MySQL auto_increment实现
http://www.cnblogs.com/xpchild/p/3825309.html
运维的时候,经常遇到auto_increment的疑惑:
- 机器异常crash,重启后id回退的问题
- 性能考虑,每次获取肯定不会持久化,内存中取值,statement复制如何保证主备一致
- id的取值受binlog的保护吗
1. auto_increment相关的参数控制
1.1 innodb_autoinc_lock_mode
0: 每一个statement获取一个排他lock,直到statement结束,保证statement执行过程的id是连续的。
1: 单条确定insert影响的条数的时候,使用mutex。如果是insert select,load data这样的,使用排他lock。
2: 多条statement产生的id会穿插在一起,如果是statement复制,会产生不一致的情况。
1.2
auto_increment_increment
auto_increment_offset
控制自增的起始值和interval
2. auto_increment相关的数据结构
1. 锁模式中LOCK_AUTO_INC,即auto_increment的表锁。

/* Basic lock modes */
enum lock_mode {
LOCK_IS = 0, /* intention shared */
LOCK_IX, /* intention exclusive */
LOCK_S, /* shared */
LOCK_X, /* exclusive */
LOCK_AUTO_INC, /* locks the auto-inc counter of a table in an exclusive mode */
LOCK_NONE, /* this is used elsewhere to note consistent read */
LOCK_NUM = LOCK_NONE/* number of lock modes */
};
2. dict_table_t: innodb表定义
lock_t* autoinc_lock; 表锁
mutex_t autoinc_mutex; mutex锁
ib_uint64_t autoinc; 自增值
ulong n_waiting_or_granted_auto_inc_locks; 等待自增表锁的队列数
const trx_t* autoinc_trx; hold自增表锁的事务
3. trx_t: 事务结构
ulint n_autoinc_rows; statement插入的行数
ib_vector_t* autoinc_locks; 持有的自增lock
4. handler:table的innodb引擎句柄
ulonglong next_insert_id; 下次插入的id
ulonglong insert_id_for_cur_row; 当前插入的id
Discrete_interval auto_inc_interval_for_cur_row; 缓存,一次申请一个区间,缓存在server层。减少对innodb的调用
uint auto_inc_intervals_count; 向innodb申请id的interval。按照[1, 2, 4, 8, 16]递增。 最多1<<16 -1
注意:handler里的这些变量,只在一个语句下有效,语句结束就清理掉了。
3. 测试case
create table pp( id int primary key auto_increment, name varchar(100));
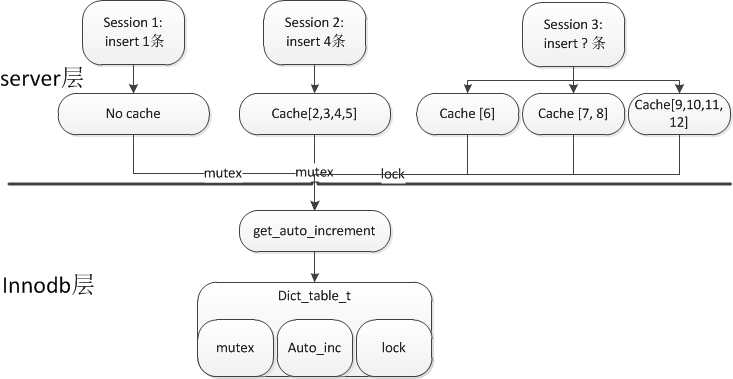
session1 : insert into pp(name) values('xx');
session2 : insert into pp(name) values('xx'),('xx'),('xx'),('xx')
session3 : insert into pp(name) select name from pp;
4. auto_increment的实现原理
4.2 锁的解释
根据锁持有的时间粒度,分为
1. 内存级别:类似mutex,很快释放
2. 语句级别:statement结束,释放
3. 事务级别:transaction提交或者回滚才释放
4. 会话级别:session级别,连接断开才释放
这里,session1和session2都是确定insert的条数,所以使用mutex分配固定的id。而session3未知,所以为了保证这一个statement的id是连续的,拿到一个lock,维持到statement结束才释放。
所以,为了提高并发量,锁持有的粒度越小越好。
4.3 缓存的解释
针对一个statement,预分配id值,减少对innodb的请求,也相应减少持有锁。
5. 测试细节
5.1 第一次执行
根据select max(id) from pp:获取autoinc的初始值
这样也就解释了文章开头的第一个疑惑,为什么机器crash了,id会回退。
简单函数栈:
ha_innobase::open
innobase_initialize_autoinc
5.2 session 1
1. 首先 持有mutex,获取autoinc
2. 因为insert的条数是1条,计算新的autoinc并更新到dict_table_t中,然后释放mutex结束
简单函数栈
handler::update_auto_increment
ha_innobase::get_auto_increment
ha_innobase::innobase_lock_autoinc
mutex_enter(&table->autoinc_mutex);
dict_table_autoinc_update_if_greater
5.3 session 2
1. 因为insert的条数是4条,所以前面的步骤都类似于session1,但计算完成新的autoinc为5,并更新dict_table_t.
2. 因为cache了[3,4,5],所以后面的三条insert,都在本地缓存中获取,不再请求innodb。
5.4 session 3
1. 因为不确定insert的条数,所以在语句的整个执行期间,持有lock。
2. 语句结束时,statement commit的时候释放
3. 第一次申请1个,第二次申请2个,第三次申请4个,共申请了3次。
简单函数栈:
handler::update_auto_increment
ha_innobase::get_auto_increment
row_lock_table_autoinc_for_mysql
trans_commit_stmt
row_unlock_table_autoinc_for_mysql
语句结束后, 清理语句级的环境
ha_release_auto_increment
insert_id_for_cur_row= 0; 当前语句的insert id设置为0
auto_inc_interval_for_cur_row.replace(0, 0, 0); 预分配的清空
auto_inc_intervals_count= 0; 预分配的迭代数也清0
table->in_use->auto_inc_intervals_forced.empty(); 清理链表
6. 警告:
1. 如果你的表是insert+delete的模式,你会发现重启了后,id被复用了,小心,被坑过的说。
2. 如果表上有自增键,insert select,load file,会对insert产生阻塞。
7. 思考:
1. 分布式的全局唯一递增(不保证连续) 怎么实现。 这是分布式系统都需要解决的问题!
MySQL auto_increment实现的更多相关文章
- [MySQL] AUTO_INCREMENT lock Handing in InnoDB
MySQL AUTO_INCREMENT lock Handing in InnoDB 在MySQL的表设计中很普遍的使用自增长字段作为表主键, 实际生产中我们也是这样约束业务开发同学的, 其中的优势 ...
- 验证:mysql AUTO_INCREMENT 默认值是1
用mongodb时,有些字段需要做自增,而且是用二十进制字母表示(使用a-t对应0-19),做了一个_auto_increment字段用来保存,但是应该从0开始还是从1开始呢? 和mysql保持一致便 ...
- MySQL Auto_Increment属性应用
我们经常要用到唯一编号,以标识记录.在MySQL中可通过数据列的AUTO_INCREMENT属性来自动生成.MySQL支持多种数据表,每种数据表的自增属性都有差异,这里将介绍各种数据表里的数据 ...
- MySQL auto_increment的坑
背景: Innodb引擎使用B_tree结构保存表数据,这样就需要一个唯一键表示每一行记录(比如二级索引记录引用). Innodb表定义中处理主键的逻辑是: 1.如果表定义了主键,就使用主键唯一定位一 ...
- MySQL AUTO_INCREMENT 简介
可使用复合索引在同一个数据表里创建多个相互独立的自增序列,具体做法是这样的:为数据表创建一个由多个数据列组成的PRIMARY KEY OR UNIQUE索引,并把AUTO_INCREMENT数据列包括 ...
- MySQL AUTO_INCREMENT 学习总结
之前有碰到过开发同事指出一张InnoDB表的自增列 AUTO_INCREMENT 值莫明的变大,由于这张表是通过mysqldump导出导入的. 问题排查: 1.首先,查看表表义的sql部分的 auto ...
- Mysql auto_increment总结
一.为什么InnoDB表要建议用自增列做主键 我们先了解下InnoDB引擎表的一些关键特征: InnoDB引擎表是基于B+树的索引组织表(IOT): 每个表都需要有一个聚集索引(clustered i ...
- MySQL auto_increment介绍 以及 查询和修改auto_increment的方法
一.auto_increment使用方法 .创建table时设置auto_increment属性和初始值100 create table nonove ( id bigint unsigned not ...
- MySql: AUTO_INCREMENT
首先要在Column使用AUTO_INCREMENT (每张表只有一个列可以AUTO_INCREMENT): 以下示例取自MySql官网(http://dev.mysql.com/doc/refman ...
随机推荐
- @Html.Raw()
asp.net mvc中把html字符串以html效果输出来, @string变更输出的是HTML代码, 如果想以HTML标签效果输出来可以用函数@Html.Raw(str) 输出来的就是网效果了, ...
- xcode import<xx/xx.h> 头文件报错
最近一直在写Android程序,有点久没用xcode,在写一个项目准备把 UI7Kit导进去,将iOS 7的界面适配到低版本的时候,出现了这么一个蛋疼的问题.稍微查了一下,新建项目的时候想先做一个li ...
- 为网页设计师准备的30个使用的HTML5框架
原文地址:http://www.goodfav.com/zh/html5-framework-8189.html 网页设计师在开始使用一些应用程序之前需要考虑几个事实,以确保在应用Web程序框架时,这 ...
- [WebService]之代码优先方法与契约优先方法
什么是 web 服务? web 服务是对应用程序功能的网络访问接口,它是使用标准 Internet 技术构建的. 我们目前看到的部署在 Internet 上的 web 服务都是 HTML 网站.其中, ...
- jszs 枚举算法
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- 【原】创建Hive表,分号分隔符“;”引起的异常
[障碍再现] 在创建支持Map数据结构的Hive表时,抛出如下异常 hive> create table tab_map(name string,info map<string,strin ...
- CF160D
题意:给你一个图,判断每条边是否在最小生成树MST上,不在输出none,如果在所有MST上就输出any,在某些MST上输出at least one: 分析:首先必须知道在最小生成树上的边的权值一定是等 ...
- HDU 4602 Magic Ball Game(离线处理,树状数组,dfs)
Magic Ball Game Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) ...
- C#中位、字节等知识
本文介绍C#中位.字节等知识. 1. 位(bit) 位(bit)有叫做比特,指二进制中的一位,是二进制的最小信息单位. bit也被称作小b,用b表示. 2. 字节(bytes) 8位表示一个字节. 由 ...
- JQ的each
写法一:遍历JSON数据 $.each(JSON.parse("{" + msg.d + "}"), function (key, name) { //处理得到 ...