Python+Requests接口测试教程(2):
开讲前,告诉大家requests有他自己的官方文档:http://cn.python-requests.org/zh_CN/latest/
2.1 发get请求
前言
requests模块,也就是老污龟,为啥叫它老污龟呢,因为这个官网上的logo就是这只污龟,接下来就是学习它了。
环境准备(小编环境):
python:2.7.12
pycharm:5.0.4
requests:2.13.0
(这学本篇之前,先要有一定的python基础,因为后面都是直接用python写代码了,小编主要以讲接口为主,python基础东西就自己去补了)
一、环境安装
1.用pip安装requests模块
>>pip install requests
二、get请求
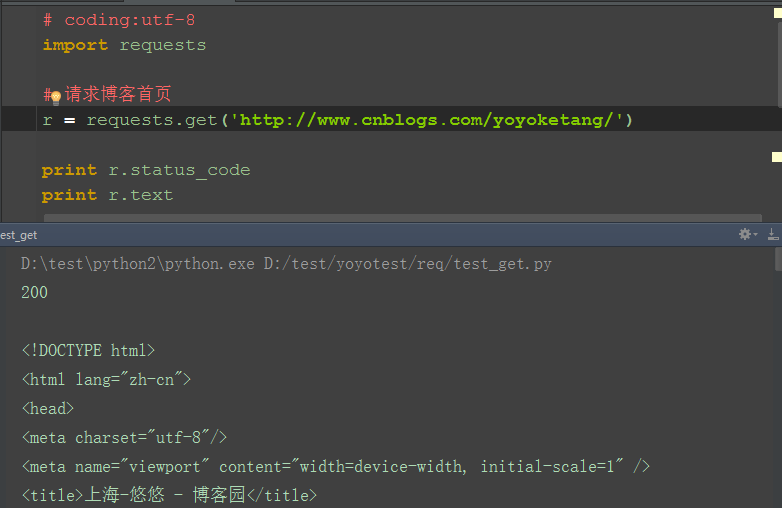
1.导入requests后,用get方法就能直接访问url地址,如:http://www.cnblogs.com/yoyoketang/,看起来是不是很酷
2.这里的r也就是response,请求后的返回值,可以调用response里的status_code方法查看状态码
3.状态码200只能说明这个接口访问的服务器地址是对的,并不能说明功能OK,一般要查看响应的内容,r.text是返回文本信息
三、params
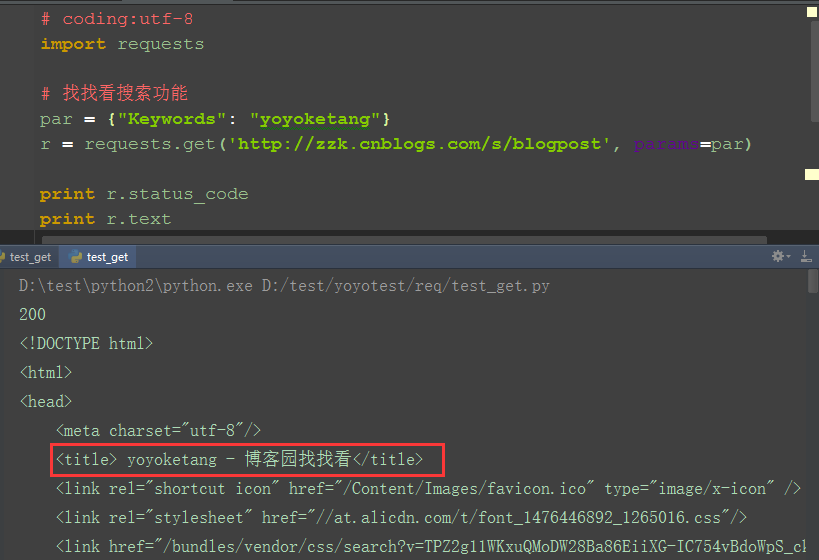
1.再发一个带参数的get请求,如在博客园搜索:yoyoketang,url地址为:http://zzk.cnblogs.com/s/blogpost?Keywords=yoyoketang
2.请求参数:Keywords=yoyoketang,可以以字典的形式传参:{"Keywords": "yoyoketang"}
3.多个参数格式:{"key1": "value1", "key2": "value2", "key3": "value3"}
四、content
1.百度首页如果用r.text会发现获取到的内容有乱码,因为百度首页响应内容是gzip压缩的(非text文本)
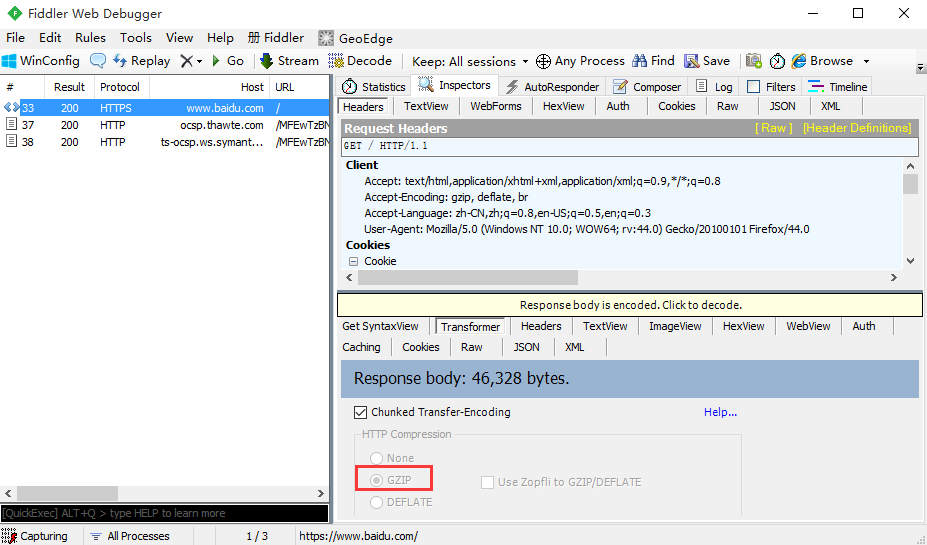
2.如果是在fiddler工具乱码,是可以点击后解码的,在代码里面可以用r.content这个方法,content会自动解码 gzip 和deflate压缩
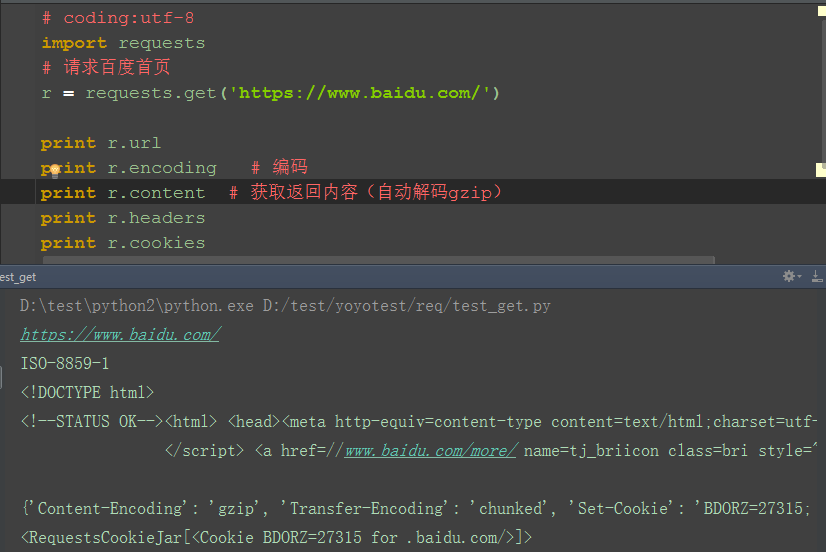
五、response
1.response的返回内容还有其它更多信息
-- r.status_code #响应状态码
-- r.content #字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩
-- r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
-- r.json() #Requests中内置的JSON解码器
-- r.url # 获取url
-- r.encoding # 编码格式
-- r.cookies # 获取cookie
-- r.raw #返回原始响应体
-- r.text #字符串方式的响应体,会自动根据响应头部的字符编码进行解码
-- r.raise_for_status() #失败请求(非200响应)抛出异常
2.2 发post请求(json)
前言
发送post的请求参考例子很简单,实际遇到的情况却是很复杂的,首先第一个post请求肯定是登录了,但登录是最难处理的。登录问题解决了,后面都简单了。
一、查看官方文档
1.学习一个新的模块,其实不用去百度什么的,直接用help函数就能查看相关注释和案例内容。
>>import requests
>>help(requests)
2.查看python发送get和post请求的案例
>>> import requests
>>> r = requests.get('https://www.python.org')
>>> r.status_code
200
>>> 'Python is a programming language' in r.content
True
... or POST:
>>> payload = dict(key1='value1', key2='value2')
>>> r = requests.post('http://httpbin.org/post', data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
二、发送post请求
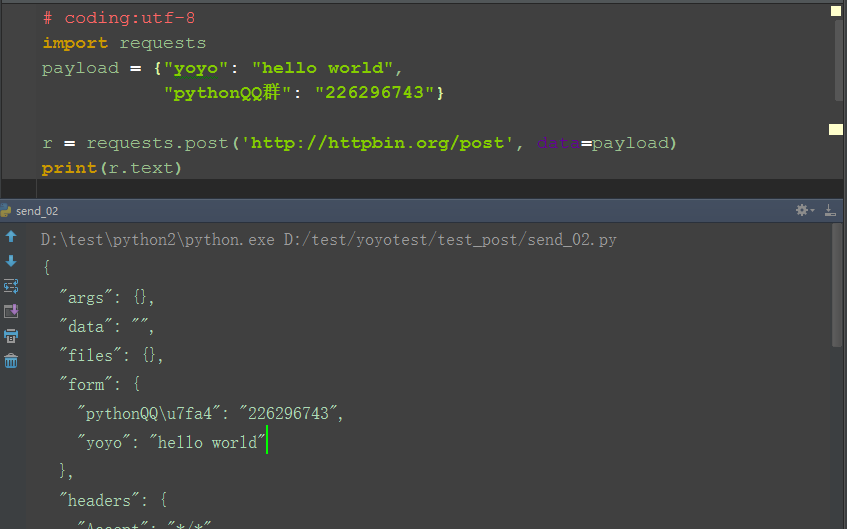
1.用上面给的案例,做个简单修改,发个post请求
2.payload参数是字典类型,传到如下图的form里
三、json
1.post的body是json类型,也可以用json参数传入。
2.先导入json模块,用dumps方法转化成json格式。
3.返回结果,传到data里。

四、headers
1.以博客园为例,模拟登陆,实际的情况要比上面讲的几个基本内容要复杂很多,一般登陆涉及安全性方面,登陆会比较复杂
2.这里需添加请求头headers,可以用fiddler抓包
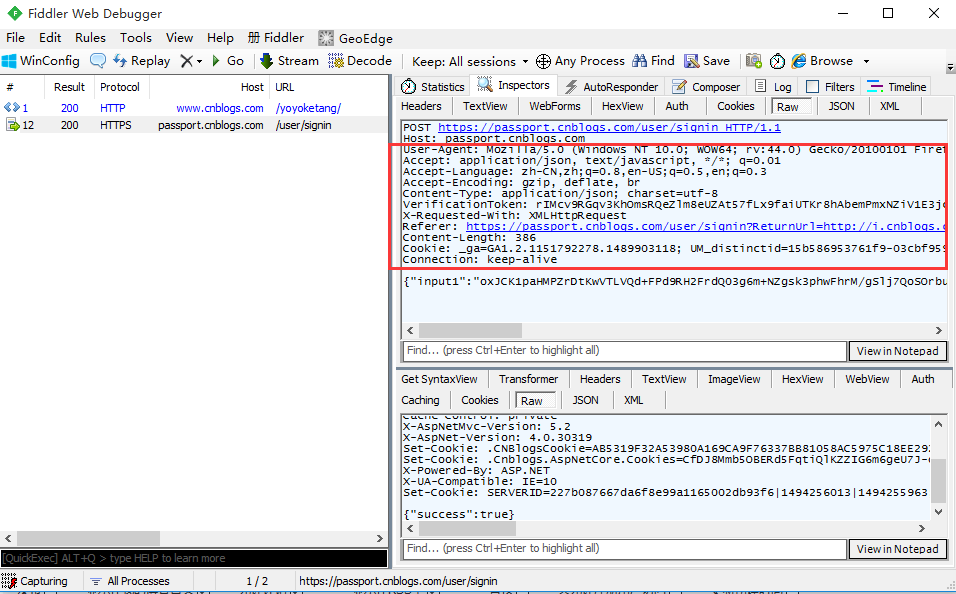
3.将请求头写成字典格式
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
"X-Requested-With": "XMLHttpRequest",
"Cookie": "xxx.............", # 此处cookie省略了
"Connection": "keep-alive"
}
五、登陆博客园
1.由于这里是https请求,直接发送请求会报错误:SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590)
2.可以加个参数:verify=False,表示忽略对 SSL 证书的验证
3.这里请求参数payload是json格式的,用json参数传
4.红色注释那两行可以不用写
5.最后结果是json格式,可以直接用r.json返回json数据:{u'success': True}
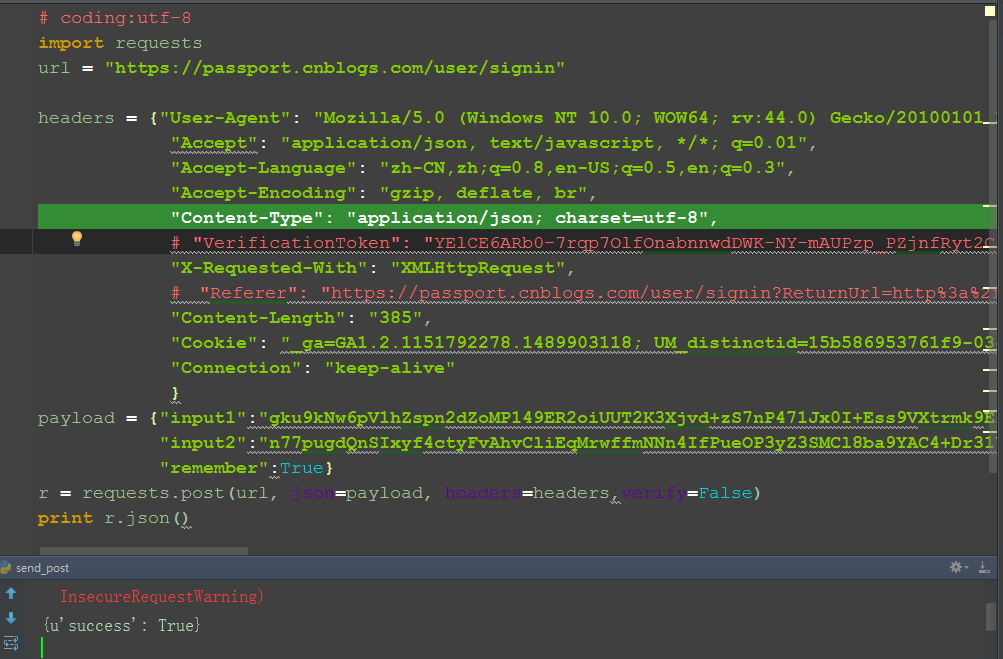
六、参考代码
# coding:utf-8
import requests
url = "https://passport.cnblogs.com/user/signin"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
# "VerificationToken": "",
"X-Requested-With": "XMLHttpRequest",
# "Referer": "",
"Content-Length": "",
"Cookie": "xxx...", # 此处省略
"Connection": "keep-alive"
}
payload = {"input1":"xxx",
"input2":"xxx",
"remember":True}
r = requests.post(url, json=payload, headers=headers,verify=False)
print r.json()
2.3 发post请求(data)
前言:
前面登录博客园的是传json参数,有些登录不是传json的,如jenkins的登录,本篇以jenkins登录为案例,传data参数。
一、登录jenkins抓包
1.登录jenkins,输入账号和密码
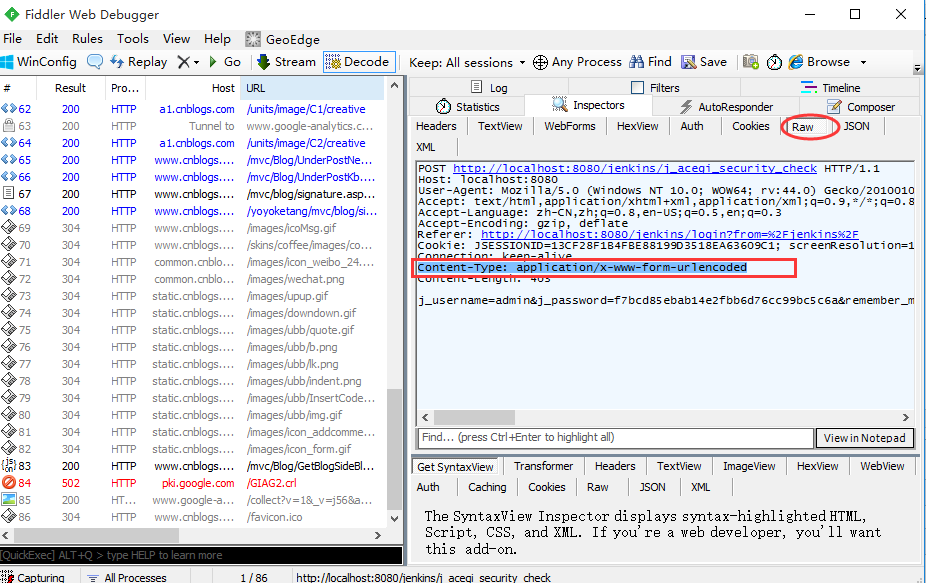
2.fiddler抓包
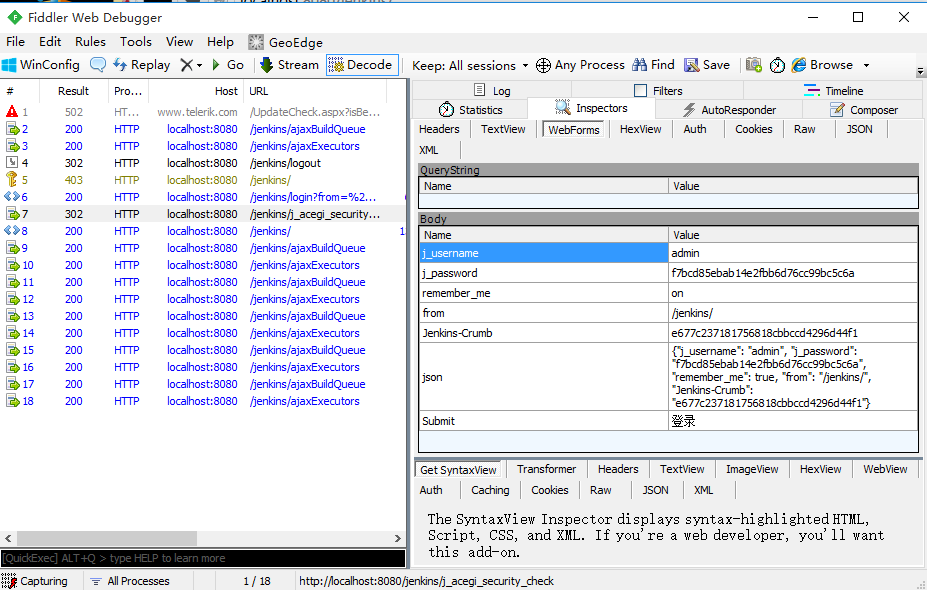
3.这个body参数并不是json格式,是key=value格式,也就是前面介绍post请求四种数据类型里面的第二种

二、请求头部
1.上面抓包已经知道body的数据类型了,那么头部里面Content-Type类型也需要填写对应的参数类型
三、实现登录
1、登录代码如下:
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "http://localhost:8080/jenkins/j_acegi_security_check"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
d = {"from": "",
"j_password": "f7bcd85ebab14e2fbb6d76cc99bc5c6a",
"j_username": "admin",
"Jenkins-Crumb": "e677c237181756818cbbccd4296d44f1",
"json": {"j_username": "admin",
"j_password": "f7bcd85ebab14e2fbb6d76cc99bc5c6a",
"remember_me": True,
"from": "",
"Jenkins-Crumb": "e677c237181756818cbbccd4296d44f1"},
"remember_me": "on",
"Submit": u"登录"
}
s = requests.session()
r = s.post(url, headers=headers, data=d)
print r.content
2.打印结果
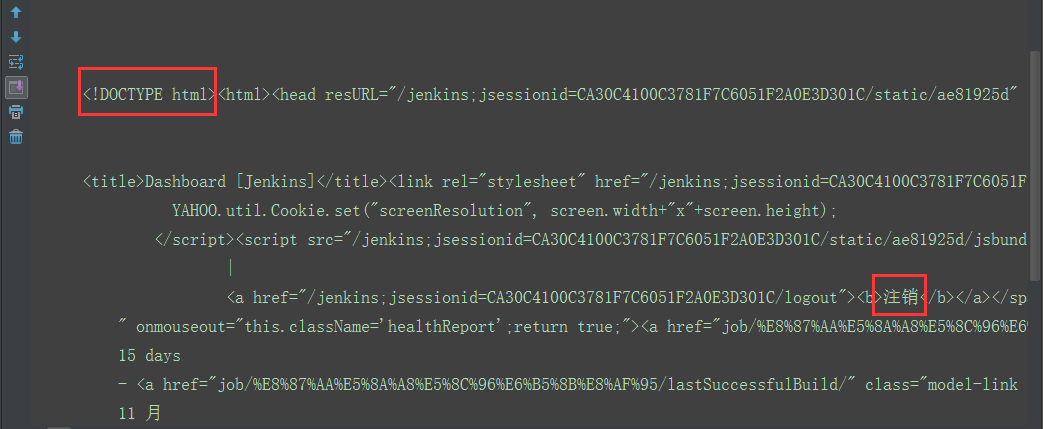
四、判断登录是否成功
1.首先这个登录接口有重定向,看左边会话框302,那登录成功的结果看最后一个200就行
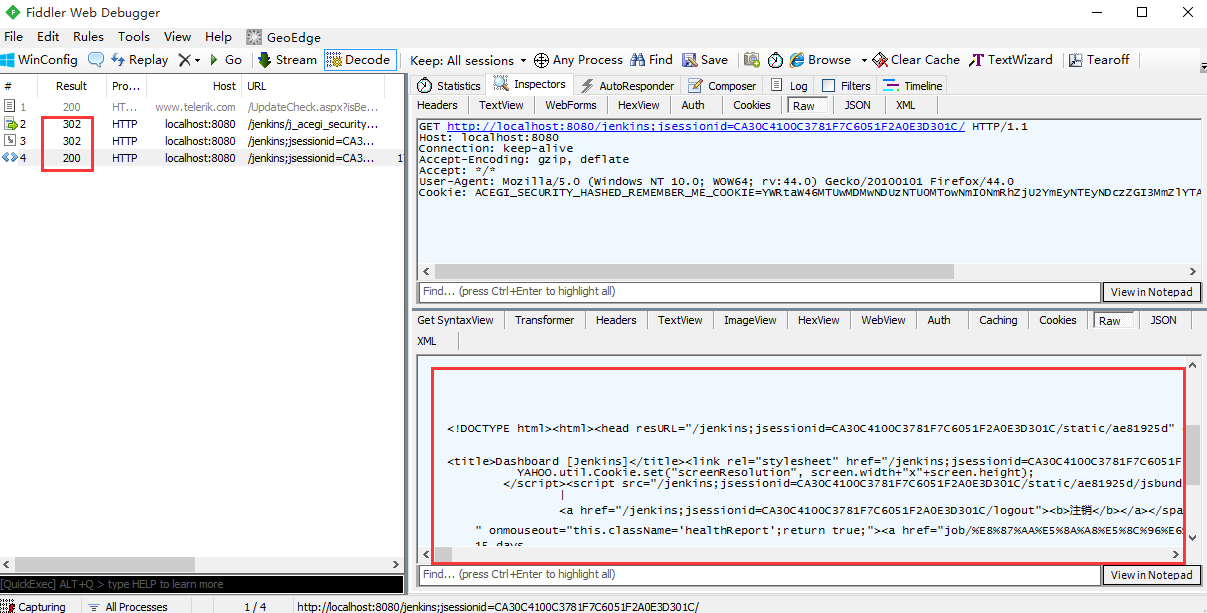
2.返回的结果并不是跟博客园一样的json格式,返回的是一个html页面
五、判断登录成功
1.判断登录成功,可以抓取页面上的关键元素,比如:账号名称admin,注销按钮
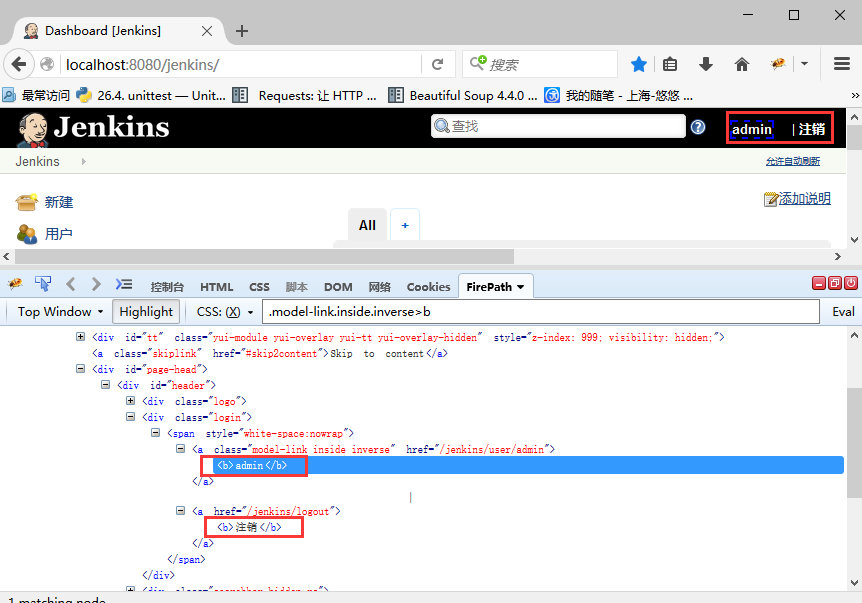
2.通过正则表达式提出这2个关键字
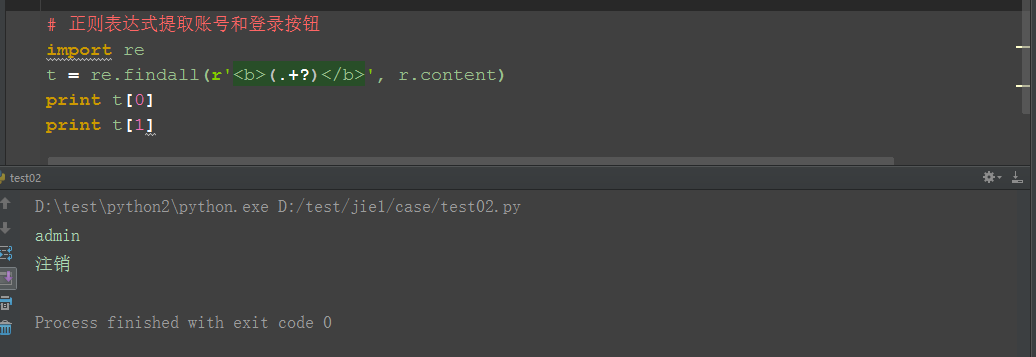
六、参考代码
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "http://localhost:8080/jenkins/j_acegi_security_check"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
d = {"from": "",
"j_password": "f7bcd85ebab14e2fbb6d76cc99bc5c6a",
"j_username": "admin",
"Jenkins-Crumb": "e677c237181756818cbbccd4296d44f1",
"json": {"j_username": "admin",
"j_password": "f7bcd85ebab14e2fbb6d76cc99bc5c6a",
"remember_me": True,
"from": "",
"Jenkins-Crumb": "e677c237181756818cbbccd4296d44f1"},
"remember_me": "on",
"Submit": u"登录"
}
s = requests.session()
r = s.post(url, headers=headers, data=d)
# 正则表达式提取账号和登录按钮
import re
t = re.findall(r'<b>(.+?)</b>', r.content) # 用python3的这里r.content需要解码
print t[0]
print t[1]
2.4 data和json傻傻分不清
前言
在发post请求的时候,有时候body部分要传data参数,有时候body部分又要传json参数,那么问题来了:到底什么时候该传json,什么时候该传data?
一、识别json参数
1.在前面1.8章节讲过,post请求的body通常有四种类型,最常见的就是json格式的了,这个还是很好识别的

2.用抓包工具查看,首先点开Raw去查看body部分,如下图这种,参数最外面是大括号{ }包起来的,这种已经确诊为json格式了。
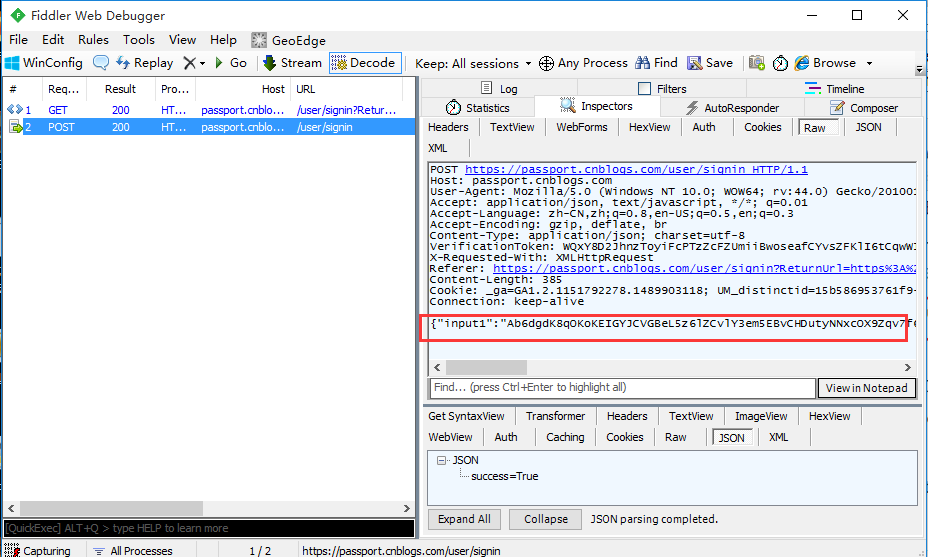
3.再一次确认,可以点开Json这一项查看,点开之后可以看到这里的几组参数是json解析后的(记住它的样子)
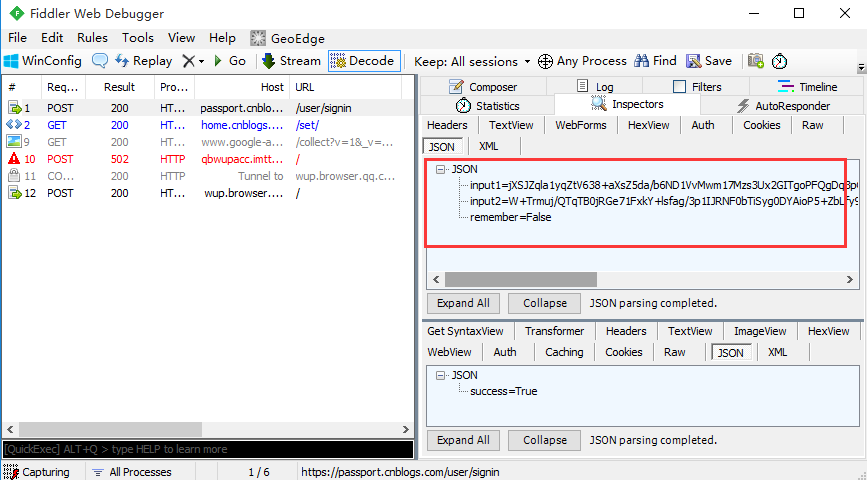
4.这时候,就可以用前面2.2讲的传json参数
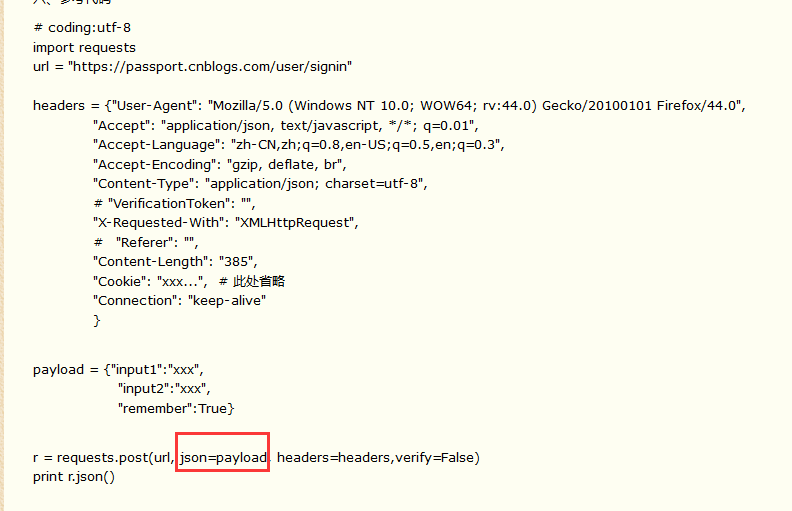
二、识别data参数
1.data参数也就是这种格式:key1=value1&key2=value2...这种格式很明显没有大括号
点开Raw查看,跟上面的json区别还是很大的
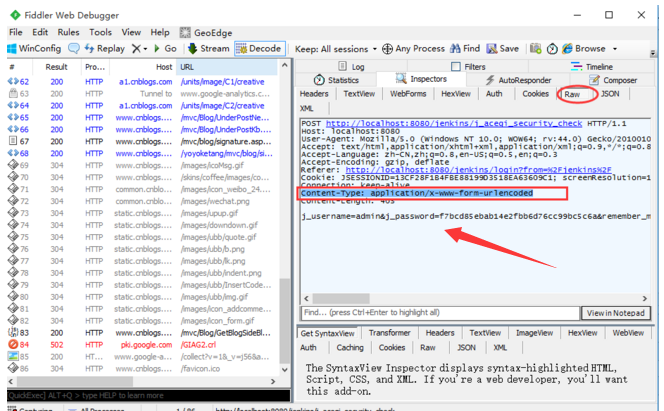
2.因为这个是非json的,所以点开Json这个菜单是不会有解析的数据的,这种数据在WebForms里面查看
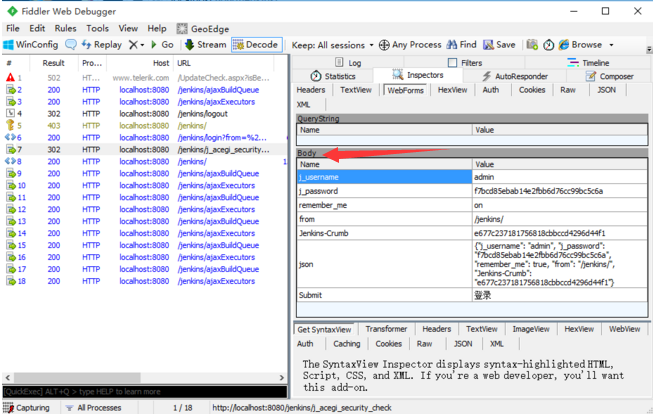
3.可以看到这种参数显示在Body部分,左边的Name这项就是key值,右边的Value就是对应的value值,像这种参数转化从python的字典格式就行了

4.这一种发post时候就传data参数就可以了,格式如下:
s = requests.session()
r = s.post(url, headers=headers, data=d) # 这里的d就是上一步的字典格式的参数
现在能分得清data参数和json参数的不?
2.5 发https请求(ssl)
前言
本来最新的requests库V2.13.0是支持https请求的,但是一般写脚本时候,我们会用抓包工具fiddler,这时候会 报:requests.exceptions.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590)
小编环境:
python:2.7.12
requests:2.13.0
fiddler:v4.6.2.0
一、SSL问题
1.不启用fiddler,直接发https请求,不会有SSL问题(也就是说不想看到SSL问题,关掉fiddler就行)

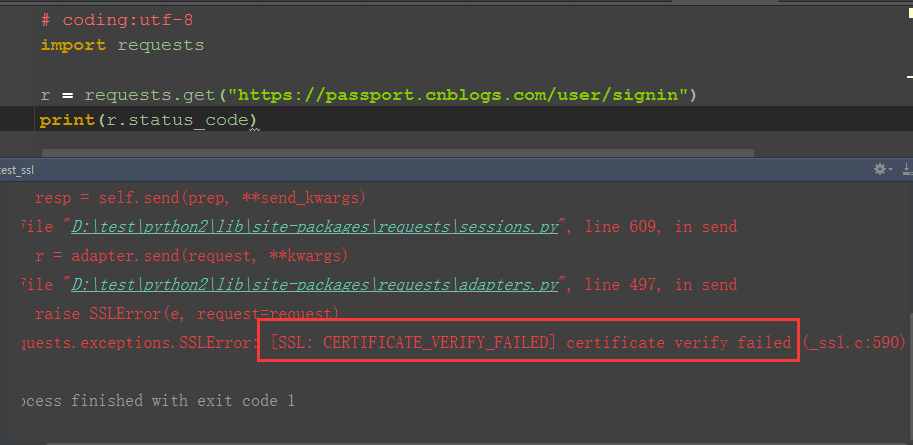
2.启动fiddler抓包,会出现这个错误:requests.exceptions.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590)
二、verify参数设置
1.Requests的请求默认verify=True
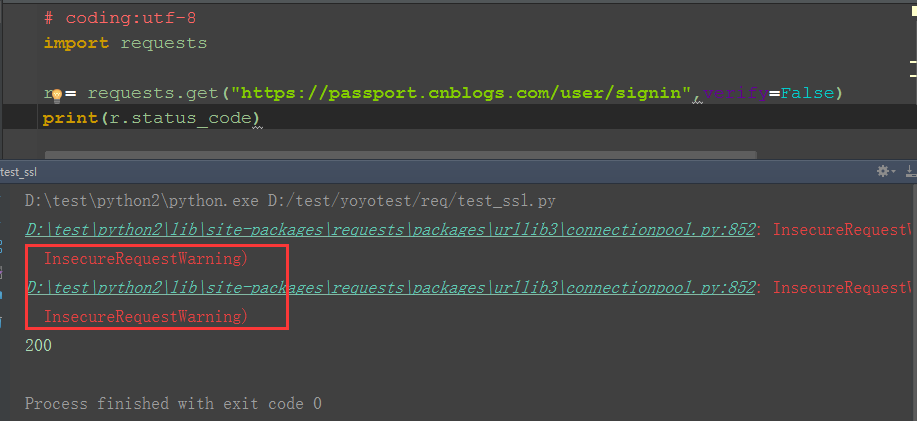
2.如果你将 verify设置为 False,Requests 也能忽略对 SSL 证书的验证
3.但是依然会出现两行Warning,可以不用管
三、忽略Warning
1.有些小伙伴有强迫症看到红色的心里就发慌,这里加两行代码可以忽略掉警告,眼不见为净!
2.参考代码:
# coding:utf-8
import requests
# 禁用安全请求警告
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
url = "https://passport.cnblogs.com/user/signin"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
}
r = requests.get(url, headers=headers, verify=False)
print(r.status_code)
2.6 session关联接口
前言
上一篇模拟登录博客园,但这只是第一步,一般登录后,还会有其它的操作,如发帖,评论等,这时候如何保持会话呢?
一、session简介
1.查看帮助文档,贴了一部分,后面省略了
>>import requests
>>help(requests.session())
class Session(SessionRedirectMixin)
| A Requests session.
|
| Provides cookie persistence, connection-pooling, and configuration.
|
| Basic Usage::
|
| >>> import requests
| >>> s = requests.Session()
| >>> s.get('http://httpbin.org/get')
| <Response [200]>
|
| Or as a context manager::
|
| >>> with requests.Session() as s:
| >>> s.get('http://httpbin.org/get')
| <Response [200]>
二、使用session登录
1.使用session登录只需在上一篇基础上稍做修改
# coding:utf-8
import requests
url = "https://passport.cnblogs.com/user/signin"
headers = {
#头部信息已省略
}
payload = {"input1":"xxx",
"input2":"xxx",
"remember":True}
# r = requests.post(url, json=payload, headers=headers,verify=False)
# 修改后如下
s = requests.session()
r = s.post(url, json=payload, headers=headers,verify=False)
print r.json()
三、保存编辑
1.先打开我的随笔,手动输入内容后,打开fiddler抓包
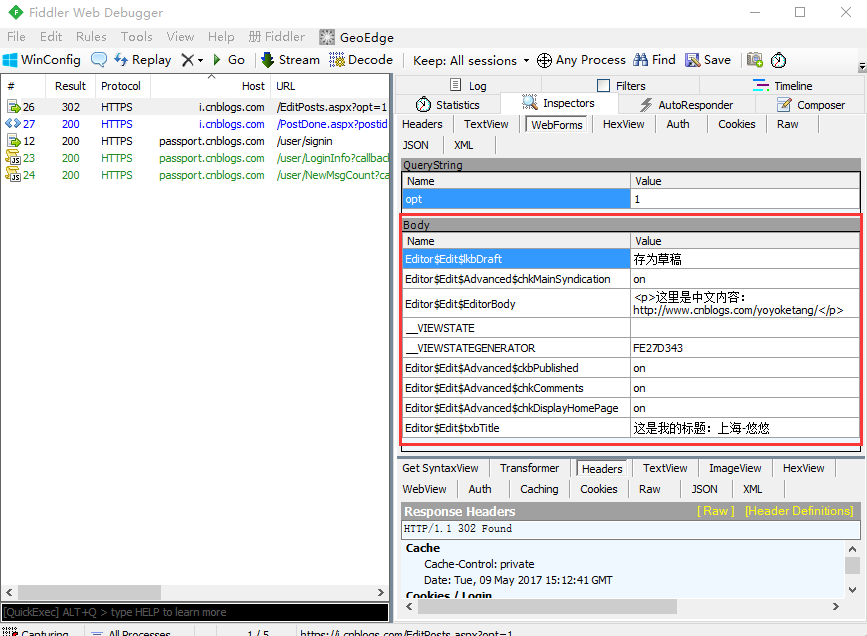
2.把body的参数内容写成字典格式,有几个空的参数不是必填的,可以去掉
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是我的标题:上海-悠悠",
"Editor$Edit$EditorBody":"<p>这里是中文内容:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存为草稿",
}
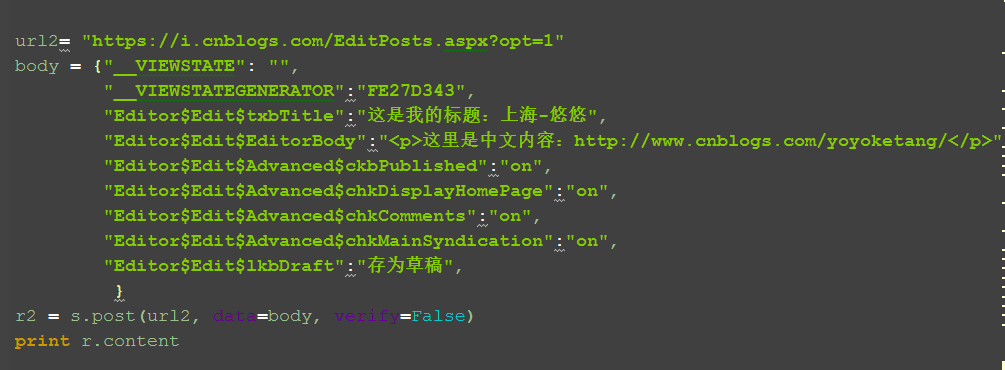
3.用上面的session继续发送post请求
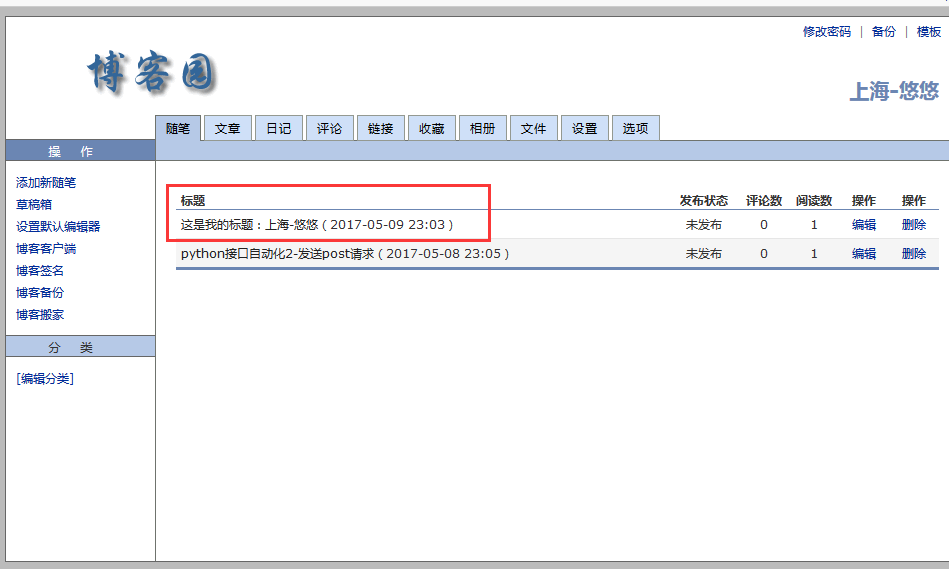
4.执行后,查看我的草稿箱就多了一条新增的了
四、参考代码
# coding:utf-8
import requests
url = "https://passport.cnblogs.com/user/signin"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
# "VerificationToken": "xxx...", # 已省略
"X-Requested-With": "XMLHttpRequest",
# "Referer":
"https://passport.cnblogs.com/user/signin?ReturnUrl=http%3a%2f%2fmsg.cnblogs.com%2fsend%2f%e4%b8%8a%e6%b5%b7-%e6%82%a0%e6%82%a0",
"Content-Length": "",
"Cookie": "xxx.....", # 已省略
"Connection": "keep-alive"
}
# 登录的参数
payload = {"input1":"xxx",
"input2":"xxx",
"remember":True}
s = requests.session()
r = s.post(url, json=payload, headers=headers,verify=False)
print r.json()
# 保存草稿箱
url2= "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是我的标题:上海-悠悠",
"Editor$Edit$EditorBody":"<p>这里是中文内容:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
print r.content
这里我是用保存草稿箱写的案例,小伙伴们可以试下自动发帖
(备注:别使用太频繁了哦,小心封号嘿嘿!!!)
2.7 cookie绕过验证码登录
前言
有些登录的接口会有验证码:短信验证码,图形验证码等,这种登录的话验证码参数可以从后台获取的(或者查数据库最直接)。
获取不到也没关系,可以通过添加cookie的方式绕过验证码。
(注意:并不是所有的登录都是用cookie来保持登录的,有些是2.11章节讲的token)
一、抓登录cookie
1.如博客园登录后会生成一个已登录状态的cookie,那么只需要直接把这个值添加到cookies里面就可以了。
2.可以先手动登录一次,然后抓取这个cookie,这里就需要用抓包工具fiddler了
3.先打开博客园登录界面,手动输入账号和密码(勾选下次自动登录)
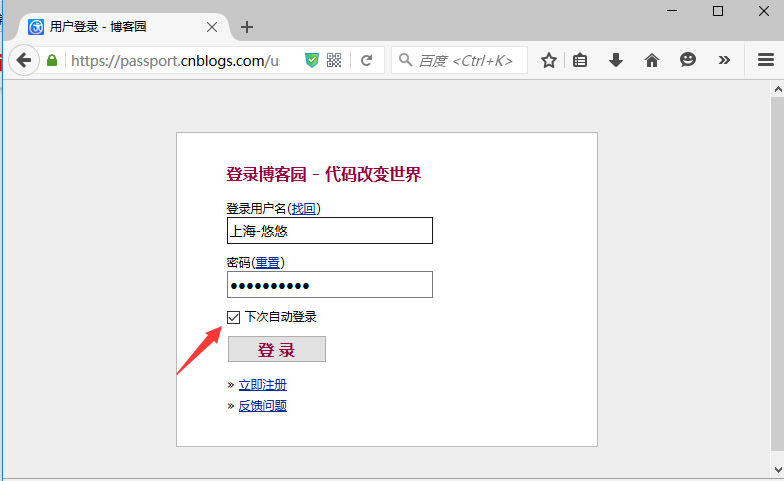
4.打开fiddler抓包工具,刷新下登录首页,就是登录前的cookie了
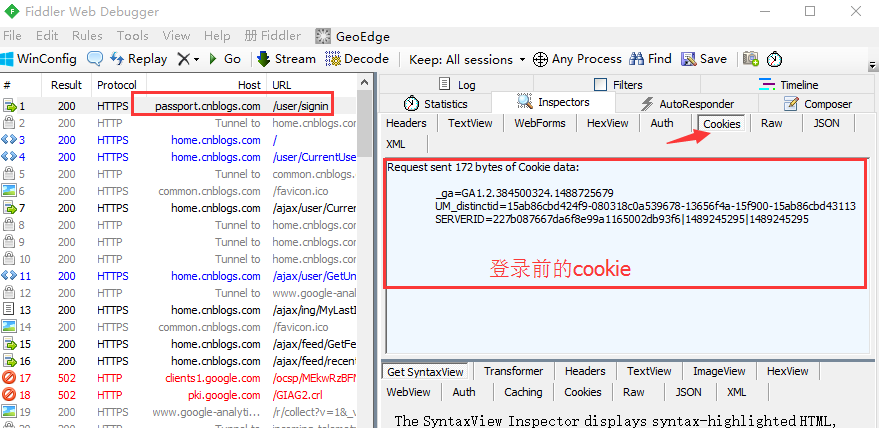
5.登录成功后,再查看cookie变化,发现多了两组参数,多的这两组参数就是我们想要的,copy出来,一会有用
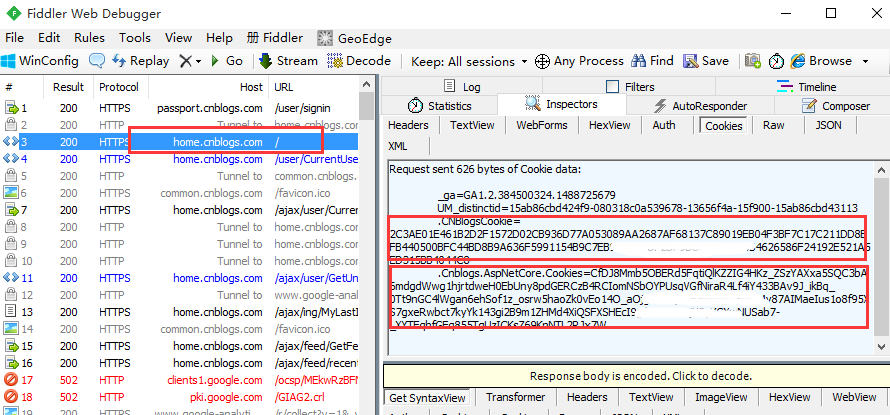
二、cookie组成结构
1.用抓包工具fidller只能看到cookie的name和value两个参数,实际上cookie还有其它参数
2.以下是一个完整的cookie组成结构
cookie ={u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
name:cookie的名称
value:cookie对应的值,动态生成的
domain:服务器域名
expiry:Cookie有效终止日期
path:Path属性定义了Web服务器上哪些路径下的页面可获取服务器设置的Cookie
httpOnly:防脚本攻击
secure:在Cookie中标记该变量,表明只有当浏览器和Web Server之间的通信协议为加密认证协议时,
浏览器才向服务器提交相应的Cookie。当前这种协议只有一种,即为HTTPS。
三、添加cookie
1.往session里面添加cookie可以用以下方式
2.set里面参数按括号里面的参数格式
coo = requests.cookies.RequestsCookieJar()
coo.set('cookie-name', 'cookie-value', path='/', domain='.xxx.com')
s.cookies.update(c)
3.于是添加登录的cookie,把第一步fiddler抓到的内容填进去就可以了
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', 'xxx')
c.set('.Cnblogs.AspNetCore.Cookies','xxx')
s.cookies.update(c)
print(s.cookies)
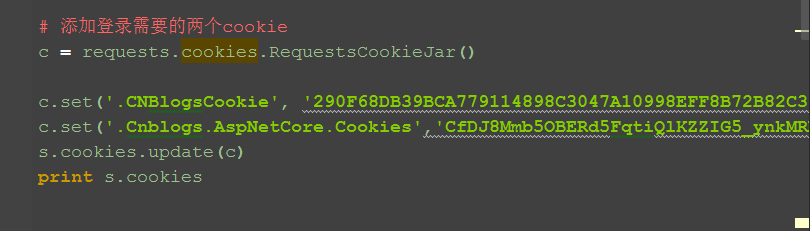
四、参考代码
1.由于登录时候是多加2个cookie,我们可以先用get方法打开登录首页,获取部分cookie
2.再把登录需要的cookie添加到session里
3.添加成功后,随便编辑正文和标题保存到草稿箱
# coding:utf-8
import requests
# 先打开登录首页,获取部分cookie
url = "https://passport.cnblogs.com/user/signin"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个ser-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
print s.cookies
# 添加登录需要的两个cookie
c = requests.cookies.RequestsCookieJar()
c.set('.CNBlogsCookie', 'xxx') # 填上面抓包内容
c.set('.Cnblogs.AspNetCore.Cookies','xxx') # 填上面抓包内容
s.cookies.update(c)
print s.cookies
# 登录成功后保存编辑内容
url2= "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR":"FE27D343",
"Editor$Edit$txbTitle":"这是绕过登录的标题:上海-悠悠",
"Editor$Edit$EditorBody":"<p>这里是中文内容:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished":"on",
"Editor$Edit$Advanced$chkDisplayHomePage":"on",
"Editor$Edit$Advanced$chkComments":"on",
"Editor$Edit$Advanced$chkMainSyndication":"on",
"Editor$Edit$lkbDraft":"存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
print r.content
2.8 json数据处理
前言
有些post的请求参数是json格式的,这个前面第二篇post请求里面提到过,需要导入json模块处理。
一般常见的接口返回数据也是json格式的,我们在做判断时候,往往只需要提取其中几个关键的参数就行,这时候就需要json来解析返回的数据了。
一、json模块简介
1.Json简介:Json,全名 JavaScript Object Notation,是一种轻量级的数据交换格式,常用于http请求中
2.可以用help(json),查看对应的源码注释内容:
Encoding basic Python object hierarchies::
>>> import json
>>> json.dumps(['foo', {'bar': ('baz', None, 1.0, 2)}])
'["foo", {"bar": ["baz", null, 1.0, 2]}]'
>>> print json.dumps("\"foo\bar")
"\"foo\bar"
>>> print json.dumps(u'\u1234')
"\u1234"
>>> print json.dumps('\\')
"\\"
>>> print json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True)
{"a": 0, "b": 0, "c": 0}
>>> from StringIO import StringIO
>>> io = StringIO()
>>> json.dump(['streaming API'], io)
>>> io.getvalue()
'["streaming API"]'
二、Encode(python->json)
1.首先说下为什么要encode,python里面bool值是True和False,json里面bool值是true和false,并且区分大小写,这就尴尬了,明明都是bool值。
在python里面写的代码,传到json里,肯定识别不了,所以需要把python的代码经过encode后成为json可识别的数据类型。
2.举个简单例子,下图中dict类型经过json.dumps()后变成str,True变成了true,False变成了fasle
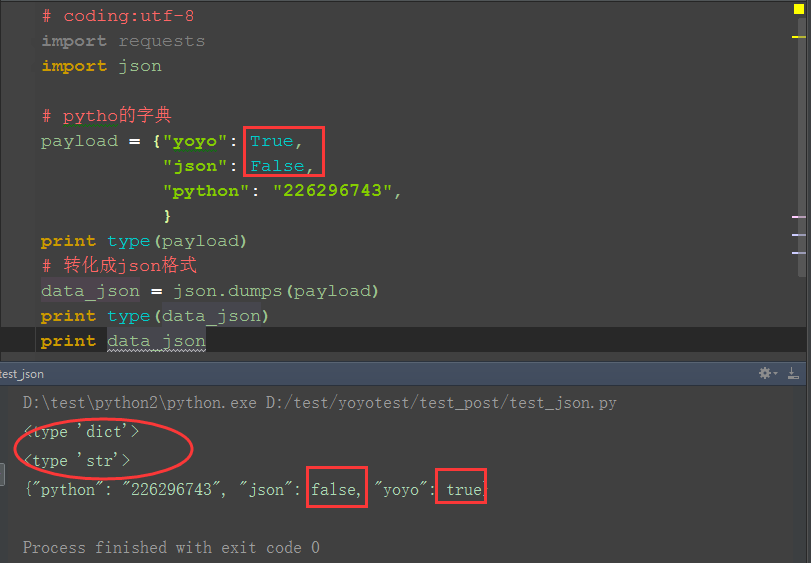
3.以下对应关系表是从json模块的源码里面爬出来的.python的数据类,经过encode成json的数据类型,对应的表如下:
| | Python | JSON |
| +===================+===============+
| | dict | object |
| +-------------------+---------------+
| | list, tuple | array |
| +-------------------+---------------+
| | str, unicode | string |
| +-------------------+---------------+
| | int, long, float | number |
| +-------------------+---------------+
| | True | true |
| +-------------------+---------------+
| | False | false |
| +-------------------+---------------+
| | None | null |
| +-------------------+---------------+
三、decode(json->python)
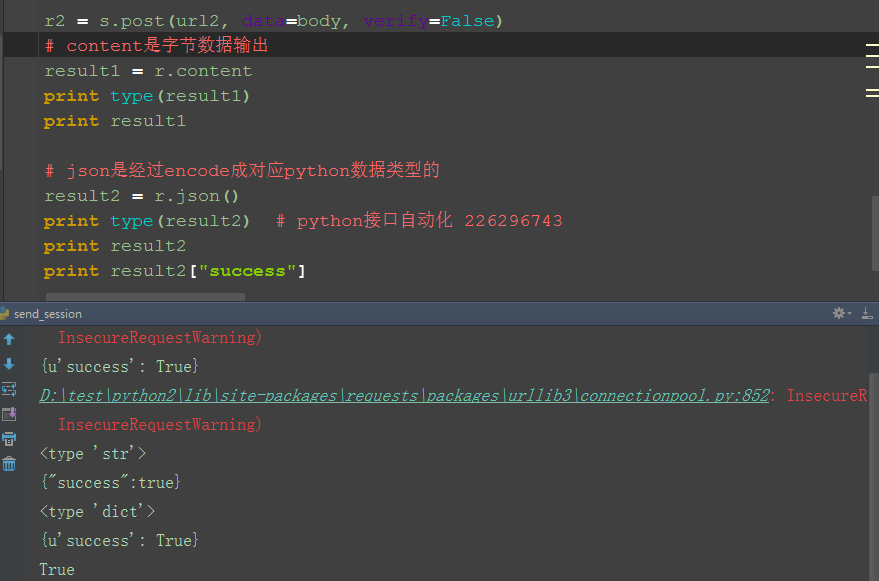
1.以第三篇的登录成功结果:{"success":true}为例,我们其实最想知道的是success这个字段返回的是True还是False
2.如果以content字节输出,返回的是一个字符串:{"success":true},这样获取后面那个结果就不方便了
3.如果经过json解码后,返回的就是一个字典:{u'success': True},这样获取后面那个结果,就用字典的方式去取值:result2["success"]
4.同样json数据转化成python可识别的数据,对应的表关系如下
| +---------------+-------------------+
| | JSON | Python |
| +===============+===================+
| | object | dict |
| +---------------+-------------------+
| | array | list |
| +---------------+-------------------+
| | string | unicode |
| +---------------+-------------------+
| | number (int) | int, long |
| +---------------+-------------------+
| | number (real) | float |
| +---------------+-------------------+
| | true | True |
| +---------------+-------------------+
| | false | False |
| +---------------+-------------------+
| | null | None |
| +---------------+-------------------+
四、案例分析
1.比如打开快递网:http://www.kuaidi.com/,搜索某个单号,判断它的状态是不是已签收
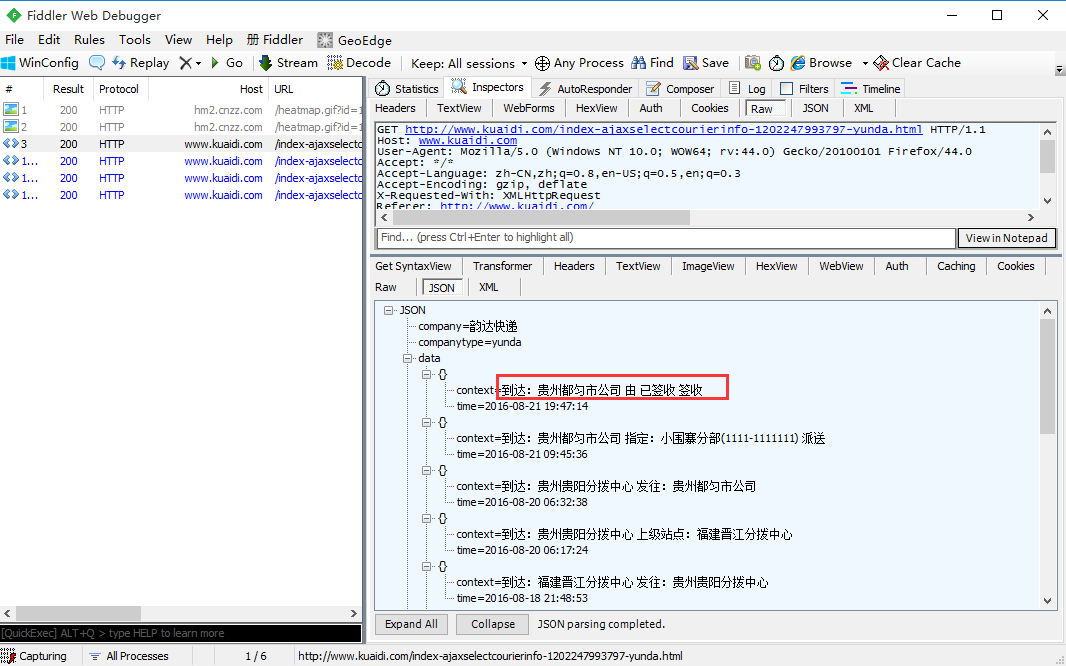
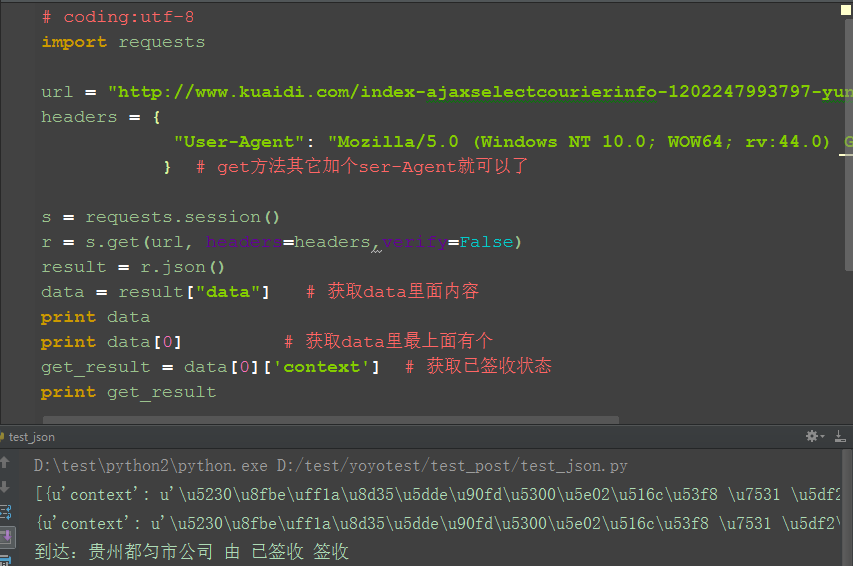
2. 实现代码如下
五、参考代码:
# coding:utf-8
import requests
url = "http://www.kuaidi.com/index-ajaxselectcourierinfo-1202247993797-yunda.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
} # get方法其它加个User-Agent就可以了
s = requests.session()
r = s.get(url, headers=headers,verify=False)
result = r.json()
data = result["data"] # 获取data里面内容
print data
print data[0] # 获取data里最上面的那个
get_result = data[0]['context'] # 获取已签收状态
print get_result
if u"已签收" in get_result:
print "快递单已签收成功"
else:
print "未签收"
2.9 重定向Location
前言
某屌丝男A鼓起勇气向女神B打电话表白,女神B是个心机婊觉得屌丝男A是好人,不想直接拒绝于是设置呼叫转移给闺蜜C了,最终屌丝男A和女神闺蜜C表白成功了,这种场景其实就是重定向了。
一、重定向
1. (Redirect)就是通过各种方法将各种网络请求重新定个方向转到其它位置,从地址A跳转到地址B了。
2.重定向状态码:
--301 redirect: 301 代表永久性转移(Permanently Moved)
--302 redirect: 302 代表暂时性转移(Temporarily Moved )
3.举个简单的场景案例,先登录博客园打开我的博客首页,进我的随笔编辑界面,记住这个地址:https://i.cnblogs.com/EditPosts.aspx?opt=1
4.退出博客园登录,把刚才我的随笔这个地址输入浏览器回车,抓包会看到这个请求状态码是302,浏览器地址栏瞬间刷新跳到登录首页去了
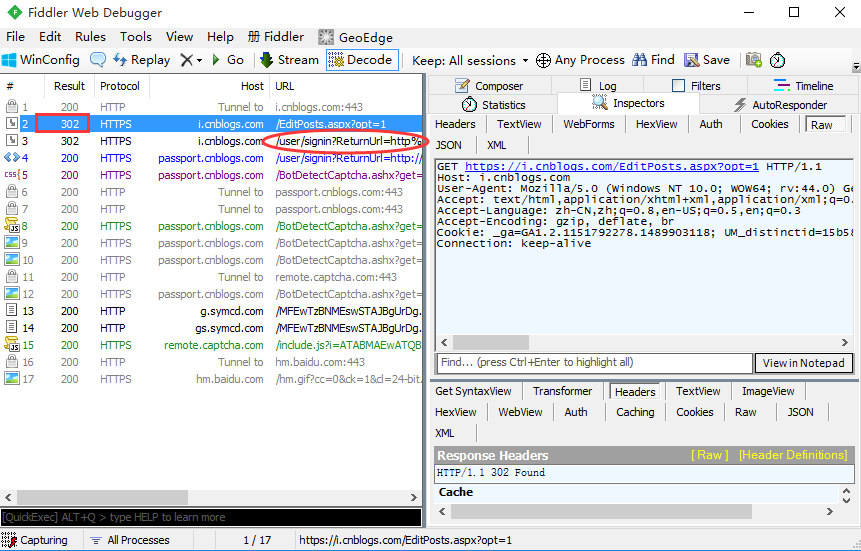
二、禁止重定向(allow_redirects)
1.用get方法请求:https://i.cnblogs.com/EditPosts.aspx?opt=1
2.打印状态码是200,这是因为requets库自动处理了重定向请求了
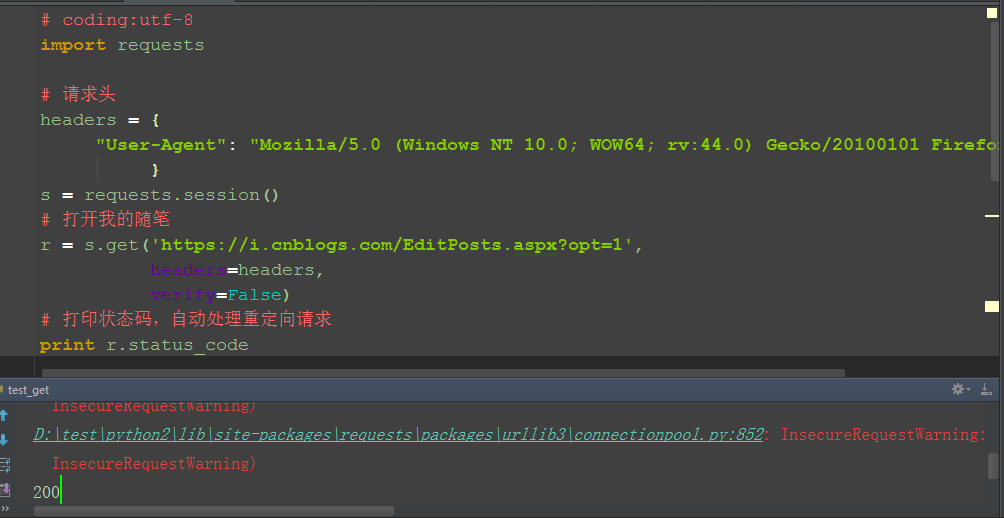
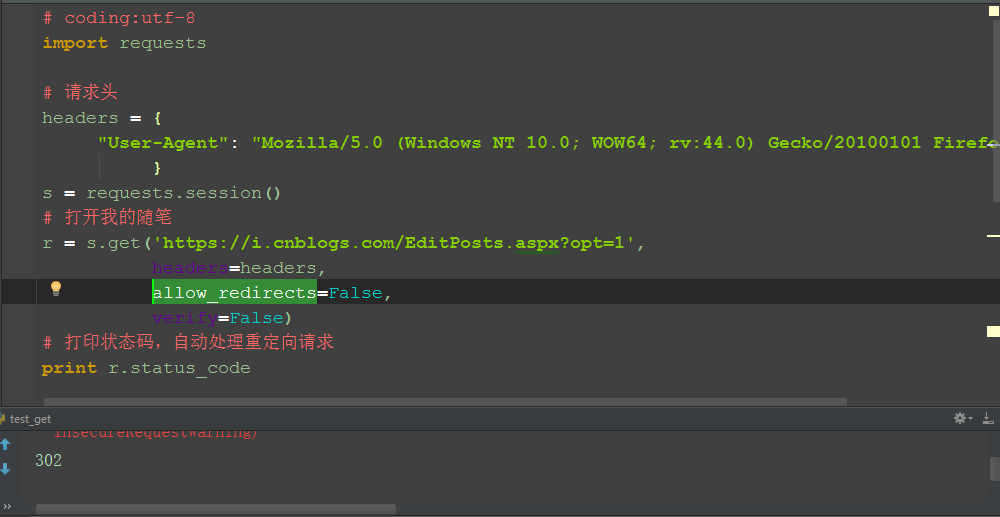
3.自动处理重定向地址后,我们就获取不到重定向后的url了,就无法走下一步,这里我们可以设置一个参数禁止重定向:allow_redirects=False
(allow_redirects=True是启动重定向),然后就可以看到status_code是302了
三、获取重定向后地址
1.在第一个请求后,服务器会下发一个新的请求链接,在response的headers里,如下抓包:Location
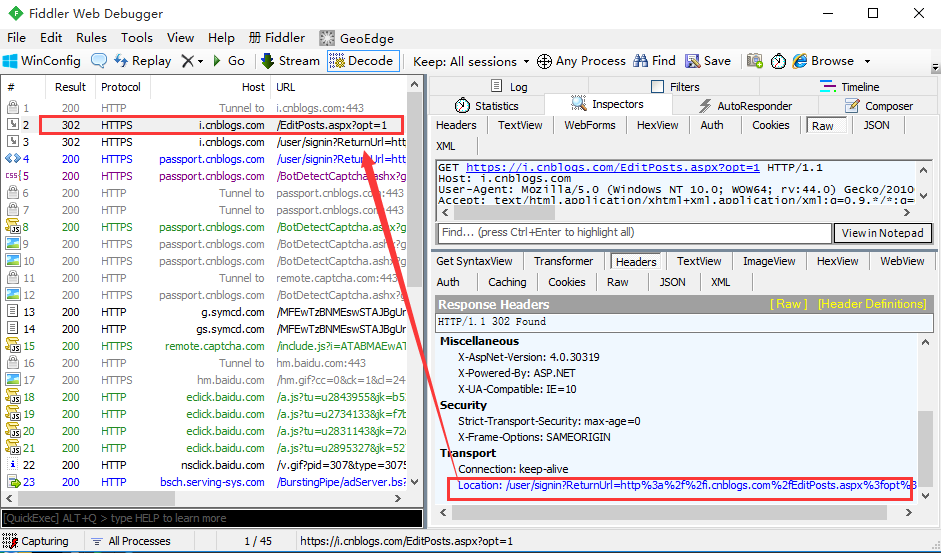
2.用脚本去获取Location地址
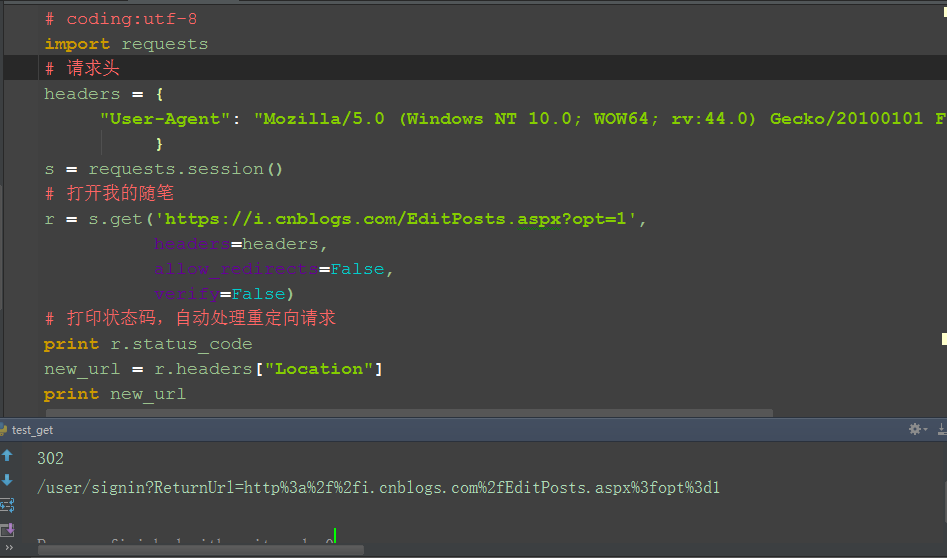
四、参考代码:
# coding:utf-8
import requests
# 请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0"
}
s = requests.session()
# 打开我的随笔
r = s.get('https://i.cnblogs.com/EditPosts.aspx?opt=1',
headers=headers,
allow_redirects=True,
verify=False)
# 打印状态码,自动处理重定向请求
print r.status_code
new_url = r.headers["Location"]
print new_url
2.10 参数关联
前言
我们用自动化发帖之后,要想接着对这篇帖子操作,那就需要用参数关联了,发帖之后会有一个帖子的id,获取到这个id,继续操作传这个帖子id就可以了
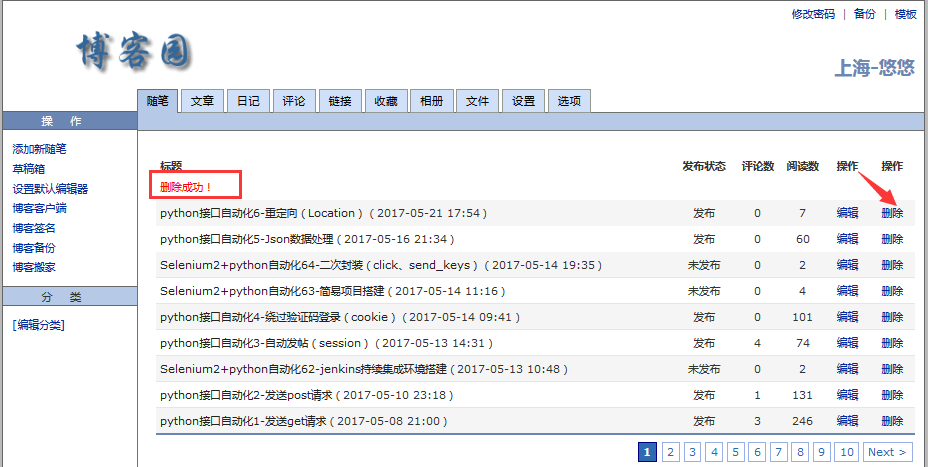
一、删除草稿箱
1.我们前面讲过登录后保存草稿箱,那可以继续接着操作:删除刚才保存的草稿
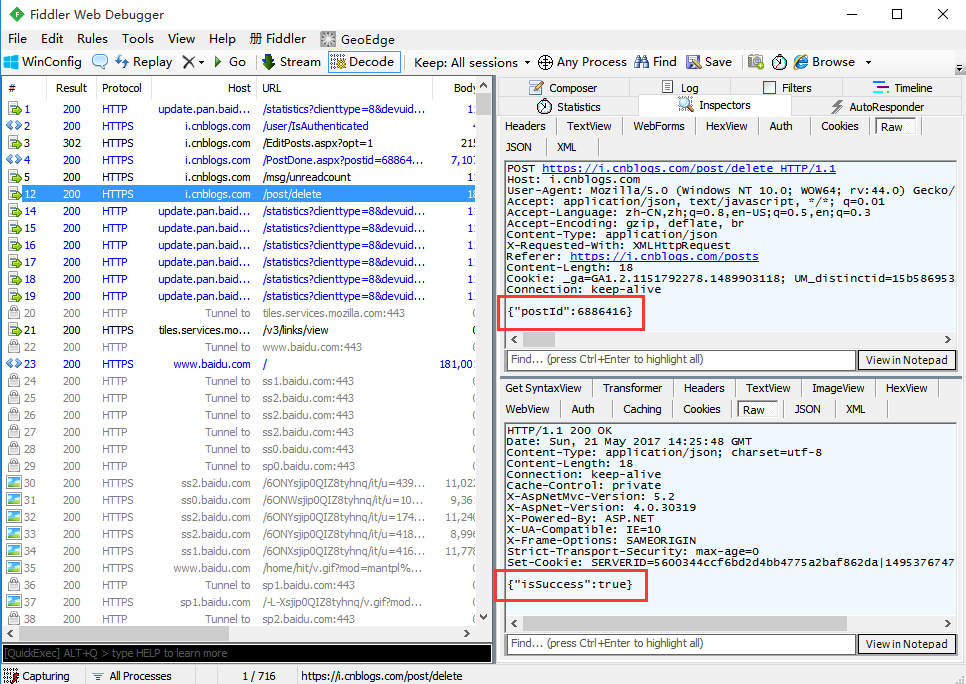
2.用fiddler抓包,抓到删除帖子的请求,从抓包结果可以看出,传的json参数是postId
3.这个postId哪里来的呢?可以看上个请求url地址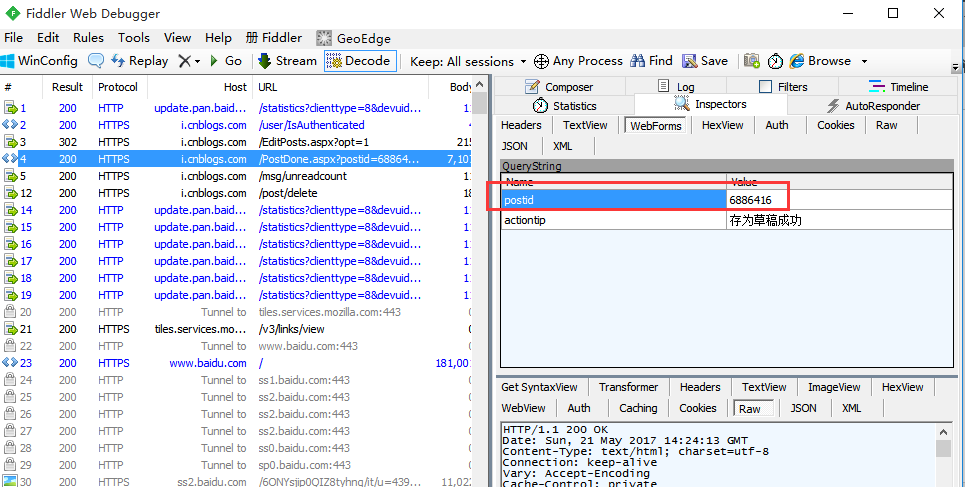
4.也就是说保存草稿箱成功之后,重定向一个url地址,里面带有postId这个参数。那接下来我们提取出来就可以了
二、提取参数
1.我们需要的参数postId是在保存成功后url地址,这时候从url地址提出对应的参数值就行了,先获取保存成功后url
2.通过正则提取需要的字符串,这个参数值前面(postid=)和后面(&)字符串都是固定的
3.这里正则提出来的是list类型,取第一个值就可以是字符串了(注意:每次保存需要修改内容,不能重复)
三,传参
1.删除草稿箱的json参数传上面取到的参数:{"postId": postid[0]}
2.json数据类型post里面填json就行,会自动转json
3.接着前面的保存草稿箱操作,就可以删除成功了
四、参考代码
# coding:utf-8
import requests
url = "https://passport.cnblogs.com/user/signin"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate, br",
"Content-Type": "application/json; charset=utf-8",
"X-Requested-With": "XMLHttpRequest",
"Content-Length": "",
"Cookie": "xxx已省略",
"Connection": "keep-alive"
}
payload = {
"input1": "xxx",
"input2": "xxx",
"remember": True}
# 第一步:session登录
s = requests.session()
r = s.post(url, json=payload, headers=headers, verify=False)
print r.json()
# 第二步:保存草稿
url2 = "https://i.cnblogs.com/EditPosts.aspx?opt=1"
body = {"__VIEWSTATE": "",
"__VIEWSTATEGENERATOR": "FE27D343",
"Editor$Edit$txbTitle": "这是我的标题:上海-悠悠",
"Editor$Edit$EditorBody": "<p>这里是中文内容:http://www.cnblogs.com/yoyoketang/</p>",
"Editor$Edit$Advanced$ckbPublished": "on",
"Editor$Edit$Advanced$chkDisplayHomePage": "on",
"Editor$Edit$Advanced$chkComments": "on",
"Editor$Edit$Advanced$chkMainSyndication": "on",
"Editor$Edit$lkbDraft": "存为草稿",
}
r2 = s.post(url2, data=body, verify=False)
# 获取当前url地址
print r2.url
# 第三步:正则提取需要的参数值
import re
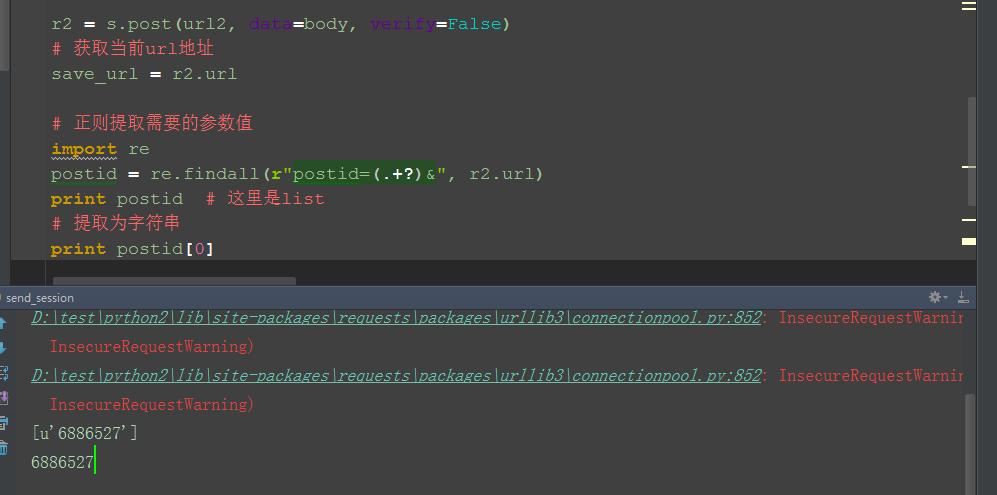
postid = re.findall(r"postid=(.+?)&", r2.url)
print postid # 这里是list
# 提取为字符串
print postid[0]
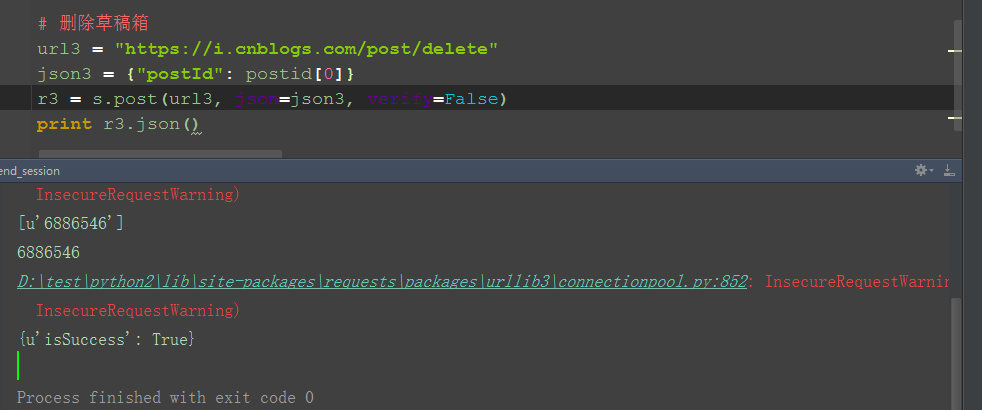
# 第四步:删除草稿箱
url3 = "https://i.cnblogs.com/post/delete"
json3 = {"postId": postid[0]}
r3 = s.post(url3, json=json3, verify=False)
print r3.json()
2.11 token登录
前言
有些登录不是用cookie来验证的,是用token参数来判断是否登录。
token传参有两种一种是放在请求头里,本质上是跟cookie是一样的,只是换个单词而已;另外一种是在url请求参数里,这种更直观。
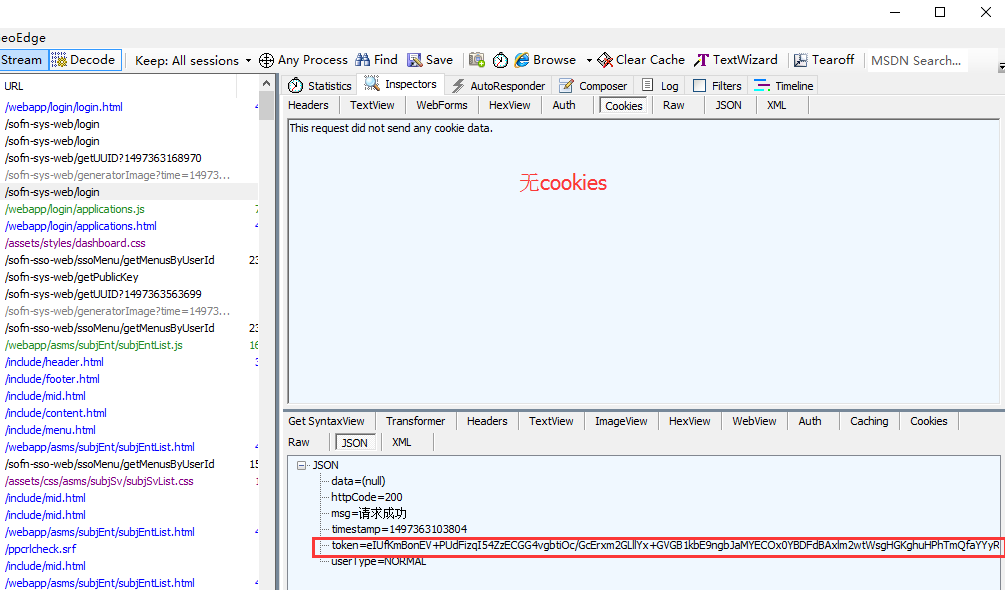
一、登录返回token
1.如下图的这个登录,无cookies
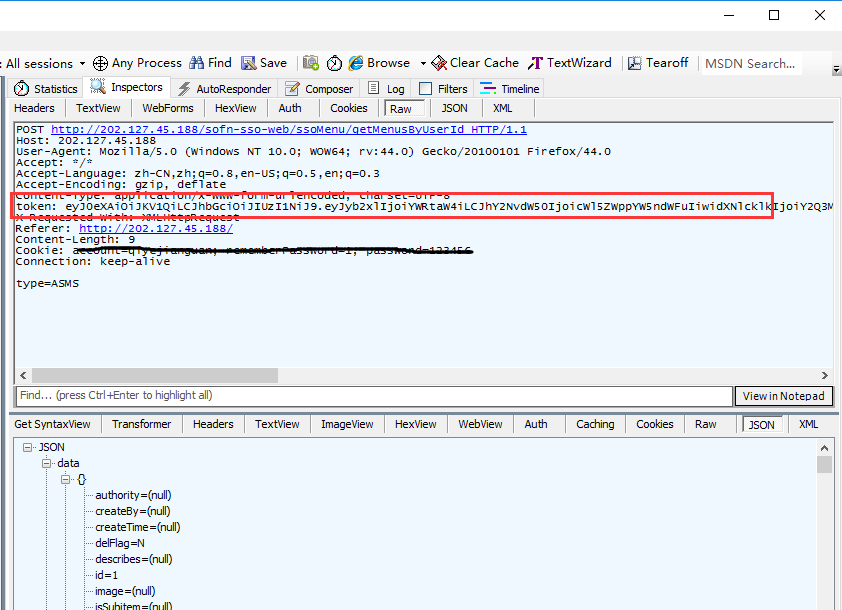
2.但是登录成功后有返回token
二、请求头带token
1.登录成功后继续操作其它页面,发现post请求的请求头,都会带token参数
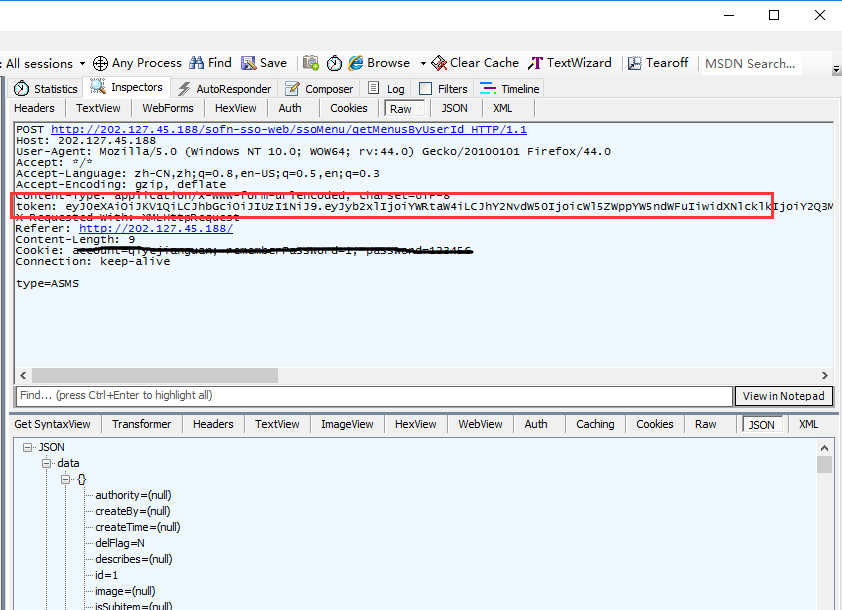
2.这种请求其实比cookie更简单,直接把登录后的token放到头部就行
三、token关联
1.用脚本实现登录,获取token参数,获取后传参到请求头就可以了
2.如果登录有验证码,前面的脚本登录步骤就省略了,自己手动登录后获取token
# coding:utf-8
import requests
header = { # 登录抓包获取的头部
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "*/*",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"X-Requested-With": "XMLHttpRequest",
"Content-Length": "",
"Connection": "keep-alive"
}
body = {"key1": "value1",
"key2": "value2"} # 这里账号密码就是抓包的数据
s = requests.session()
login_url = "http://xxx.login" # 自己找带token网址
login_ret = s.post(login_url, headers=header, data=body)
# 这里token在返回的json里,可以直接提取
token = login_ret.json()["token"]
# 这是登录后发的一个post请求
post_url = "http://xxx"
# 添加token到请求头
header["token"] = token
# 如果这个post请求的头部其它参数变了,也可以直接更新
header["Content-Length"]=""
body1 = {
"key": "value"
}
post_ret = s.post(post_url, headers=header, data=body1)
print post_ret.content
2.12登录案例分析(csrfToken)
前言:
有些网站的登录方式跟前面讲的博客园cookies登录和token登录会不一样,把csrfToken放到cookies里,登录前后cookies是没有任何变化的,这种情况下如何绕过前端的验证码登录呢?
一、登录前后对比
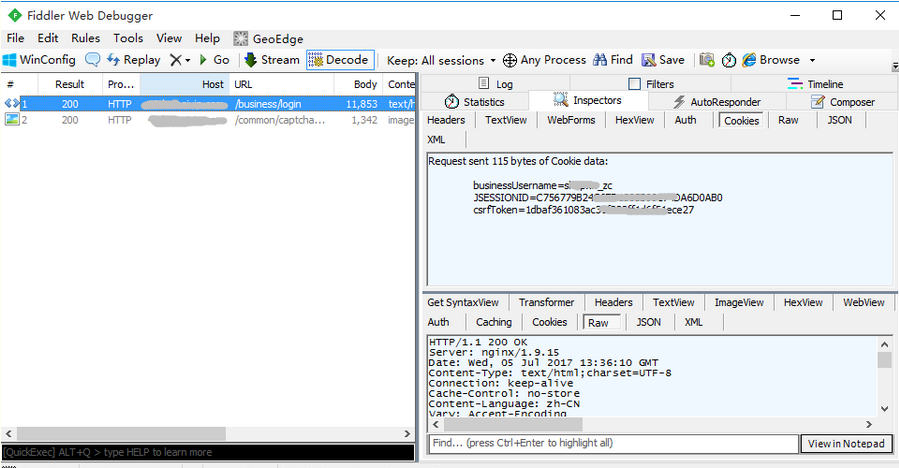
1.如果登录页面有图形验证码,这种我们一般都是绕过登录的方式,如下图通过抓包分析,首先不输入密码,抓包
(由于这个是别人公司内部网站,所以网址不能公开,仅提供解决问题的思路)
2.在登录页面输入账号和密码手动登录后,抓包信息如下
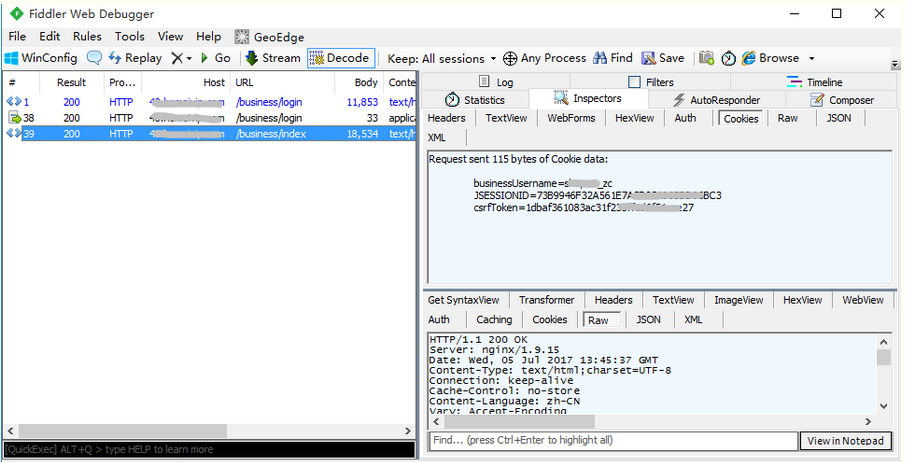
3.抓包后cookies信息在登录前后没任何变化,这里主要有三个参数:
--businessUsername:这个是账号名称
--JSESSIONID: 这个是一串字符串,主要看这个会不会变(一般有有效期)copy出来就行
--csrfToken: 这个是一串字符串,主要看这个会不会变(一般有有效期)copy出来就行
二、get请求
1.像这种登录方式的get请求,请求头部cookie没任何变化,这种可以直接忽略登录,不用管登录过程,直接发请求就行
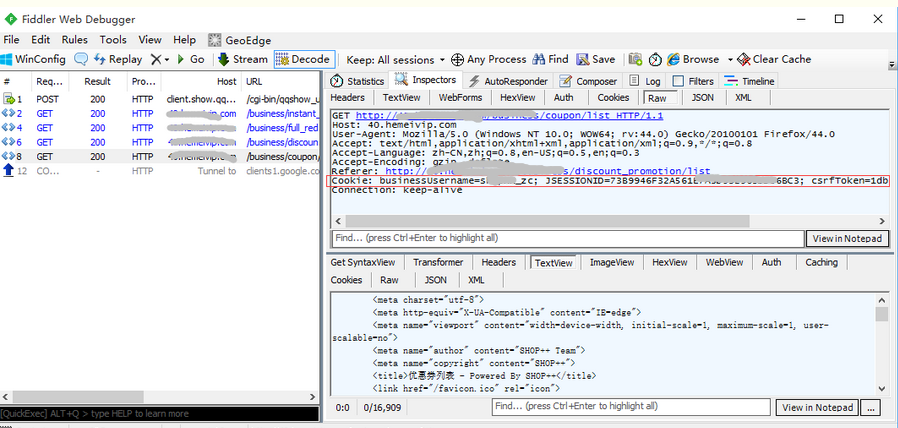
2.代码实现
# coding:utf-8
import requests
# 优惠券列表
url = 'http://xxx/xxx/coupon/list'
h = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:44.0) Gecko/20100101 Firefox/44.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Cookie": "csrfToken=xxx(复制抓包的信息); JSESSIONID=xxx(复制抓包的信息); businessUsername=(用户名)",
"Connection": "keep-alive"
}
r = requests.get(url, headers=h)
print r.content
三、post请求遇到的坑
1.post请求其实也可以忽略登录的过程,直接抓包把cookie里的三个参数(businessUsername、JSESSIONID、csrfToken)加到头部也是可以的。
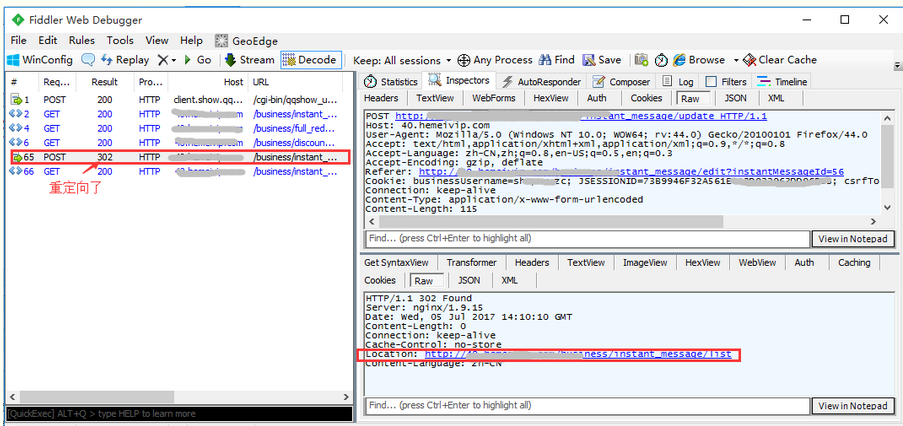
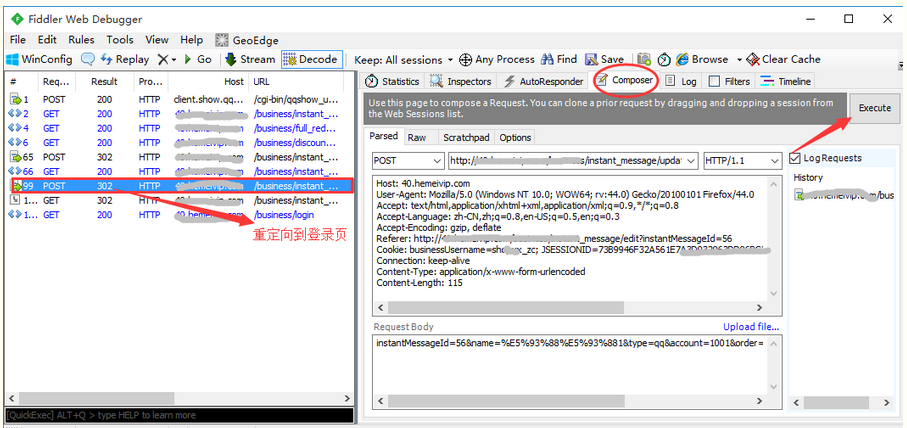
2.但是这里遇到一个坑:用Composer发请求,重定向回到登录页了
3.主要原因:重定向的请求,cookie参数丢失了
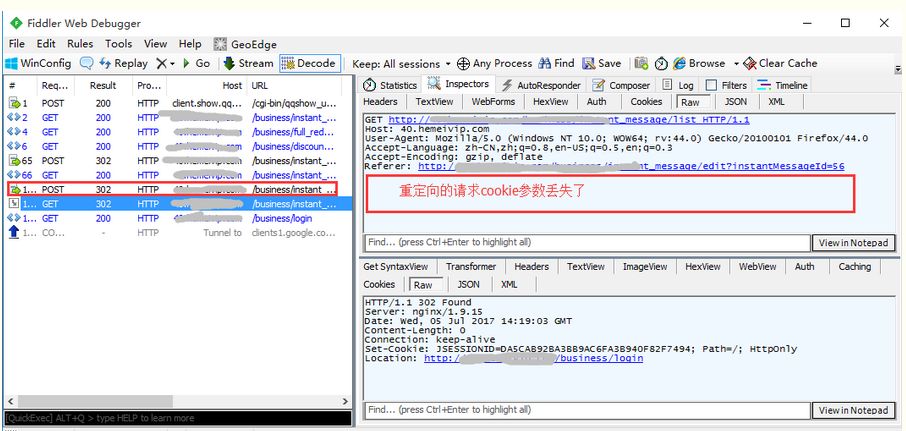
四、重定向
1.解决上面问题,其实很简单,把重定向禁用(具体看2.8重定向Location这篇)后的链接获取到,重新发个get请求,头部带上cookies的三个参数就行了
# coding:utf-8
import requests
# 主要是post请求后重定向,cookie丢失,所以回到登录页面了
# 解决办法,禁止重定向,获取重定向的url后,重新发重定向的url地址请求就行了
# 三个主要参数
csrfToken = '获取到的csrftoken,一般有有效期的'
jsessionId = '获取到的jsessionid'
userName = '用户名'
url = 'http://xxx/xxxx/update'
h1 = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Cookie": "csrfToken=%s; JSESSIONID=%s; businessUsername=%s" % (csrfToken, jsessionId, userName),
"Connection": "keep-alive",
"Content-Type": "application/x-www-form-urlencoded",
"Content-Length": ""
}
body = {"instantMessageId":"",
"name": u"哈哈1",
"order": "",
"csrfToken": csrfToken,
"type": "qq",
"account": ""}
s = requests.session()
r1 = s.post(url, headers=h1, data=body, allow_redirects=False)
print r1.status_code
# 获取重定向的url地址
redirect_url = r1.headers["Location"]
print redirect_url
h2 = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:46.0) Gecko/20100101 Firefox/46.0",
"Accept":
"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding": "gzip, deflate",
"Cookie": "csrfToken=%s; JSESSIONID=%s; businessUsername=%s" % (csrfToken, jsessionId, userName),
"Connection": "keep-alive"
}
r2 = s.get(redirect_url, headers=h2)
print r2.content
Python+Requests接口测试教程(2):的更多相关文章
- Python+Requests接口测试教程(1):Fiddler抓包工具
本书涵盖内容:fiddler.http协议.json.requests+unittest+报告.bs4.数据相关(mysql/oracle/logging)等内容.刚买须知:本书是针对零基础入门接口测 ...
- Python+Requests接口测试教程(2):requests
开讲前,告诉大家requests有他自己的官方文档:http://cn.python-requests.org/zh_CN/latest/ 2.1 发get请求 前言requests模块,也就是老污龟 ...
- python requests 接口测试
1.get方法请求接口 url:显而易见,就是接口的地址url啦 headers:请求头,例如:content-type = application/x-www-form-urlencoded par ...
- python requests接口测试
Python 标准库中的 urllib2 模块提供了你所需要的大多数 HTTP 功能,但是它的 API 太渣了.它是为另一个时代.另一个互联网所创建的.它需要巨量的工作,甚至包括各种方法覆盖,来完成最 ...
- python requests接口测试系列:连接mysql,获取mysql查询的值作为接口的入参
主要思路: 连接mysql数据库,这里数据库需要使用Proxifier来设置代理,然后才能正常连接 获取mysql数据库中某一数据,作为接口的参数信息 将接口返回结果保存至csv数据表中 # -*- ...
- 转载:python + requests实现的接口自动化框架详细教程
转自https://my.oschina.net/u/3041656/blog/820023 摘要: python + requests实现的接口自动化框架详细教程 前段时间由于公司测试方向的转型,由 ...
- python + requests实现的接口自动化框架详细教程
前段时间由于公司测试方向的转型,由原来的web页面功能测试转变成接口测试,之前大多都是手工进行,利用postman和jmeter进行的接口测试,后来,组内有人讲原先web自动化的测试框架移驾成接口的自 ...
- python+requests接口自动化测试框架实例详解教程
1.首先,我们先来理一下思路. 正常的接口测试流程是什么? 脑海里的反应是不是这样的: 确定测试接口的工具 —> 配置需要的接口参数 —> 进行测试 —> 检查测试结果(有的需要数据 ...
- 基于python+requests的简单接口测试
在进行接口测试时,我们可以使用已有的工具(如:jmeter)进行,也可以使用python+requests进行.以下为简单的接口测试模板: 一.提取常用变量,统一配置 新建一个config.py文件, ...
随机推荐
- matlab图片清晰度调整
打开.fig文件后: 1.首先设置窗口中的文字大小和相关的图例 2.然后将窗口缩小到要在word中或者ppt中展示图片的大小(避免图片缩小减少清晰度) 3.调整横纵坐标说明,使得布局合理 4.点击Ei ...
- HDOJ-2006求奇数的乘积
Problem Description 给你n个整数,求他们中所有奇数的乘积. Input 输入数据包含多个测试实例,每个测试实例占一行,每行的第一个数为n,表示本组数据一共有n个,接着是n个整数 ...
- [JAVASCRIPT]实现页面复制至电脑剪贴板
一. 方法 方1: window.clipboarddata 可惜不支持chrome , chrome 下会提示找不到 clipboarddata 对象 方2: 采用国外大牛写的ZeroClipbo ...
- Java 程序员技能导图 1.0
做Java开发已经一年,并非科班出身,在毕业工作三年后毅然决然辞职,参加培训机构从零开始.在这期间迷茫.失望.绝望时常伴我左右,但是在不断自我提高与努力中渐渐看到一些小小的成果使我不断坚信自己的选择并 ...
- 性能测试——jmeter环境搭建,录制脚本,jmeter参数化CSV
一.Jmeter+jdk环境搭建 1.http://www.oracle.com/technetwork/java/javase/downloads/index.html,下载jdk. 直接安装就行了 ...
- 使用Modelsim进行简单仿真
这里记载一下使用modelsim进行简单的仿真,方便以后使用的时候进行查看.所谓的简单的仿真,就是没有IP核.只用图形界面不用tcl脚本进行的仿真.简单的仿真步骤为: 1.改变路径到工作环境下的路径下 ...
- 【.net 深呼吸】在配置节中使用元素集合
前一篇博文中,老周介绍了自定义配置节的方法,本文咱们再往深一层,再看看如何在自定义的配置节中使用配置元素集合. 前面咱们说过,Configuration Section是特殊的配置元素,它可以包装一类 ...
- python--DenyHttp项目(2)--ACM监考客户端测试版(1阶段客户端总结)
客户端: 1.既然脚本是让别人用的,怎么说也得有个界面,(虽然很low) ''' DenyManager.py 调用客户端与客户端界面 ''' from DenyClient import * fro ...
- golang 的 http cookie 用法
golang的http cookie用法 在服务端程序开发的过程中,cookie经常被用于验证用户登录.golang 的 net/http 包中自带 http cookie的定义,下面就来讲一下coo ...
- 国内首款开源的互联网支付系统roncoo-pay
roncoo-pay是国内首款开源的互联网支付系统,其核心目标是汇聚所有主流支付渠道,打造一款轻量.便捷.易用,且集支付.资金对账.资金清结算于一体的支付系统,满足互联网业务系统的收款和业务资金管理需 ...