Spark如何解决常见的Top N问题

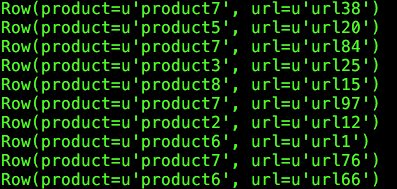

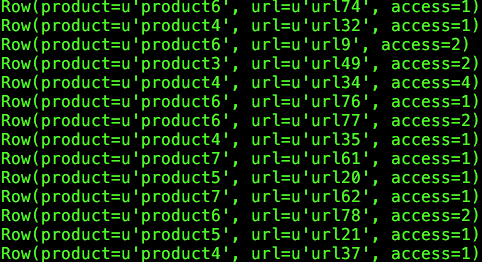



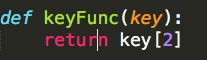




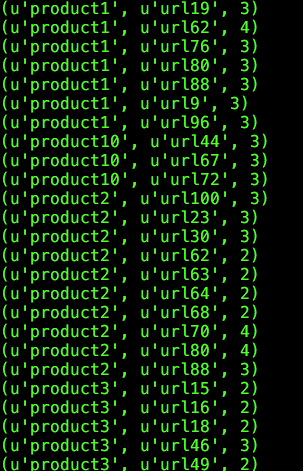
Spark如何解决常见的Top N问题的更多相关文章
- Spark程序运行常见错误解决方法以及优化
转载自:http://bigdata.51cto.com/art/201704/536499.htm Spark程序运行常见错误解决方法以及优化 task倾斜原因比较多,网络io,cpu,mem都有可 ...
- 如何解决海量数据的Top K问题
1. 问题描述 在大规模数据处理中,常遇到的一类问题是,在海量数据中找出出现频率最高的前K个数,或者从海量数据中找出最大的前K个数,这类问题通常称为“top K”问题,如:在搜索引擎中,统计搜索最热门 ...
- 【Spark篇】---Spark故障解决(troubleshooting)
一.前述 本文总结了常用的Spark的troubleshooting. 二.具体 1.shuffle file cannot find:磁盘小文件找不到. 1) connection timeout ...
- Spark 学习笔记 —— 常见API
一.RDD 的创建 1)通过 RDD 的集合数据结构,创建 RDD sc.parallelize(List(1,2,3),2) 其中第二个参数代表的是整个数据,分为 2 个 partition,默认情 ...
- 【spark】示例:求Top值
我们有这样的两个文件 第一个数字为行号,后边为三列数据.我们来求第二列数据的Top(N) (1)我们先读取数据,创建Rdd (2)过滤数据,取第二列数据. 我们用filter()来过滤数据 line. ...
- Git 项目上传至github入门实战并解决常见错误
1.Git GUI 首先,在push到github的项目必须先建立版本(即creat repository的名字一样),一般是先pull下来,再push(为了防止有其他人提交了代码,而你却不知道,造 ...
- iOS runtime实用篇解决常见Crash
程序崩溃经历 其实在很早之前就想写这篇文章了,一直拖到现在. 程序崩溃经历1 平时开发测试的时候好好的,结果上线几天发现有崩溃的问题,其实责任大部分在我身上. 我的责任: 过分信赖文档,没进行容错处理 ...
- 【spark】dataframe常见操作
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能.当然主要对类SQL的支持. 在实际工作中会遇到这样的情况,主要是会进行两个数据集的筛选.合并,重新入库. 首先加载数据集 ...
- CM5.x配置spark错误解决
通过cloudera manager 5.x添加spark服务,在创建服务过程中,发现spark服务创建失败,可以通过控制台错误输出看到如下日志信息: + perl -pi -e 's#{{CMF_C ...
随机推荐
- JDK1.8聚合操作
在java8 JDK包含许多聚合操作(如平均值,总和,最小,最大,和计数),返回一个计算流stream的聚合结果.这些聚合操作被称为聚合操作.JDK除返回单个值的聚合操作外,还有很多聚合操作返回一个c ...
- Android开发手记(17) 数据存储二 文件存储数据
Android为数据存储提供了五种方式: 1.SharedPreferences 2.文件存储 3.SQLite数据库 4.ContentProvider 5.网络存储 本文主要介绍如何使用文件来存储 ...
- linunx 定位最耗资源的进程
[oracle@topbox bdump]$ ps -ef|grep “(LOCAL=NO)”|sort -rn -k 8,8|head -10oracle 9402 1 67 09:1 ...
- 应用程序中小红点设置方法 (ios)
我们的手机上常常会看到软件的右上角出现小红点,上面显示着你未读的消息数.下面是设置小红点的方法. 1.tabBar上按钮的小红点 因为小红点代表你未读的消息数,所以这个小红点上的数据不是凭空 ...
- Nodejs简单验证码ccap安装
首先要求: node npm 安装时如果提示npm-gyp失败,可进行如下操作: 确认python版本2.7+ 安装npm install ccap 如果失败,尝试npm install ccap@0 ...
- JavaScript 高阶函数 + generator生成器
map/reduce map()方法定义在JavaScript的Array中,我们调用Array的map()方法,传入我们自己的函数,就得到了一个新的Array作为结果: function pow(x ...
- CSS鼠标点击式变化图片透明度
今天分享前端代码主题:jequery控制css图片透明度 很多时候在网站图片处理上需要实现一些辅助效果,比如鼠标在图片上滑动时或点击时改变图片颜色(变灰或者其他),其实一个简单的办法就是改变图片css ...
- LPC1114
时钟配置: 3个时钟源:系统振荡源(system),IRC振荡源,(IRC,内部RC振荡器)看门狗振荡源(WatchDog) MAINCLKSEL:主时钟源选择寄存器(复位值:0) 只用了前两位: 0 ...
- iOS: 学习笔记, Swift运算符定义
Swift操作符可以自行定义, 只需要加上简单的标志符即可. @infix 中置运算. 如+,-,*,/运算 @prefix 前置运算. 如- @postfix 后置运算. a++, a-- @ass ...
- 学习Swift -- 构造器(下)
构造器(下) 可失败的构造器 如果一个类,结构体或枚举类型的对象,在构造自身的过程中有可能失败,则为其定义一个可失败构造器,是非常有必要的.这里所指的“失败”是指,如给构造器传入无效的参数值,或缺少某 ...