正则_action
http://wiki.ubuntu.org.cn/index.php?title=Python%E6%AD%A3%E5%88%99%E8%A1%A8%E8%BE%BE%E5%BC%8F%E6%93%8D%E4%BD%9C%E6%8C%87%E5%8D%97&variant=zh-cn#match.28.29_vs_search.28.29
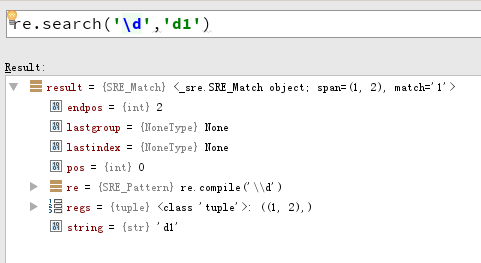
re.compile('\d+').search('按时打卡的23423') is None
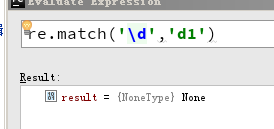
match() vs search()
match() 函数只检查 RE 是否在字符串开始处匹配,而 search() 则是扫描整个字符串。记住这一区别是重要的。记住,match() 只报告一次成功的匹配,它将从 0 处开始;如果匹配不是从 0 开始的,match() 将不会报告它。
http://www.heze.cn/qiye/
区别
http://www.heze.cn/qiye/.{0}$ 匹配成功
http://www.heze.cn/qiye/
http://www.heze.cn/qiye/.{0}$
结尾字符串
http://www.heze.cn/qiye/htt
http://www.heze.cn/qiye/((.{0}$)|(h.+$))
http://www.heze.cn/qiye/((.{0})|(h.+))$
http://www.heze.cn/qiye/[0-9a-zA-Z]+/show-\d+-\d+.html$
go
reg = regexp.MustCompile("http://www.heze.cn/{0-9a-zA-Z}/(.{0}$)|(list-\\d+-\\d+\\.html$)")
匹配数据 1-99
^[1-9][0-9]{0,1}[^0-9]{0,1}$
^[1-9]{1}[0-9]{0,1}$
http://cn.sonhoo.com/wukong/c0?offset=150&limit=50
^http://cn.sonhoo.com/wukong/c\d+\?offset=\d+\&limit=\d+$
c = colly.NewCollector(
colly.AllowedDomains("cn.sonhoo.com"),
colly.URLFilters(
//请求页面的正则表达式,满足其一即可
regexp.MustCompile("^http://cn.sonhoo.com/wukong/$"),
//regexp.MustCompile("^http://cn.sonhoo.com/wukong/[ac]{1}\\d+$"),
regexp.MustCompile("^http://cn.sonhoo.com/wukong/[c]{1}\\d+$"),
// http://cn.sonhoo.com/wukong/c0?offset=150&limit=50 文章列表页
regexp.MustCompile("^http://cn.sonhoo.com/wukong/c\\d+\\?offset=\\d+\\&limit=\\d+$"),
), +至少1次
{m,}至少m次 ^.+/wukong/u/\d+/index$ ^.{0,}/wukong/u/\d+/index$
// http://cn.sonhoo.com/wukong/u/200078/index
reg := regexp.MustCompile("^.{0,}/wukong/u/\\d+/index$")
// 检查href的是否为url
func isUrl(str string) bool {
reg := regexp.MustCompile("^[A-Za-z0-9_\\-\\.\\/\\&\\?\\=]+$")
data := reg.Find([]byte(str))
if (data == nil) {
return false
}
return true
} [A-Za-z0-9_\-\.\/\&\?\=]
http://www.cnhan.com/pinfo/
http://www.cnhan.com/pinfo/type-22
http://www.cnhan.com/pinfo/type-22-4 ^http://www.cnhan.com/pinfo/(.{0}$)|(type-[1-9][0-9]{0,1}(|-[1-9][0-9]{0,1})$) python
re.match('^http://www.cnhan.com/pinfo/\d+\.html$','http://www.cnhan.com/pinfo/318056a.html') None
SRE_MATCH
go
f := "^http://www.cnhan.com/pinfo/\\d+\\.html$"
reg := regexp.MustCompile(f)
data := reg.Find([]byte(link))
if data != nil { es ' d d '.replace(/\s/g,'') 去除全部空格
|
\s
|
匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
|
' d d '.replace(/\s/,'') 去除匹配到的第一个空格
' d d '.trim(' ','') 去除首尾的空格
^\s*$ 匹配任何不可见字符
^[\s\S]*\<script\>[\s\S]*\<\/script\>[\s\S]*$ 匹配script
^(\s*$)|([\s\S]*\<script\>[\s\S]*\<\/script\>[\s\S]*$)
\s 匹配任何不可见字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。
.点
匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。
*
匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于{0,}。
+
匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。
\<
\>
匹配词(word)的开始(\<)和结束(\>)。例如正则表达式\<the\>能够匹配字符串"for the wise"中的"the",但是不能匹配字符串"otherwise"中的"the"。注意:这个元字符不是所有的软件都支持的。
【new RegExp("test")
var re=new RegExp("test");re.test("test");
true
var re=new RegExp("^\^");re.test("^");
true
var re=new RegExp("^\^");re.test("^");
true
var re=new RegExp("^\\^\\$$");re.test("^$");
true
var re=new RegExp("^\^\$$");re.test("^$");
false
var re=new RegExp("^\\^\\$$");re.test("^$");
true
var re=new RegExp("^\\^/test/\.{1,}\\$$");re.test("^/test/my$");
true
var re=new RegExp("\");re.test("\");
VM911:1 Uncaught SyntaxError: missing ) after argument list
var re=new RegExp("\");re.test("\\");
VM915:1 Uncaught SyntaxError: missing ) after argument list
var re=new RegExp("\\");re.test("\\");
VM920:1 Uncaught SyntaxError: Invalid regular expression: /\/: \ at end of pattern
at new RegExp (<anonymous>)
at <anonymous>:1:8
(anonymous) @ VM920:1
var re=new RegExp("\\a");re.test("\\a");
true
var re=new RegExp("\\\");re.test("\\\");
VM939:1 Uncaught SyntaxError: missing ) after argument list
var re=new RegExp("\\\\");re.test("\\\\");
true
】
匹配iPv4
0.
1.
{n,m}
m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。
https://www.jb51.net/article/162641.htm
\w |
匹配一个单字字符(字母、数字或者下划线)。等价于 例如, |
(小数点)默认匹配除换行符之外的任何单个字符。
例如,/.n/ 将会匹配 "nay, an apple is on the tree" 中的 'an' 和 'on',但是不会匹配 'nay'。
如果 s ("dotAll") 标志位被设为 true,它也会匹配换行符。
* |
匹配前一个表达式 0 次或多次。等价于 例如, |
+ |
匹配前面一个表达式 1 次或者多次。等价于 例如, |
? |
匹配前面一个表达式 0 次或者 1 次。等价于 例如, 如果紧跟在任何量词 *、 +、? 或 {} 的后面,将会使量词变为非贪婪(匹配尽量少的字符),和缺省使用的贪婪模式(匹配尽可能多的字符)正好相反。例如,对 "123abc" 使用 还用于先行断言中,如本表的 |
\s |
Matches a white space character, including space, tab, form feed, line feed. Equivalent to For example, |
\S |
Matches a character other than white space. Equivalent to For example, |
https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Guide/Regular_Expressions
正则_action的更多相关文章
- Javascript正则对象方法与字符串正则方法总结
正则对象 var reg = new Regexp('abc','gi') var reg = /abc/ig 正则方法 test方法(测试某个字符串是否匹配) var str = 'abc123'; ...
- C#-正则,常用几种数据解析-端午快乐
在等待几个小时就是端午节了,这里预祝各位节日快乐. 这里分享的是几个在C#中常用的正则解析数据写法,其实就是Regex类,至于正则的匹配格式,请仔细阅读正则的api文档,此处不具体说明,谢谢. 开始吧 ...
- Javascript 中 with 的替代方案和String 中的正则方法
这几天在升级自己的MVVM 框架,遇到很多小问题,就在这里统一解决了. with 语法 在代码中,要执行这么一个函数 function computeExpression(exp, scope) { ...
- JavaScript与PHP中正则
一.JavaScript 有个在线调试正则的工具,点击查看工具.下面的所有示例代码,都可以在codepen上查看到. 1.创建正则表达式 var re = /ab+c/; //方式一 正则表达式字面量 ...
- Java正则速成秘籍(一)之招式篇
导读 正则表达式是什么?有什么用? 正则表达式(Regular Expression)是一种文本规则,可以用来校验.查找.替换与规则匹配的文本. 又爱又恨的正则 正则表达式是一个强大的文本匹配工具,但 ...
- Java正则速成秘籍(二)之心法篇
导读 正则表达式是什么?有什么用? 正则表达式(Regular Expression)是一种文本规则,可以用来校验.查找.替换与规则匹配的文本. 又爱又恨的正则 正则表达式是一个强大的文本匹配工具,但 ...
- Java正则速成秘籍(三)之见招拆招篇
导读 正则表达式是什么?有什么用? 正则表达式(Regular Expression)是一种文本规则,可以用来校验.查找.替换与规则匹配的文本. 又爱又恨的正则 正则表达式是一个强大的文本匹配工具,但 ...
- python浅谈正则的常用方法
python浅谈正则的常用方法覆盖范围70%以上 上一次很多朋友写文字屏蔽说到要用正则表达,其实不是我不想用(我正则用得不是很多,看过我之前爬虫的都知道,我直接用BeautifulSoup的网页标签去 ...
- [Python基础知识]正则
import re str4 = r"^http://qy.chinahr.com/cvm/preview\?cvid=\w{24,25}&from=sou>id=\w{ ...
随机推荐
- python ConfigParser 学习
[安装] ConfigParser 是解析配置文件的第三方库,需要安装 pip install ConfigParser [介绍] ConfigParser 是用来读取配置文件(可以是.conf, ...
- ZipKin原理学习--zipkin支持日志打印追踪信息
目前在zipkin brave已经提供功能在我们使用logback或log4j等时可以在日志信息中将traceId和spanId等信息打印到运行日志,这样可能对我们通过日志查看解决问题有比较大的 ...
- P2016 战略游戏 (树形DP)
题目描述 Bob喜欢玩电脑游戏,特别是战略游戏.但是他经常无法找到快速玩过游戏的办法.现在他有个问题. 他要建立一个古城堡,城堡中的路形成一棵树.他要在这棵树的结点上放置最少数目的士兵,使得这些士兵能 ...
- leetcode 349 map
只需要用map来标记1,今儿通过map的值来得到重叠的部分 class Solution { public: vector<int> intersection(vector<int& ...
- 理解 Nova 架构
Compute Service Nova 是 OpenStack 最核心的服务,负责维护和管理云环境的计算资源. OpenStack 作为 IaaS 的云操作系统,虚拟机生命周期管理也就是通过 Nov ...
- 标准C程序设计七---16
Linux应用 编程深入 语言编程 标准C程序设计七---经典C11程序设计 以下内容为阅读: <标准C程序设计>(第7版) 作者 ...
- android的系统学习
先从Android的应用开发开始,等到对应用掌握的比较熟悉了,开始慢慢阅读一些Android 应用框架层的源代码,然后再渐渐往下去了解Android的JNI.Libraries.Dalvik虚拟机.H ...
- HDU 5636 Shortest Path(Floyd)
题目链接 HDU5636 n个点,其中编号相邻的两个点之间都有一条长度为1的边,然后除此之外还有3条长度为1的边. m个询问,每次询问求两个点之前的最短路. 我们把这三条边的6个点两两算最短路, 然 ...
- codevs——1570 去看电影
1570 去看电影 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 黄金 Gold 题解 题目描述 Description 农夫约翰带着他的一些奶牛去看电影.而他的 ...
- hadoop 学习(二)
我们很荣幸能够见证Hadoop十年从无到有,再到称王.感动于技术的日新月异时,希望通过这篇内容深入解读Hadoop的昨天.今天和明天,憧憬下一个十年. 本文分为技术篇.产业篇.应用篇.展望篇四部分 技 ...