第二十八天- tcp下的粘包和解决方案
1.什么是粘包
写在前面:只有TCP有粘包现象,UDP永远不会粘包
1.TCP下的粘包
因为TCP协议是面向连接、面向流的,收发两端(客户端和服务器端)都要有成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包,这就导致了数据量小的粘包现象;同时因为tcp的协议的安全可靠性,在没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会导致数据量大的粘包;

2.UDP没粘包原因:
UDP是无连接的,面向消息的,为提供高效率服务 ,并不会使用块的合并优化算法;同时由于UDP支持一对多的模式,所以接收端缓冲区采用了链式结构来记录每一个到达的UDP包,也就是在每个UDP包中有头(消息来源地址,端口等信息),这样,对于接收端来说就是有边界的,所以UDP永远没粘包。
2.两种粘包情况
1.情况一 发送方的缓存机制
发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,优化机制会合到一起,产生粘包)
# 连续传小包被优化机制合并导致的粘包 import socket server = socket.socket()
ip_port = ('127.0.0.1',8081)
server.bind(ip_port)
server.listen()
conn,addr = server.accept() from_client_msg1 = conn.recv(1024).decode('utf-8')
from_client_msg2 = conn.recv(1024).decode('utf-8') print(from_client_msg1)
print(from_client_msg2)
# heheheenenen 两条消息被优化合并在了一块 conn.close()
server.close()
View 小数据粘包_server Code
import socket client = socket.socket()
ip_port = ('127.0.0.1',8081)
client.connect(ip_port) To_server_msg1 = client.send(b'hehehe')
To_server_msg2 = client.send(b'enenen') client.close()
View 小数据粘包_client Code
2.情况二 接收方的缓存机制
接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
# 传输数据超出接收范围导致的粘包
import socket
import subprocess server = socket.socket()
ip_port = ('127.0.0.1',8001)
server.bind(ip_port)
server.listen()
conn,addr = server.accept() while 1:
from_client_cmd = conn.recv(1024).decode('utf-8') sub_obj = subprocess.Popen(
from_client_cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
cmd_res = sub_obj.stdout.read()
print('结果长度>>>', len(cmd_res))
conn.send(cmd_res) # 发内容给客户端
数据大粘包_server
import socket client = socket.socket()
ip_port = ('127.0.0.1',8001)
client.connect(ip_port) while 1:
client_cmd = input('请输入系统指令>>>')
client.send(client_cmd.encode('utf-8')) from_server_msg = client.recv(1024) # 接收返回的消息 print(from_server_msg.decode('gbk'))
# 可以看到没一次性接收完毕,执行下条命令出现了上次的结果,这就是数据大超出接收范围的粘包。
数据大粘包_client
3.总结
黏包现象只发生在tcp协议中:
1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点。
2.实际上,主要还是因为接收方不知道消息间的界限,不知道一次性提取多少字节的数据所造成。
3.粘包解决方案
1.解决方案一:
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据。

import socket
import subprocess server = socket.socket()
ip_port = ('127.0.0.1',8001)
server.bind(ip_port)
server.listen()
conn,addr = server.accept() while 1:
from_client_cmd = conn.recv(1024).decode('utf-8') # 接收传来的命令
sub_obj = subprocess.Popen(
from_client_cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
# subprocess对象.read 得到命令结果,是bytes类型的
str_byt = sub_obj.stdout.read()
str_len = len(str_byt)
print(str_len)
conn.send(str(str_len).encode('utf-8')) # 先发长度 from_client_msg = conn.recv(1024).decode('utf-8')
if from_client_msg == 'ok':
conn.send(str_byt) # 客户端确认收到长度后 再发送真实内容
else:
print("客户端未收到长度!")
break conn.close()
server.close()
解决小包粘包_服务端
import socket client = socket.socket()
ip_port = ('127.0.0.1',8001)
client.connect(ip_port) while 1:
client_cmd = input('请输入系统指令>>>')
client.send(client_cmd.encode('utf-8')) from_server_len = client.recv(1024).decode('utf-8') # 接收返回的长度
print(from_server_len)
client.send(b'ok') from_server_msg = client.recv(int(from_server_len)) # 注意还原成int
print(from_server_msg.decode('gbk'))
解决小包粘包_客户端
不足之处:程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗
2.解决方案进阶:
可借助struct模块,这个模块可把要发的数据长度转成固定长度字节。这样客户端每次接收消息前只要先收到这个固定长度字节的内容,收到接下来要接收的信息大小,那么最终接受的数据只要达到这个值就停止,就能完整接收的数据了。
struct模块:该模块可以把一个类型,如数字,转成固定长度的bytes
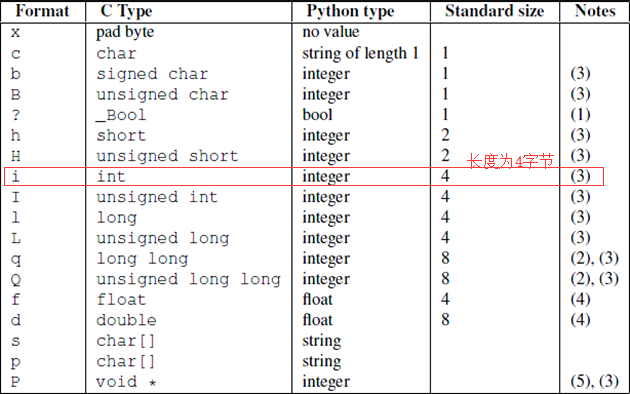
import struct
res = struct.pack('i',1111111) # i 模式 1111111 要转换的内容
print(res) # b'G\xf4\x10\x00'
模式,见下图:
import socket
import struct
import subprocess server = socket.socket()
ip_port = ('127.0.0.1',8001)
server.bind(ip_port)
server.listen()
conn,addr = server.accept() while 1:
from_client_cmd = conn.recv(1024).decode("utf-8") # 注意转码
# print(from_client_cmd)
sub_obj = subprocess.Popen(
from_client_cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
cmd_res = sub_obj.stdout.read() # 得到bytes类型所有内容
str_len = len(cmd_res)
print(str_len) str_len1 = struct.pack('i',str_len) # 把长度打包成4字节的bytes conn.send(str_len1 + cmd_res) # 拼接字节 把长度和内容打包发给客户端
struct方案解决粘包_server
import socket, struct client = socket.socket()
ip_port = ('127.0.0.1',8001)
client.connect(ip_port) while 1:
str_cmd = input('请输入命令>>> ').encode('utf-8')
client.send(str_cmd)
# 先接收4个字节,4个字节是数据的真实长度转换而成的
str_len = client.recv(4)
# print(str_len)
num = struct.unpack('i',str_len)[0] # 注意解出来是一个元组 用下标把真实长度取出来 print(num) str_res = client.recv(num)
print(str_res.decode('gbk'))
struct方案解决粘包_client
补充:获取缓冲区大小
# 获取socket缓冲区大小
import socket
from socket import SOL_SOCKET,SO_REUSEADDR,SO_SNDBUF,SO_RCVBUF
sk = socket.socket(type=socket.SOCK_DGRAM)
# sk.setsockopt(SOL_SOCKET,SO_RCVBUF,80*1024)
sk.bind(('127.0.0.1',8090))
print('>>>>', (sk.getsockopt(SOL_SOCKET, SO_SNDBUF))/1024)
print('>>>>', sk.getsockopt(SOL_SOCKET, SO_RCVBUF))
第二十八天- tcp下的粘包和解决方案的更多相关文章
- 深入了解Netty【八】TCP拆包、粘包和解决方案
1.TCP协议传输过程 TCP协议是面向流的协议,是流式的,没有业务上的分段,只会根据当前套接字缓冲区的情况进行拆包或者粘包: 发送端的字节流都会先传入缓冲区,再通过网络传入到接收端的缓冲区中,最终由 ...
- python中TCP粘包问题解决方案
TCP协议中的粘包问题 1.粘包现象 基于TCP写一个远程cmd功能 #服务端 import socket import subprocess sever = socket.socket() seve ...
- 基于tcp协议的粘包问题(subprocess、struct)
要点: 报头 固定长度bytes类型 1.粘包现象 粘包就是在获取数据时,出现数据的内容不是本应该接收的数据,如:对方第一次发送hello,第二次发送world,我放接收时,应该收两次,一次是hel ...
- 网络编程之tcp协议以及粘包问题
网络编程tcp协议与socket以及单例的补充 一.单例补充 实现单列的几种方式 #方式一:classmethod # class Singleton: # # __instance = None # ...
- TCP通讯处理粘包详解
TCP通讯处理粘包详解 一般所谓的TCP粘包是在一次接收数据不能完全地体现一个完整的消息数据.TCP通讯为何存在粘包呢?主要原因是TCP是以流的方式来处理数据,再加上网络上MTU的往往小于在应用处理的 ...
- Netty(三) 什么是 TCP 拆、粘包?如何解决?
前言 记得前段时间我们生产上的一个网关出现了故障. 这个网关逻辑非常简单,就是接收客户端的请求然后解析报文最后发送短信. 但这个请求并不是常见的 HTTP ,而是利用 Netty 自定义的协议. 有个 ...
- 什么是 TCP 拆、粘包?如何解决(Netty)
前言 记得前段时间我们生产上的一个网关出现了故障. 这个网关逻辑非常简单,就是接收客户端的请求然后解析报文最后发送短信. 但这个请求并不是常见的 HTTP ,而是利用 Netty 自定义的协议. 有个 ...
- 【Python】TCP Socket的粘包和分包的处理
Reference: http://blog.csdn.net/yannanxiu/article/details/52096465 概述 在进行TCP Socket开发时,都需要处理数据包粘包和分包 ...
- Netty系列(四)TCP拆包和粘包
Netty系列(四)TCP拆包和粘包 一.拆包和粘包问题 (1) 一个小的Socket Buffer问题 在基于流的传输里比如 TCP/IP,接收到的数据会先被存储到一个 socket 接收缓冲里.不 ...
随机推荐
- 设计模式《JAVA与模式》之解释器模式
在阎宏博士的<JAVA与模式>一书中开头是这样描述解释器(Interpreter)模式的: 解释器模式是类的行为模式.给定一个语言之后,解释器模式可以定义出其文法的一种表示,并同时提供一个 ...
- Java Web(四) 一次性验证码的代码实现
其实实现代码的逻辑非常简单,真的超级超级简单. 1.在登录页面上login.jsp将验证码图片使用标签<img src="xxx">将绘制验证码图片的url给它 2.在 ...
- EXECUTE 后的事务计数指示缺少了 COMMIT 或 ROLLBACK TRANSACTION 语句。上一计数 = 1,当前计数 = 2
理解这一句话: 一个begin tran会增加一个事务计数器,要有相同数量的commit与之对应,而rollback可以回滚全部计数器 这个错误一般是出现在嵌套事务中. 测试环境 sql 2008 例 ...
- gulp的安装以及使用详解,除了详细还是详细
安装gulp: 1. 创建本地包管理环境: 使用npm init命令在本地生成一个package.json文件,package.json是用来记录你当前这个项目依赖了哪些包,以后别人拿到你这个项目后, ...
- 安装SVN并进行汉化的详细步骤
安装SVN并进行汉化的详细步骤 SAE提供了不同的代码部署方式,可以分为两类:一是通过SVN客户端部署,这是SAE推荐的代码部署方法.另一个是通过非SVN客户端部署,即在线代码在线编辑器和推荐应用安装 ...
- 启动HDFS之后一直处于安全模式org.apache.hadoop.hdfs.server.namenode.SafeModeException: Log not rolled. Name node is in safe mode.
一.现象 三台机器 crxy99,crxy98,crxy97(crxy99是NameNode+DataNode,crxy98和crxy97是DataNode) 按正常命令启动HDFS之后,HDFS一直 ...
- Chapter 3 Phenomenon——23
Charlie put one arm behind my back, not quite touching me, and led me to the glass doors of the exit ...
- 装饰者模式——Java设计模式
装饰模式 1.概念 动态地为对象附加上额外的职责 其目的是包装一个对象,从而可以在运行时动态添加新的职责.每个装饰器都可以包装另一个装饰器,这样理论上来说可以对目标对象进行无限次的装饰. 2.装饰器类 ...
- 21-hadoop-weibo推送广告
1, tf-idf 计算每个人的词条中的重要度 需要3个mapreduce 的 job执行, 第一个计算 TF 和 n, 第二个计算 DF, 第三个代入公式计算结果值 1, 第一个job packag ...
- 合并两个数组并去重(ES5和ES6两种方式实现)
合并两个数组并去重(ES5和ES6两种方式实现) ES6实现方式 let arr1 = [1, 1, 2, 3, 6, 9, 5, 5, 4] let arr2 = [1, 2, 5, 4, 9, 7 ...