid way to find the correspondence: nearest neighbor on the entire images, which is very inefficient, but shows the quality of the raw features. To be able to compare it with the stereo vision systems, extra constraints (Epipolar geometry + CRF filtering) should be incorporated into both training and testing.
Conclusion
We propose an efficient feature learning method for various correspondence problems. We minimized the number of feed forward passes, incorporated metric space into a neural network, and proposed a convolutional spatial transformer to mimic behavior of one of the most successful hand designed features. However, this is not a replacement for the more complex system. Rather, this is a novel way to generate base features for a complex system that require correspondences as an input. I hope this blog post had resolved some of the questions regarding the UCN and facilitated future research.
Additional Resources
References
Li et al. Learned Invariant Feature Transform, 2016 ↩
Long et al. Fully Convolutional Neural Network for Semantic Segmentation, 2014 ↩
D. Lowe, Distinctive Image Features from Scale Invariant Keypoints, 2004 ↩
Jaderberg et al., Spatial Transformer Networks, 2015 ↩
Revaud et al., Deep Matching, 2013 ↩
(转载)Universal Correspondence Network的更多相关文章
- Direct Shot Correspondence Matching
一篇BMVC18的论文,关于semantic keypoints matching.dense matching的工作,感觉比纯patch matching有意思,记录一下. 1. 摘要 提出一种针对 ...
- SuperPoint: Self-Supervised Interest Point Detection and Description 论文笔记
Introduction 这篇文章设计了一种自监督网络框架,能够同时提取特征点的位置以及描述子.相比于patch-based方法,本文提出的算法能够在原始图像提取到像素级精度的特征点的位置及其描述子. ...
- RNN 入门教程 Part 4 – 实现 RNN-LSTM 和 GRU 模型
转载 - Recurrent Neural Network Tutorial, Part 4 – Implementing a GRU/LSTM RNN with Python and Theano ...
- LR: GLU-Net: Global-Local Universal Network for Dense Flow and Correspondences
Abstract 在图像中简历稠密匹配是很重要的任务, 包括 几何匹配,光流,语义匹配. 但是这些应用有很大的挑战: 大的平移, 像素精度, 外观变化: 当前是用特定的网络架构来解决一个单一问题. 我 ...
- 转载:Network In Network学习笔记
转载原文1:http://blog.csdn.net/hjimce/article/details/50458190 转载原文2:http://blog.csdn.net/mounty_fsc/art ...
- 【转载】 卷积神经网络(Convolutional Neural Network,CNN)
作者:wuliytTaotao 出处:https://www.cnblogs.com/wuliytTaotao/ 本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可,欢迎 ...
- Chrome DevTools — Network -- 转载
转载地址:https://segmentfault.com/a/1190000008407729 记录网络请求 默认情况下,只要DevTools在开启状态,DevTools会记录所有的网络请求,当然, ...
- 用户 NT AUTHORITY\NETWORK SERVICE 登录失败 解决方法(转载)
用户 NT AUTHORITY\NETWORK SERVICE 登录失败 解决方法 (MS SQL 2005) Windows server 2003,2008 Web.Config 配置连接sql ...
- Neural Network学习(二)Universal approximator :前向神经网络
1. 概述 前面我们已经介绍了最早的神经网络:感知机.感知机一个非常致命的缺点是由于它的线性结构,其只能做线性预测(甚至无法解决回归问题),这也是其在当时广为诟病的一个点. 虽然感知机无法解决非线性问 ...
随机推荐
- Mysql中innodb和myisam
innodb和myisam两种存储引擎的区别 1.事务和外键 1)InnoDB具有事务,支持4个事务隔离级别,回滚,崩溃修复能力和多版本并发的事务安全,包括ACID.如果应用中需要执行大量的INSER ...
- root用户被提示:Operation not permitted
一.问题 今天为了删除一个多余的的软件,在删除该软件安装目录时,提示rm: cannot remove ‘.user.ini’: Operation not permitted,root权限都不能删除 ...
- Windows 将FTP 映射到本地文件夹 --简化操作
转载自yutiantongbu Windows 将FTP 映射到本地文件夹 --简化操作 1.右键我的电脑,选择映射网络驱动器 2.选择"连接到可用与存储文档和图片的网站" 3.接 ...
- Cisco网络模拟器踩坑记录
1.在我们新建一个拓扑图的时候,选择设备之间的连线种类有时会导致线路不通的情况(两个端口上为红色点)这时候建议拆除这条线后选择闪电标记 的万能线帮助我们自动创建连线(这时就能根据它显示的线条种类得知应 ...
- Charles 4.2.1 HTTPS抓包
Charles 4.2.1 HTTPS抓包 Charles iPhone抓包 Mac必须与iPhone连接同一WiFi Proxy -> SSL Proxying Settings -> ...
- windows下面,PHP如何启动一些扩展功能
我今天在试这个时,发现php有些默认设置,是需要人为介入修改的. 比如,当我们在安装一个软件,而这个软件需要启用php一些扩展功能. 那么,按一般套路,将php.ini文件里的相关行的注释去掉即可. ...
- 基于Docker容器使用NVIDIA-GPU训练神经网络
一,nvidia K80驱动安装 1, 查看服务器上的Nvidia(英伟达)显卡信息,命令lspci |grep NVIDIA 05:00.0 3D controller: NVIDIA Corpo ...
- 编程小白入门分享一:git的最基本使用
git简介 引用了网上的一张图,这张图清晰表达git的架构.workspace是工作区,可以用编辑器直接编辑其中的文件:Index/Stage是暂存区,编辑后的文件可以添加到(add)暂存区:Repo ...
- oracle数据库登录和
首先引用百度云两个DLL文件 dbhelpher.DLL 和 Oracle.ManagedDataAccess.dll,加入配置文件sysdb文件 配置文件内容 < [DBMODE]MODE= ...
- Python中如何使用线程池和进程池?
进程池的使用 为什么要有进程池?进程池的概念. 在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务. 那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程 ...