分布式计算课程补充笔记 part 1
▶ 高性能计算机发展历程
真空管电子计算机,向量机(Vector Machine),并行向量处理机(Parallel Vector Processors,PVP),分布式并行机(Parallel Processors,PP),对称多处理机(Symmetric Multiprocessors,SMP),分布式共享并行机(Distributed Share Memory,DSM),大规模并行机(Massively Parallel Processors, MPP),大规模加速并行机(Massively Parallel Processors with Accelerators, MPPA)
▶ 计算机体系架构
● 指令集架构 (Instruction Set Architecture, ISA):主要指处理器所支持的机器语言、数据类型、字长、内存与寄存器类型等,例子:x86, alpha, MIPS, RISC-V
● 微架构 (Micro-architecture, µarch):主要指 ISA 的一种具体的处理器实现,比如处理器核数、缓存大小、流水线长度等,例子:Intel Xeon E5 处理器
● 系统架构 (System Architecture):主要指与处理器不直接相关的其他部分,比如访存、I/O、网络、软件等
■ Harvard 架构:将指令 (即程序) 与数据存储在不同的内存中。
■ Princeton 架构:将指令 (即程序) 与数据共同存储在内存。仅具有单一的线性内存,指令与数据仅在使用时才隐式区分;总性能往往受限于内存的读写总线所能提供的延迟和带宽。
● 提高处理器性能的其他重要手段
■ 简化指令 (Simplified Instruction):复杂指令集计算机 (Complex Instruction Set Computer, CISC);精简指令集计算机 (Reduced Instruction Set Computer, RISC);
■ 指令级并行 (Instruction Level Parallelism, ILP):超标量 (superscalar):同时译码多个指令;流水线 (pipeline):多个指令流水执行 (流水线宽度、深度);乱序执行 (out-of-order execution):设法改变指令执行顺序。
■ 数据级并行 (Data Level Parallelism, DLP):向量化 (vectorization):单指令多数据 (如:乘加指令)。
● 福林(Flynn)分类。从两个正交的维度:指令流(Intruction Stream)和数据流(Data Stream),其中每个维度有 Single 和 Multiple 两种可能选择。产生SISD,SIMD,MISD,MIMD
■ SISD:一个处理器核、执行标量指令。上一条指令开始执行后,才能开始下一条指令的执行,先开始执行的指令先完成。核内部仍然可能采用超标量等技术实现指令级并行计算。
■ SIMD:一个处理器核包含多个同构的处理单元、执行向量指令。指令被编码成一个线性序列,每条指令表示一组并行的、功能相同的数据处理操作。运行时依次开始每条指令的执行,先开始执行的指令先完成。要求显式描述计算并行性,不支持并发操作的表达。
■ MISD:多颗互相耦合、按顺序编号的处理器核,执行标量指令。各指令具有一致的指令周期。运行时总是同时向各处理器核分别提交一条指令。除第一颗核外,其它核执行的指令都不允许读取程序中的数据,其执行指令操作数来自上一颗处理器核在前一个指令周期所处理的数据或者结果。除最后一颗核外,其它处理器核上执行的指令都不允许更新程序中的数据。要求将一个数据的更新分解成固定数量、连续
执行的操作,显式描述并行操作,使得任何时刻都执行固定数量的操作、并顺序完成各个数据更新操作。
■ MIMD:多颗互相独立的处理器核,执行标量指令。各条指令的指令周期可以相同、也可以不同。运行时每个处理器核独自处理所接受的指令、并确保这些指令的完成顺序与接收顺序一致。程序运行时,可以采用串行方式将各指令依次提交给同一颗处理器核,也可以将执行并行操作的多条指令分别提交给不同的处理器核。在同一颗处理器核上执行的指令构成一个指令流。当一个程序中的指令被组织成多个指令流时,则应在各个指令流中插入相应的同步点,避免同时执行的指令之间发生读/写冲突。因此,MIMD 计算机既可以运行串行程序、也可以运行并行程序,而且在所支持的并行程序中既可以表达计算并行性、也可以表达计算并发性。
● UMA ( Uniform Memory Access) :一致内存访问架构

● ccNUMA (cache-coherent Nonuniform Memory Access) :缓存一致性的非一致内存访问架构
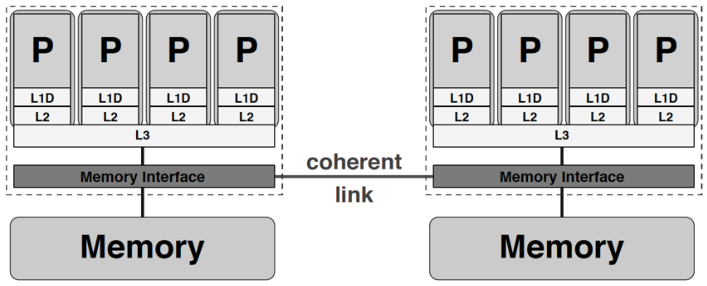
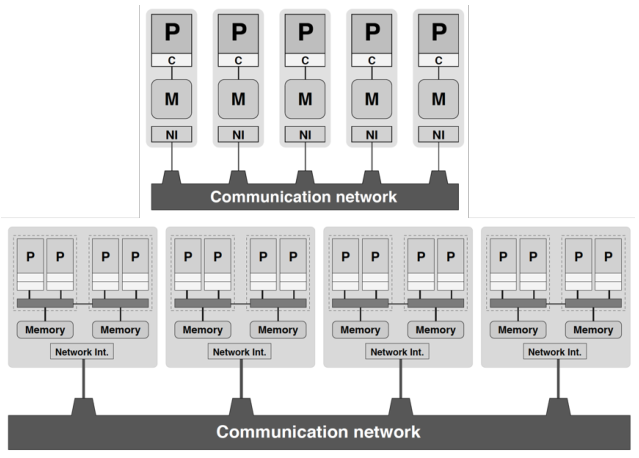
● 集群 (cluster):计算节点 (compute node) 之间通过高速网络互联,计算节点内部可以是任意类型的单核或共享内存架构

▶ 古斯塔夫定律:记 α ∈ [0,1] 是某任务无法并行处理部分所占的比例. 假设该任务的工作量可以随着处理器个数缩放,从而保持处理时间固定. 则对任意 n 个处理器,相比于 1 个处理器,能够取得的加速比 S ′ (n) 不存在上界

▶ 孙-倪定律 (Sun-Ni’s Law):记 α ∈ [0,1] 是某任务无法并行处理部分所占的比例. 假设该任务的可并行部分随着处理器个数 n 按照因子 G(n) 缩放,则对任意 n,相比于 1 个处理器,能够取得的加速比 S ∗ (n) 满足
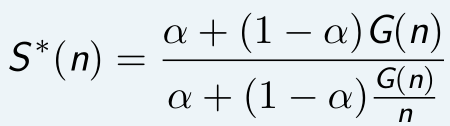

● 孙-倪定律的应用

▶ 影响程序性能的分析模型:Roofline 模型,AMAT 模型,PRAM 模型,α-β 模型,BSP 模型
● Roofline 模型,从计算、访存之间的关系考虑

● AMAT 模型(Average Memory Access Time),从多级存储的角度考虑
■ 单层 AMAT 模型,假设只有一级缓存,预测的平均访存时间为:
AMAT = (1 − r) * T+ r * (T$ + TM ) = T$ + r * TM,T$ 为缓存访问时间(命中时间,Hit time),TM 为内存访问时间(缓存失效损失,Miss penalty),r 为缓存失效率(Miss rate)
■ 多层 AMAT 模型,假设有两级 / 三级缓存,T1,T2,T3 分别为 L1,L2,L3 缓存访问时间,TM 为内存访问时间,r1,r2,r3 分别为 L1,L2,L3 缓存的局部失效率(该层次缓存失效的概率,local miss rate),预测的平均访存时间为:
AMAT2 = T1 + r1 * (T2 + r2 * TM ) = T1 + R1 * T2 + R2 * TM,
AMAT3 = T1 + r1 * [T2 + r2 * (T3 + r3 * TM)] = T1 + R1 * T2 + R2 * T3 + R3 * TM
其中 R1 = r1,R2 = r1 * r2,R3 = r1 * r2 * r3 分别为 L1,L2,L3 缓存的整体失效率 (该层次缓存以及其上层所有缓存同时失效的概率,global miss rate)
● PRAM 模型 (Parallel Random Access Machine Model),从多 (众) 核并行角度考虑
■ RAM (Random Access Machine) 模型在共享内存系统上的扩展:所有处理器共享一个连续的内存空间,每个处理器执行相互独立的指令,处理器执行任意一种计算或访存操作的时间开销都相等,模型参数:处理器个数 p,单位执行时间 τ。
■ 基于不同的处理访存冲突的策略,有四类 PRAM 模型:
Exclusive-read, exclusive-write (EREW) 模型;
Concurrent-read, exclusive-write (CREW) 模型;
Exclusive-read, concurrent-write (ERCW) 模型;
Concurrent-read, concurrent-write (CRCW) 模型
■ 其中,concurrent-write 的处理分为:
Common 所有处理器写的数值完全相同,没有冲突;
Arbitrary 任意一个处理器完成写操作,其他处理器不操作;
Priority 按照某种实现约定的原则确定处理器的优先级,优先级高的处理器写;
Reduction 规约操作,如 SUM,MAX 等。
● PRAM 模型对并行算法进行理论分析的课程:http://pages.cs.wisc.edu/~tvrdik/cs838.html
● PRAM 忽略计算机体系架构的诸多特性,如访存、通信与计算开销的差别,如缓存、同步等机制,仅使用两个参数来估计算法成本,难以预测真实性能。
● 更精细的模型:PHM (Parallel Hierarchical Memory) 模型等。
▶ 网络系统相关的一些基本概念
● 跳 (hop):拓扑网络上一点到另一点的最短距离
● 网络直径 (diameter):拓扑网络上任意两个节点间的最大跳数
● 二分宽度 (bisection width):将拓扑网络平分为二的最小切割数
● 优化目标:给定节点数 n,选取合适的总连线数,最小化直径、最大化二分宽度
▶ α-β 模型,网络通信时间由延迟 α,带宽 /1β,和消息长度 L 决定(忽略拓扑构架)
Tcomm = α + β * L,延迟、带宽分别是影响短消息和长消息通信性能的主要因素,多个短消息不如一个长消息,因为 n * (α + β * L) >> α + β * n * L
▶ BSP 模型 (Bulk Synchronous Parallel)
● 基本假设:每个处理器拥有一个独立的内存空间;所有处理器可以通过一个公共网络采用点对点方式通信;所有处理器可以通过该网络实现同步;程序以超步 (superstep) 为单位并行执行;每个超步末进行栅栏同步,从而保证所有处理器同时进行下一个超步。
● 模型参数:p 处理器个数;S 总超步数;g 单位消息单边通信时间(通信带宽 = 1 / g);ℓ 每次栅栏同步的时间;ws 第 s 超步本地计算的最大时间;hs 第 s 超步单边通信的最大消息量。
TimeBSP = ∑ws + g * ∑hs + ℓ * S
● 本地计算可以与全局通信重叠,甚至进一步与栅栏同步重叠,TimeBSP = ∑max{ws,gh * s } + ℓ * S,或进一步地,TimeBSP = ∑max{ws,gh * s,ℓ}
● 基于 BSP 模型的算法受计算机硬件体系架构的制约较小,容易编程实现,性能预测容易;忽略了通信的延迟,传输 m 个长度为 1 的消息的开销等于传输 1 个长度为 m 的消息
● 更精细的模型:LogP 模型 (Latency / overhead / gap / Proc) 等
分布式计算课程补充笔记 part 1的更多相关文章
- 分布式计算课程补充笔记 part 4
▶ 并行通讯方式: map 映射 全局一到一 全局单元素计算操作 transpose 转置 一到一 单元素位移 gather 收集 多到一 元素搬运不计算 scatter 分散 一到多 元素搬运不计算 ...
- 分布式计算课程补充笔记 part 2
▶ 并行计算八字原则:负载均衡,通信极小 ▶ 并行计算基本形式:主从并行.流水线并行.工作池并行.功能分解.区域分解.递归分治 ▶ MPI 主要理念:进程 (process):无共享存储:显式消息传递 ...
- 分布式计算课程补充笔记 part 3
▶ OpenMP 的任务并行 (task parallelism):显式定义一系列可执行的任务及其相互依赖关系,通过任务调度的方式多线程动态执行,支持任务的延迟执行 (deferred executi ...
- 分布式计算课程补充笔记 part 1.5
▶ 编写 SLURM 脚本 #!/bin/bash #SBATCH -J name # 任务名 #SBATCH -p gpu # 分区名,可为 cpu 或 gpu #SBATCH -N # 节点数 # ...
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- 03、同事分享课程的笔记 —《Android应用低功耗设计》
这是安卓组的同事一个月前分享的一节课程,听课时写了一下笔记,之前是写在本子上的,感觉内容挺不错 的,就保存在博客了吧,方便回看. 他曾经在就职于英特尔公司,是与芯片设计相关的,这课程标题虽然是与安卓相 ...
- Coursera台大机器学习基础课程学习笔记1 -- 机器学习定义及PLA算法
最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一机器学习是什么? 感觉和 Tom M. Mitchell的定义几乎一致, A computer program ...
- 分布式计算框架学习笔记--hadoop工作原理
(hadoop安装方法:http://blog.csdn.net/wangjia55/article/details/53160679这里不再累述) hadoop是针对大数据设计的一个计算架构.如果你 ...
- [基础]斯坦福cs231n课程视频笔记(三) 训练神经网络
目录 training Neural Network Activation function sigmoid ReLU Preprocessing Batch Normalization 权重初始化 ...
随机推荐
- 删除右键菜单中的Git
在打开的注册表中找到:HKEY_CLASSES_ROOT,并点HKEY_CLASSES_ROOT前面的小三角:找到Directory,点击前面的小三角:找到Background,点击前面的小三角:打开 ...
- Python 环境的搭建(转载)
原文来自 http://www.cnblogs.com/windinsky/archive/2012/09/20/2695520.html 1.首先访问http://www.python.org/do ...
- Python关于self用法重点分析
在介绍Python的self用法之前,先来介绍下Python中的类和实例…… 我们知道,面向对象最重要的概念就是类(class)和实例(instance),类是抽象的模板,比如学生这个抽象的事物,可以 ...
- Intellij Idea编译项目下的.java文件时的编码问题
Intellij Idea编译项目下的.java文件时的编码问题 原创 2015年07月22日 21:45:14 10510 由<编译.java文件时的编码问题>可知,在编译.java文件 ...
- django报错总结
问题一: dictionary update sequence element #1 has length 3; 2 is required 解决方法: 检查视图函数的render里传的字典
- spring 如何决定使用jdk动态代理和cglib(转)
Spring1.2: 将事务代理工厂[TransactionProxyFactoryBean] 或 自动代理拦截器[BeanNameAutoProxyCreator] 的 proxyTargetCla ...
- PyCharm的一些设置
设置使用UTF-8 在任何情况下: 设置写python脚本,新建 脚本的时候默认加的头文件. # !/usr/bin/env python# -*- coding:utf-8 -*-# Author: ...
- studio之mac快捷键
2. SouceTree忽略文件: .gitignore文件编辑: 忽略指定文件:直接写文件名 忽略文件夹:直接写文件夹路径,例:target或者target/ -> 忽略target下的所有 ...
- Jmeter(三十二)Jmeter Question 之 “自定义函数开发”
“技术是业务的支撑”,已经不是第一次听到这句话,因为有各种各样的需求,因此衍生了许多各种各样的技术.共勉! 前面有提到提到过Jmeter的安装目录结构,也提到Jmeter的常用函数功能,有部分工作使用 ...
- 00004 - CentOS 7下安装pptp服务端
主要配置步骤 1. 安装前检查系统支持 a. 在安装之前查看系统是否支持PPTP modprobe ppp-compress-18 && echo success 应该输出:succe ...