Redis大幅性能提升之Batch批量读写
Redis大幅性能提升之Batch批量读写
提示:本文针对的是StackExchange.Redis
一、问题呈现
前段时间在开发的时候,遇到了redis批量读的问题,由于在StackExchange.Redis里面我确实没有找到PipeLine命令,找到的是Batch命令,因此对其用法进行了探究一下。
下面的代码是我之前写的:
public List<StudentEntity> Get(List<int> ids)
{
List<StudentEntity> result = new List<StudentEntity>();
try
{
var db = RedisCluster.conn.GetDatabase();
foreach (int id in ids.Keys)
{
string key = KeyManager.GetKey(id);
var dic = db.HashGetAll(key).ToDictionary(k => k.Name, v => v.Value);
StudentEntity se = new StudentEntity();
if (dic.Keys.Contains(StudentEntityRedisHashKey.id.ToString()))
{
pe.id = FormatUtils.ConvertToInt32(dic[StudentEntityRedisHashKey.id.ToString()], -);
}
if (dic.Keys.Contains(StudentEntityRedisHashKey.name.ToString()))
{
pe.name= dic[StudentEntityRedisHashKey.name.ToString()];
}
result.Add(se);
}
catch (Exception ex)
{
}
return result;
}
从上面的代码中可以看出,并不是批量读,经过性能测试,性能确实是要远远低于用Batch操作,因为HashGetAll方法被执行了多次。
下面给出批量方法:
二、解决问题方法
具体的用法是:
var batch = db.CreateBatch();
...//这里写具体批量操作的方法
batch.Execute();
2.1批量写:
具体代码:
public bool InsertBatch(List<StudentEntity> seList)
{
bool result = false;
try
{
var db = RedisCluster.conn.GetDatabase();
var batch = db.CreateBatch();
foreach (var se in seList)
{
string key = KeyManager.GetKey(se.id);
batch.HashSetAsync(key, StudentEntityRedisHashKey.id.ToString(), te.id);
batch.HashSetAsync(key, StudentEntityRedisHashKey.name.ToString(), te.name);
}
batch.Execute();
result = true;
}
catch (Exception ex)
{
}
return result;
}
这个方法里执行的是批量插入学生实体数据,这里只是针对Hash,其它的也一样操作。
2.2批量读:
具体代码:
public List<StudentEntity> GetBatch(List<int> ids)
{
List<StudentEntity> result = new List<StudentEntity>();
List<Task<StackExchange.Redis.HashEntry[]>> valueList = new List<Task<StackExchange.Redis.HashEntry[]>>();
try
{
var db = RedisCluster.conn.GetDatabase();
var batch = db.CreateBatch();
foreach(int id in ids)
{
string key = KeyManager.GetKey(id);
Task<StackExchange.Redis.HashEntry[]> tres = batch.HashGetAllAsync(key);
valueList.Add(tres);
}
batch.Execute(); foreach(var hashEntry in valueList)
{
var dic = hashEntry.Result.ToDictionary(k => k.Name, v => v.Value);
StudentEntity se= new StudentEntity();
if (dic.Keys.Contains(StudentEntityRedisHashKey.id.ToString()))
{
se.id= FormatUtils.ConvertToInt32(dic[StudentEntityRedisHashKey.id.ToString()], -);
}
if (dic.Keys.Contains(StudentEntityRedisHashKey.name.ToString()))
{
se.name= dic[StudentEntityRedisHashKey.name.ToString()];
}
result.Add(se);
}
}
catch (Exception ex)
{
}
return result;
}
这个方法是批量读取学生实体数据,批量拿到实体数据后,将其转化成我们需要的数据。下面给出性能对比。
2.3性能对比:
10条数据,约4-5倍差距:
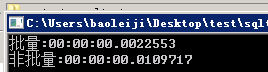
1000条数据,约28倍的差距:
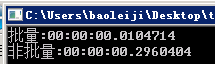
随着数据了增多,差距将越来越大。
三、源码测试案例
上面是批量读写实体数据,下面给出StackExchange.Redis源码测试案例里的批量读写写法:
public void TestBatchSent()
{
using (var muxer = Config.GetUnsecuredConnection())
{
var conn = muxer.GetDatabase();
conn.KeyDeleteAsync("batch");
conn.StringSetAsync("batch", "batch-sent");
var tasks = new List<Task>();
var batch = conn.CreateBatch();
tasks.Add(batch.KeyDeleteAsync("batch"));
tasks.Add(batch.SetAddAsync("batch", "a"));
tasks.Add(batch.SetAddAsync("batch", "b"));
tasks.Add(batch.SetAddAsync("batch", "c"));
batch.Execute(); var result = conn.SetMembersAsync("batch");
tasks.Add(result);
Task.WhenAll(tasks.ToArray()); var arr = result.Result;
Array.Sort(arr, (x, y) => string.Compare(x, y));
...
}
}
这个方法里也给出了批量写和读的操作。
好了,先说到这里了。
查看原文:http://www.cnblogs.com/zhangtingzu/
下面给出一些相关的参考文档:
1.http://www.cnblogs.com/huangxincheng/p/6212406.html
2.http://blog.csdn.net/ma_jiang/article/details/57085586
Redis大幅性能提升之Batch批量读写的更多相关文章
- redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value 就是具体的customerid集合, ...
- Spring Boot 2.2 正式发布,大幅性能提升 + Java 13 支持
之前 Spring Boot 2.2没能按时发布,是由于 Spring Framework 5.2 的发布受阻而推迟.这次随着 Spring Framework 5.2.0 成功发布之后,Spring ...
- Java Redis的Pipeline管道,批量操作,节省大量网络往返时间 & Redis批量读写(hmset&hgetall) 使用Pipeline
一般情况下,大家使用redis去put/get都是先拿到一个jedis实例,然后操作,然后释放连接:这种模式是 请求-响应,请求-响应 这种模式,下一次请求必须得等第一次请求响应回来之后才可以,因为r ...
- memcache 与 redis 为web app 带来的性能提升
memcache 与 redis 为web app 带来的性能提升 参考: 1. http://www.cnblogs.com/ToDoToTry/p/3513688.html
- spring batch批量处理框架
spring batch精选,一文吃透spring batch批量处理框架 前言碎语 批处理是企业级业务系统不可或缺的一部分,spring batch是一个轻量级的综合性批处理框架,可用于开发企业信息 ...
- TOP100summit:【分享实录-华为】微服务场景下的性能提升最佳实践
本篇文章内容来自2016年TOP100summit华为架构部资深架构师王启军的案例分享.编辑:Cynthia 王启军:华为架构部资深架构师.负责华为的云化.微服务架构推进落地,前后参与了华为手机祥云4 ...
- 重构、插件化、性能提升 20 倍,Apache DolphinScheduler 2.0 alpha 发布亮点太多!
点击上方 蓝字关注我们 社区的小伙伴们,好消息!经过 100 多位社区贡献者近 10 个月的共同努力,我们很高兴地宣布 Apache DolphinScheduler 2.0 alpha 发布.这是 ...
- paip.cache 缓存架构以及性能提升总结
paip.cache 缓存架构以及性能提升总结 1 缓存架构以及性能(贯穿读出式(LookThrough) 旁路读出式(LookAside) 写穿式(WriteThrough) 回写式 ...
- VNF网络性能提升解决方案及实践
VNF网络性能提升解决方案及实践 2016年7月 作者: 王智民 贡献者: 创建时间: 2016-7-20 稳定程度: 初稿 修改历史 版本 日期 修订人 说明 1.0 20 ...
随机推荐
- Anaconda配置多spyder多python环境
作者:桂. 时间:2017-04-17 22:02:37 链接:http://www.cnblogs.com/xingshansi/p/6725298.html 前言 最近在看<统计学习方法 ...
- Jquery Validation 验证控件的使用说明
转载自:http://blog.csdn.net/huang100qi/article/details/52453970,做了一些简化及修改 下载地址:https://jqueryvalidation ...
- 光场相机重聚焦之二——Lytro Illum记录光场
上一节中大概讲述了光场相机和光场的参数化表示,这一节就说一下光场相机内部是如何记录光场以及实现重聚焦的. 博主用的是Lytro Illum,所以就以Illum为例来说了,Illum的功能还是挺多的,上 ...
- C#处理JSON 数据
网络中数据传输经常是xml或者json,现在做的一个项目之前调其他系统接口都是返回的xml格式,刚刚遇到一个返回json格式数据的接口,通过例子由易到难总结一下处理过程,希望能帮到和我一样开始不会的朋 ...
- 【从无到有】教你使用animation做简单的动画效果
今天写写怎么用animation属性做一些简单的动画效果 在CSS选择器中,使用animition动画属性,调用声明好的关键帧 首先声明一个动画(关键帧): @keyframes name{ from ...
- Swift、Objective-C 单例模式 (Singleton)
Swift.Objective-C 单例模式 (Singleton) 本文的单例模式分为严格单例模式和不严格单例模式.单例模式要求一个类有一个实例,有公开接口可以访问这个实例.严格单例模式,要求一个类 ...
- [内存管理]linux内存管理 之 内存节点和内存分区
Linux支持多种硬件体系结构,因此Linux必须采用通用的方法来描述内存,以方便对内存进行管理.为此,Linux有了内存节点.内存区.页框的概念,这些概念也是一目了然的. 内存节点:主要依据CPU访 ...
- .NET Core 2.0体验
.NET Core 2.0预览版及.NET Standard 2.0 Preview 这个月也就要发布了. 具体相关信息可以查看之前的文章.NET Core 2.0及.NET Standard 2.0 ...
- Java static 关键字详解
引言 在<Java编程思想>中有这样一段话:static方法就是没有this的方法.在static方法内部不能调用非静态方法,反过来是可以的.而且可以在没有创建任何对象的前提下,仅仅通过类 ...
- (原创)如何在性能测试中自动生成并获取Oracle AWR报告
版权声明:本文为原创文章,转载请先联系并标明出处 由于日常使用最多的数据库为Oracle,因此,最近又打起了Oracle的AWR报告的主意. 过去我们执行测试,都是执行开始和结束分别手动建立一个快照, ...