高并发之 - 全局有序唯一id Snowflake 应用实战
前言
本篇主要介绍高并发算法Snowflake是怎么应用到实战项目中的。
对于怎么理解Snowflake算法,大家可以从网上搜索‘Snowflake’,大量资源可供查看,这里就不一一详诉,这里主要介绍怎么实战应用。
对于不理解的,可以看看这篇文章 Twitter-Snowflake,64位自增ID算法详解
为什么有Snowflake算法的出现呢?
首先它是Twitter提出来的。
前世今生
以前我们可以用UUID作为唯一标识,但是UUID是无序的,又是英文、数字、横杆的结合。当我们要生成有序的id并且按时间排序时,UUID必然不是最好的选择。
当我们需要有序的id时,可以用数据库的自增长id,但是在当今高并发系统时代下,自增长id速度太慢,满足不了需求。然而,对于有‘有序的id按时间排序’这一需求时,Twitter提出了它的算法,并且用于Twitter中。
需要注意的地方
可达并发量根据不同的配置不同,每秒上万并发量不成问题。
id可用时间:69年
使用限制
使用Snowflake其实有个限制,就是必须知道运行中是哪台机器。比如我们用Azure云,配置了10个实例(机器),要知道这10个机器是哪一台。
开始用Snowflake
首先,直接贴Snowflake算法代码,算法怎么实现就不具体说:(C#版,java版的代码也一样实现)
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks; namespace ConsoleApp6
{
/// <summary>
/// From: https://github.com/twitter/snowflake
/// An object that generates IDs.
/// This is broken into a separate class in case
/// we ever want to support multiple worker threads
/// per process
/// </summary>
public class IdWorker
{
private long workerId;
private long datacenterId;
private long sequence = 0L; private static long twepoch = 1288834974657L; /// <summary>
/// 机器标识位数
/// </summary>
private static long workerIdBits = 5L; /// <summary>
/// //数据中心标识位数
/// </summary>
private static long datacenterIdBits = 5L; /// <summary>
/// //机器ID最大值
/// </summary>
private static long maxWorkerId = -1L ^ (-1L << (int)workerIdBits); /// <summary>
/// //数据中心ID最大值
/// </summary>
private static long maxDatacenterId = -1L ^ (-1L << (int)datacenterIdBits); /// <summary>
/// //毫秒内自增位
/// </summary>
private static long sequenceBits = 12L; /// <summary>
/// //机器ID偏左移12位
/// </summary>
private long workerIdShift = sequenceBits; /// <summary>
/// //数据中心ID左移17位
/// </summary>
private long datacenterIdShift = sequenceBits + workerIdBits; /// <summary>
/// //时间毫秒左移22位
/// </summary>
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << (int)sequenceBits); private long lastTimestamp = -1L; private static object syncRoot = new object(); /// <summary>
///
/// </summary>
/// <param name="workerId">机器id,哪台机器。最大31</param>
/// <param name="datacenterId">数据中心id,哪个数据库,最大31</param>
public IdWorker(long workerId, long datacenterId)
{ // sanity check for workerId
if (workerId > maxWorkerId || workerId < )
{
throw new ArgumentException(string.Format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < )
{
throw new ArgumentException(string.Format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
} public long nextId()
{
lock (syncRoot)
{
long timestamp = timeGen(); if (timestamp < lastTimestamp)
{
throw new ApplicationException(string.Format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
} if (lastTimestamp == timestamp)
{
sequence = (sequence + ) & sequenceMask;
if (sequence == )
{
timestamp = tilNextMillis(lastTimestamp);
}
}
else
{
sequence = 0L;
} lastTimestamp = timestamp; return ((timestamp - twepoch) << (int)timestampLeftShift) | (datacenterId << (int)datacenterIdShift) | (workerId << (int)workerIdShift) | sequence;
}
} protected long tilNextMillis(long lastTimestamp)
{
long timestamp = timeGen();
while (timestamp <= lastTimestamp)
{
timestamp = timeGen();
}
return timestamp;
} protected long timeGen()
{
return (long)(DateTime.UtcNow - new DateTime(, , , , , , DateTimeKind.Utc)).TotalMilliseconds;
}
}
}
怎么用呢?
直接用
IdWorker idWorker = new IdWorker(, );
long id = idWorker.nextId();
说明
workerId是机器id,表示分布式环境下的那台机器。datacenterId是数据库中心,表示哪个数据库中心。这里的机器id与数据库中心id最大是31。
我们看到nextId方法里面是用锁来生成id的。
然而我们怎么真正地应用到我们实际的项目中呢?
Snowflake运用到项目中
例如,我们分布式有三台机器,1个数据库。
那么workerId分别在机器A/B/C中的值为1/2/3,datacenterId都为0。
这个配置好了之后,那么我们怎么在代码里面编写呢?
比如,对于一个web应用,我们都知道,在客户端请求时,服务器都会生成一个Controller,那么怎么保证IdWorker实例只能在一台服务器中存在一个呢?
答案大家都知道,是静态属性(当然也可以单例)。下面我们用控制台程序来模仿一下controller的请求,当10个线程请求时会发生什么情况。
模仿的Controller如下:
class TestIdWorkerController
{
private static readonly IdWorker _idWorker = new IdWorker(, ); public void GenerateId(HashSet<long> set)
{ int i = ;
while (true)
{
if (i++ == )
break; long id = _idWorker.nextId();
lock (set)
{
if (!set.Add(id))
Console.WriteLine($"same id={id}");
} }
} }
我们看到,id会生成1000000个,并且如果有相同的时候打印出来相同的id。(这里为什么用锁来锁住HashSet,因为HashSet线程不是安全的,所以要用锁)
下面我在主程序中,开启10个线程,分别来new一次TestIdWorkerController,new一次Thread。
static void Main(string[] args)
{ //存放id的集合
HashSet<long> set = new HashSet<long>(); //启动10个线程
for (int i = ; i < ; i++)
{
TestIdWorkerController testIdWorker = new TestIdWorkerController();
Thread thread = new Thread(() => testIdWorker.GenerateId(set));
thread.Start();
} //每秒钟打印当前生成的状态
while (true)
{
Console.WriteLine($"set.count={set.Count}");
Thread.Sleep( * );
} }
我们看到,每秒打印输出的集合,如何输出的集合数量=1000000(id数)*10(线程数),也侧面验证了没有重复。
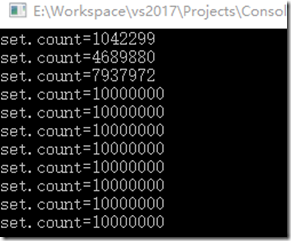
从上图看出,执行完毕,并且没打印same,结果也为1000000(id数)*10(线程数)。所以尽情的所用吧。
可以关注本人的公众号,多年经验的原创文章共享给大家。

高并发之 - 全局有序唯一id Snowflake 应用实战的更多相关文章
- 高并发分布式系统如何做到唯一Id
又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文,后续再奉上.最近还写了一个发邮件的组件以及性能测试请看 <NET开发邮件发送功能的全面教程(含邮件组件源码)> ,还弄了 ...
- PHP uniqid 高并发生成不重复唯一ID
http://www.51-n.com/t-4264-1-1.html PHP uniqid()函数可用于生成不重复的唯一标识符,该函数基于微秒级当前时间戳.在高并发或者间隔时长极短(如循环代码)的情 ...
- 游戏服务器生成全局唯一ID的几种方法
在服务器系统开发时,为了适应数据大并发的请求,我们往往需要对数据进行异步存储,特别是在做分布式系统时,这个时候就不能等待插入数据库返回了取自动id了,而是需要在插入数据库之前生成一个全局的唯一id,使 ...
- 根据twitter的snowflake算法生成唯一ID
C#版本 /// <summary> /// 根据twitter的snowflake算法生成唯一ID /// snowflake算法 64 位 /// 0---0000000000 000 ...
- C# 根据twitter的snowflake算法生成唯一ID
C# 版算法: using System; using System.Collections.Generic; using System.Linq; using System.Text; using ...
- 分布式系统的唯一id生成算法你了解吗?
在分库分表之后你必然要面对的一个问题,就是id咋生成? 因为要是一个表分成多个表之后,每个表的id都是从1开始累加自增长,那肯定不对啊. 举个例子,你的订单表拆分为了1024张订单表,每个表的id都从 ...
- 高并发分布式系统中生成全局唯一Id汇总
数据在分片时,典型的是分库分表,就有一个全局ID生成的问题.单纯的生成全局ID并不是什么难题,但是生成的ID通常要满足分片的一些要求: 1 不能有单点故障. 2 以时间为序,或者ID里包含时间 ...
- 如何在高并发分布式系统中生成全局唯一Id
月整理出来,有兴趣的园友可以关注下我的博客. 分享原由,最近公司用到,并且在找最合适的方案,希望大家多参与讨论和提出新方案.我和我的小伙伴们也讨论了这个主题,我受益匪浅啊…… 博文示例: 1. ...
- 高并发分布式环境中获取全局唯一ID[分布式数据库全局唯一主键生成]
需求说明 在过去单机系统中,生成唯一ID比较简单,可以使用MySQL的自增主键或者Oracle中的sequence, 在现在的大型高并发分布式系统中,以上策略就会有问题了,因为不同的数据库会部署到不同 ...
随机推荐
- Android-Java-类与对象的关系
类class 例如:class Student {},很多人把class Student {}称为对象或实体,其实这样并不合理,应该称为描述实体/描述对象: 因为被称为对象或实体的是,new Stud ...
- 提示 make: 没有什么可以做的为 `all'
提示 make: 没有什么可以做的为 `all'. make clean 一次,编译过程又有了.
- VS的一些实用快捷键及小技巧(不断更新)
在未选中文本的情况下: ctrl+x 剪贴并删除当前的行,可以用于快速删除整行代码 ctrl+c 复制当前行的代码 ctrl+l 删除当前行 组合键,需要按两次: ctrl+k,ctrl+c 注释当前 ...
- SignalR2结合ujtopo实现拓扑图动态变化
上一篇文章基于jTopo的拓扑图设计工具库ujtopo,介绍了拓扑设计工具,这一篇我们使用SignalR2结合ujtopo实现拓扑图的动态变化. 仅仅作为演示,之前的文章SignalR2简易数据看板演 ...
- vs2017使用rdlc实现批量打印
接着上一篇:上一篇写了安装,这篇直接搞定批量打印,A4纸横版竖版页面设计,正式开始.(我的表达不怎么好,我尽量发图片都是程序员一点就通) 一.界面展示 忽略界面设计丑 查看预览界面,因为有数据就不截全 ...
- 【转】ABP使用Mysql数据库
原文地址:https://www.cnblogs.com/LonelyCode/p/6477065.html 1.先安装Mysql的包,EntityFramework和Web项目都需要安装 2.修改W ...
- Linux 安装JavaEE环境之Tomcat安装笔记
1.先用xftp将tomcat的压缩包上传到 /opt/ 2.在/usr/local/下使用命令mkdir tomcat 创建tomcat目录 将apache-tomcat-7.0.70.tar.gz ...
- sudoer命令各参数含义及设置
对于普通用户sudo加权的时限制可以执行的命令 https://segmentfault.com/a/1190000007394449 需要修改/etc/sudoers 1. 字段说明如下 授权用户/ ...
- Tools - 文本编辑器Notepad++
00 - NotePad++ 官网 01 - Notepad++修改主题 依次点击设置---语言格式设置---选择主题,在显示界面中修改相关设置(背景色.前景色.字体等). 02 - Notepad+ ...
- CSS选择器之兄弟选择器(~和+)
今天在改以以前人家写的网页的样式的时候,碰到这个选择器,‘~’,当时我是懵逼的,傻傻分不清 ‘+’ 跟 ‘~’的区别,虽然我知道他们都是兄弟选择器. 后来网上查了下,也许是我查找的方式不对,没有找到我 ...