识别同音字词pypinyin, 分词 jieba
一.pypinyin
在处理语音输入指令时, 比如 请给圆圆发消息,那么转化为文字识别时, 无法确定转换的是圆圆还是园园或是源源, 为了解决这个问题, 就把指令转换为拼音来处理,这样就可以处理同音字了.用到的库为pypinyin
 简单使用, TONE,TONE2,TONE3为不同转换模式
简单使用, TONE,TONE2,TONE3为不同转换模式
from pypinyin import lazy_pinyin,TONE,TONE2,TONE3 a = '圆圆'
b = '源源'
c = '园园' print(''.join(lazy_pinyin(a, style=TONE)))
print(''.join(lazy_pinyin(b, style=TONE2)))
print(''.join(lazy_pinyin(c, style=TONE3))) #结果
yuányuán
yua2nyua2n
yuan2yuan2
二 jieba
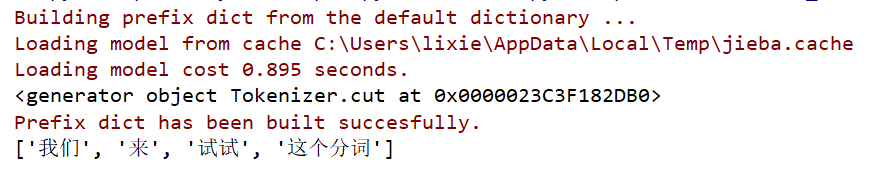
import jieba a = '我们来试试这个分词'
print(jieba.cut(a)) # <generator object Tokenizer.cut at 0x0000019C3F4523B8> print(list(jieba.cut(a)))

import jieba
jieba.add_word('这个分词') # 添加分词
a = '我们来试试这个分词'
print(jieba.cut(a)) # <generator object Tokenizer.cut at 0x0000019C3F4523B8>
print(list(jieba.cut(a)))
这个模块仅对中文支持友好,英文什么的就不好用了.如果想用英文分词的话,在google的tensorflow里面有一个功能很好用
识别同音字词pypinyin, 分词 jieba的更多相关文章
- 转]python 结巴分词(jieba)学习
原文 http://www.gowhich.com/blog/147 主题 中文分词Python 源码下载的地址:https://github.com/fxsjy/jieba 演示地址:http:/ ...
- 中文分词-jieba
支持三种分词模式: 精确模式,试图将句子最精确地切开,适合文本分析: 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义: 搜索引擎模式,在精确模式的基础上,对长词再次切分 ...
- python 结巴分词(jieba)详解
文章转载:http://blog.csdn.net/xiaoxiangzi222/article/details/53483931 jieba “结巴”中文分词:做最好的 Python 中文分词组件 ...
- Python中文分词 jieba
三种分词模式与一个参数 以下代码主要来自于jieba的github,你可以在github下载该源码 import jieba seg_list = jieba.cut("我来到北京清华大学& ...
- .net中文分词 jieba.NET
简介 平时经常用Python写些小程序.在做文本分析相关的事情时免不了进行中文分词,于是就遇到了用Python实现的结巴中文分词.jieba使用起来非常简单,同时分词的结果也令人印象深刻,有兴趣的可以 ...
- python 全栈开发,Day133(玩具与玩具之间的对话,基于jieba gensim pypinyin实现的自然语言处理,打包apk)
先下载github代码,下面的操作,都是基于这个版本来的! https://github.com/987334176/Intelligent_toy/archive/v1.6.zip 注意:由于涉及到 ...
- 中文分词工具探析(二):Jieba
1. 前言 Jieba是由fxsjy大神开源的一款中文分词工具,一款属于工业界的分词工具--模型易用简单.代码清晰可读,推荐有志学习NLP或Python的读一下源码.与采用分词模型Bigram + H ...
- python环境jieba分词的安装
我的python环境是Anaconda3安装的,由于项目需要用到分词,使用jieba分词库,在此总结一下安装方法. 安装说明======= 代码对 Python 2/3 均兼容 * 全自动安装:`ea ...
- python第三方库------jieba库(中文分词)
jieba“结巴”中文分词:做最好的 Python 中文分词组件 github:https://github.com/fxsjy/jieba 特点支持三种分词模式: 精确模式,试图将句子最精确地切开, ...
随机推荐
- log4j日志整合输出(slf4j+commonslog+log4j+jdklogger)
log4j日志整合输出(slf4j+commonslog+log4j+jdklogger) 博客分类: 日志 J2EE项目中,经常会用到很多第三方的开源组件和软件,这些组件都使用各自的日志组件,比 ...
- win8 本地化
先看个简单的案例:新时尚Windows8开发(6):资源 & 本地化 http://www.silverlightchina.net/html/windows8/study/2012/0902 ...
- 20155312 2016-2017-2《Java程序设计》课程总结
20155312 2016-2017-2<Java程序设计>课程总结 每周作业链接汇总 预备作业1:你期望的师生关系是什么? 预备作业2:做中学learning by doing个人感想 ...
- hdu 6073
题意: 给出一个二部图,U.V分别是二部图的两个点集,其中,U中每个点会有两条边连到V中两个不同的点. 完美匹配定义为:所有点都成功匹配. 思路:已知一定是完美匹配了呀(也一定存在),我们先把度数为一 ...
- GUI的最终选择Tkinter模块初级篇
一.Tkinter模块的基本使用 1)实例化窗口程序 import tkinter as tk app = tk.Tk() app.title("FishC Demo") app. ...
- 交换机的Access口与Trunk口
基本概念 Access类型的端口只能属于1个VLAN,一般用于连接计算机的端口:Trunk类型的端口可以允许多个VLAN通过,可以接收和发送多个VLAN的报文,一般用于交换机之间连接的端口: 处理流程 ...
- 2-具体学习Github---init add commit log diff
1.安装: 首先找到git的官网,内部有下载链接. 也可以用下面的,我的是win7的64位系统: 可以在此处下载:Git-2.13.0-64-bit.exe链接:http://pan.baidu.co ...
- JDBC连接SQL Server数据库
测试环境 数据库:SQL Server 2008 R2,创建数据库名:TestDemo,表:User,字段如下: 字段 字段 id UName UPass sqljdbc.jar下载地址:依赖的J ...
- 批量插入,批量修改的sql
sql 1 批量插入 <insert id="batchInsert" useGeneratedKeys="true" parameterType=&q ...
- maven之web工程的搭建
参考之前jave application的工程创建的步骤,我们只需要修改最后一步 这样就创建了个web maven工程 与java application应用程序的区别,还有别的区别这里不做多的阐述. ...