spark historyserver 页面反应很慢 jvm堆调参
我们的spark historyserver 最近页面打开很慢
jstat -gcutil pid 1000
发现full gc 相当严重
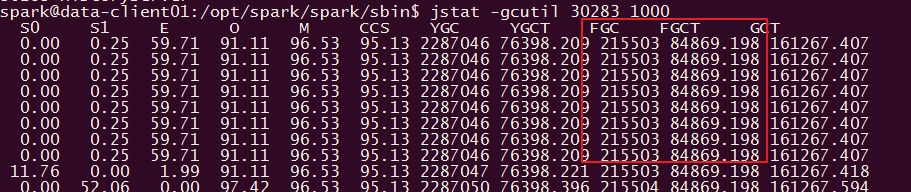
查看堆大小,发现默认堆1G,打算修改到4G
jps -lvm |grep pid
30283 org.apache.spark.deploy.history.HistoryServer -Xmx1g
步骤
vi spark-env.sh
# 加添
export SPARK_DAEMON_MEMORY=4096m
# 重启 historyserver服务
sbin/stop-history-server.sh
start-history-server.sh

大功告成!!!
spark historyserver 页面反应很慢 jvm堆调参的更多相关文章
- JVM虚拟机调参
一.堆大小设置JVM 中最大堆大小有三方面限制:相关操作系统的数据模型(32-bt还是64-bit)限制:系统的可用虚拟内存限制:系统的可用物理内存限制.32位系统下,一般限制在1.5G~2G:64为 ...
- 2 - JVM随笔分类(JVM堆的内存回收)
JVM常用的回收算法是: 标记/清除算法 标记/复制算法 标记/整理算法 其中上诉三种算法都先具备,标记阶段,通过标记阶段,得到当前存活的对象,然后再将非标记的对象进行清除,而对象内存中对象的标记过程 ...
- 【转】JVM 堆内存设置原理
堆内存设置 原理 JVM堆内存分为2块:Permanent Space 和 Heap Space. Permanent 即 持久代(Permanent Generation),主要存放的是Java类定 ...
- Hadoop作业JVM堆大小设置优化 [转]
前段时间,公司Hadoop集群整体的负载很高,查了一下原因,发现原来是客户端那边在每一个作业上擅自配置了很大的堆空间,从而导致集群负载很高.下面我就来讲讲怎么来现在客户端那边的JVM堆大小的设置.我们 ...
- JVM基础:深入学习JVM堆与JVM栈
转自:http://developer.51cto.com/art/201009/227812.htm JVM栈解决程序的运行问题,即程序如何执行,或者说如何处理数据;JVM堆解决的是数据存储的问题, ...
- 干货:JVM 堆内存和非堆内存
堆和非堆内存 按照官方的说法:"Java 虚拟机具有一个堆(Heap),堆是运行时数据区域,所有类实例和数组的内存均从此处分配.堆是在 Java 虚拟机启动时创建的."" ...
- JVM堆内存监测的一种方式,性能调优依旧任重道远
上月,由极客邦.InfoQ和听云联合主办2016 APMCon中国应用性能管理大会圆满落下帷幕.会上,Java冠军Martijn Verburg进行了一场Java and the Machine的分享 ...
- Spark大型电商项目实战-及其改良之番外(1)-将spark前端页面效果高效拷贝至博客
Spark大型电商项目实战-及其改良这个系列的时间轴展示图一直在变....1-3篇是用图直接表示时间轴,用一段简陋的html代码表示时间表.第4篇开始才是用比较完整的前端效果,能移动.缩放时间轴,鼠标 ...
- JDK8中JVM堆内存划分
一:JVM中内存 JVM中内存通常划分为两个部分,分别为堆内存与栈内存,栈内存主要用运行线程方法 存放本地暂时变量与线程中方法运行时候须要的引用对象地址. JVM全部的对象信息都 存放在堆内存中.相比 ...
随机推荐
- 黄聪:wordpress获取hook所有function
list_hooked_functions('wp_footer'); function list_hooked_functions($tag=false) { global $wp_filter; ...
- ALGO-22_蓝桥杯_算法训练_装箱问题(DP)
问题描述 有一个箱子容量为V(正整数,<=V<=),同时有n个物品(<n<=),每个物品有一个体积(正整数). 要求n个物品中,任取若干个装入箱内,使箱子的剩余空间为最小. 输 ...
- Espresso小试
Espresso开源了,那就试着用一下, 1. 下载Espresso Espresso没有提供单独的jar包下载,建议clone整个项目或者下载zip包 git clone https://code. ...
- Tomcat7启动分析(三)Digester的使用(转载)
原文 http://tyrion.iteye.com/blog/1912290 前一篇文章里最后看到Bootstrap的main方法最后会调用org.apache.catalina.startup.C ...
- docker启动时报错Error response from daemon: driver failed programming external connectivity on endpoint *
公司服务器由于断电重启,部署在docker服务上的一些web服务需要重新开启容器, [root@localhost ~]# docker ps CONTAINER ID IMAGE COMMAND C ...
- 一个windows计划任务的Nginx日志自动截断的批处理命令
net stop nginx taskkill /im nginx.exe /f cd E:\nginx e: set NO=%Date:~0,4%%Date:~5,2%%Date:~8,2% set ...
- Python多进程vs多线程
多任务的两种方式:多进程和多线程. 如果用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker. 如果用多线程实现Master-Worker,主线程就是Master, ...
- DateTimepicker中的星期问题
开发机:win10 64+VS2013 客户机:win7 32bit 在项目中使用DateTimepicker,需要将时间获取到,然后转换为string,然后再转换为DateTime类型.开发机器上测 ...
- jquery事件及插件
jquery事件 方法 描述 bind() 向匹配元素附加一个或更多事件处理器 blur() 触发.或将函数绑定到指定元素的 blur 事件 change() 触发.或将函数绑定到指定元素的 chan ...
- python re模块和collections
re模块下的常用方法 import re ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : [ ...