INDEX--从数据存放的角度看索引2
在上次<INDEX--从数据存放的角度看索引>中,我们说到"唯一非聚集索引"和“非唯一非聚集索引”在存储上有一个明显的差别:唯一非聚集索引的非叶子节点上不会包含RID的数据,让我们继续来深挖一下。
准备测试数据:
CREATE TABLE TB1
(
C1 INT,
C2 INT,
C3 INT
)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_C1 ON TB1(C1)
GO
CREATE UNIQUE INDEX IDX_C2 ON TB1(C2)
GO
CREATE INDEX IDX_C3 ON TB1(C3)
GO
INSERT INTO TB1(C1,C2,C3)VALUES(1,1,1)
GO
INSERT INTO TB1(C1,C2,C3)VALUES(2,2,2)
GO
INSERT INTO TB1(C1,C2,C3)VALUES(3,3,3)
索引编号如下: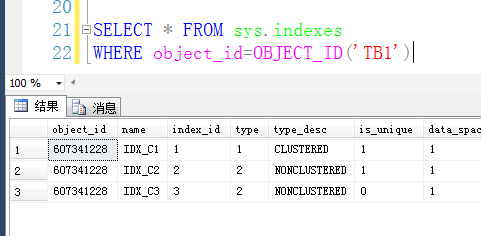
再通过DBCC IND和DBCC PAGE来查看页情况
唯一非聚集索引IDX_C2的数据页:
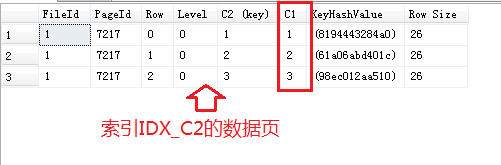
非唯一非聚集索引IDX_C3的数据页:

以上两张图有个明显的区别是C1和C1(key),难道在“非唯一非聚集索引”中,“聚集索引键”也被放到“非聚集索引键”中并且参与排序啦?
相信很多DBA的朋友都遇到这样的问题,要按照某些状态值来查找数据,而这些状态值是一个很小的集合(数量很小),如查找状态值为1的最大订单号
SELECT TOP(1)*
FROM dbo.Orders
WHERE OrderState=1
ORDER BY OrderID DESC
虽然OrderID为主键和唯一聚集索引,但按照OrderID来查找,可能需要进行大范围CLUSTERED INDEX SEEK才能找到满足条件OrderState=1的数据,因此尽管OrderState的可选择性较低,我们还是会对其建立索引,那么问题来了?我们索引该建成什么样呢?
是建成:
CREATE INDEX IDX_OrderState
ON dbo.Orders
(
OrderState
)
还是建成:
CREATE INDEX IDX_OrderState
ON dbo.Orders
(
OrderState,
OrderID
)
曾经我想当然地认为必须建成第二种方式,因为还需要对OrderID进行排序取TOP(1),但经过测试,神奇地发现两种方式的效率一样,无论“非唯一非聚集索引键”里有没有包含“聚集索引键”,都会对“非唯一非聚集索引键”+“聚集索引键”进行排序。
思考这样一个问题,假设对“非唯一非聚集索引键”,仅仅对其定义的键进行排序,如OrderState,而满足OrderState=0的可能有1亿数据,在进行数据更新的时候,首先更新聚集索引,并依次更新非聚集索引,更新索引数据首先要定位数据行才能更新,因此需要扫描这1亿数据才能找到目标行,显然这是不可接受的设计。
对于"唯一非聚集索引"来说,因为可以通过索引键便可以快速定位到索引数据行,且每个键值只会存在一行,因此失去了对“聚集索引键”进行排序的意义。
BTW, 也可以通过观察相同键值下行位置(slotid)和插入顺序来发现数据按照聚集索引键排序。
--===========================================================================
总结:
1. 对于“非唯一非聚集索引”,索引数据实际上是按照“非唯一非聚集索引键”+“聚集索引键”进行排序后存放的;
2. 对于“唯一非聚集索引”,索引数据实际上是按照“唯一非聚集索引键”进行排序后存放的;
3. 所有非聚集索引的叶子节点上都会存放RID的数据,但唯一非聚集索引的非叶子节点上不会包含RID的数据;
--===========================================================================
好好读书。。。

INDEX--从数据存放的角度看索引2的更多相关文章
- INDEX--从数据存放的角度看索引
测试表结构: CREATE TABLE TB1 ( ID ,), C1 INT, C2 INT ) 1. 聚集索引(Clustered index) 聚集索引可以理解为一个包含表中除索引键外多有剩余列 ...
- 深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用
深度挖坑:从数据角度看人脸识别中Feature Normalization,Weight Normalization以及Triplet的作用 周翼南 北京大学 工学硕士 373 人赞同了该文章 基于深 ...
- 对博弈活动中蕴含的信息论原理的讨论,以及从熵角度看不同词素抽象方式在WEBSHELL文本检测中的效果区别
1. 从赛马说起 0x1:赛马问题场景介绍 假设在一场赛马中有m匹马参赛,令第i匹参赛马获胜的概率为pi,如果第i匹马获胜,那么机会收益为oi比1,即在第i匹马上每投资一美元,如果赢了,会得到oi美元 ...
- MySQL在创建数据表的时候创建索引
转载:http://www.baike369.com/content/?id=5478 MySQL在创建数据表的时候创建索引 在MySQL中创建表的时候,可以直接创建索引.基本的语法格式如下: CRE ...
- 从互联网进化的角度看AI+时代的巨头竞争
今天几乎所有的互联网公司在谈论和布局人工智能,收购相关企业.人工智能和AI+成为当今科技领域最灸手可热的名词,关于什么是AI+,其概念就是用以表达将"人工智能"作为当前行业科技化发 ...
- android的程序运行数据存放在哪里?
Android应用开发中,给我们提供了5种数据的存储方式1 使用SharedPreferences存储数据2 文件存储数据3 SQLite数据库存储数据4 使用ContentProvider存储数据5 ...
- Android IOS WebRTC 音视频开发总结(四八)-- 从商业和技术的角度看视频行业的机会
本文主要从不同角度介绍视频行业的机会,文章来自博客园RTC.Blacker,支持原创,转载必须说明出处,欢迎关注个人微信公众号blacker ----------------------------- ...
- 【阿里云产品公测】以开发者角度看ACE服务『ACE应用构建指南』
作者:阿里云用户mr_wid ,z)NKt# @I6A9do 如果感觉该评测对您有所帮助, 欢迎投票给本文: UO<claV RsfTUb)< 投票标题: 28.[阿里云 ...
- [置顶] 从引爆点的角度看360随身wifi的发展
从引爆点的角度看360随身wifi的发展 不到一个月的时间,随身wifi预定量就数百万.它的引爆点在哪里,为什么相同的产品这么多它却能火起来,通过对随身wifi的了解和我知识层面分析,主要是因为随身w ...
随机推荐
- 解决CentOS7-python-pip安装失败
Pip介绍 pip 是一个安装和管理 Python 包的工具,python安装包的工具有easy_install, setuptools, pip,distribute.使用这些工具都能下载并安装dj ...
- com_pc-mcu
#include <REG52.H> unsigned char UART_buff; bit New_rec = , Send_ed = , Money = ; void main (v ...
- javase高级技术 - 泛型
在写案例之前,先简单回顾下泛型的知识 我们知道,java属于强变量语言,使用变量之前要定义,并且定义一个变量时必须要指明它的数据类型,什么样的数据类型赋给什么样的值. 所谓“泛型”,就是“宽泛的数据类 ...
- 数组方法indexOf & lastIndexOf
indexOf() 语法:arrayObject.indexOf(searchvalue, startIndex) 功能:从数组的开头(位置0)开始向后查找. 参数:searchvalue:必需,要查 ...
- git版本控制工具的使用(3)
git remote查看远程库的信息get remote -v可以更详细,查看推送和抓取权限 git push origin master把本地的master提交到远程的库对应的主分支 gt push ...
- liunx基础命令
linux的简单介绍 linux是一款免费使用和自由传播的内似于unix的操作系统软件,是一个基于POSI和unix的多用户,多任务,支持多线程和多CPU的一种操作系统.主要用于服务器,特别是网络服务 ...
- mysql之索引查询1
一 备份数据 备份库: mysqldump:拷贝数据 --database:数据库 基本语法是:mysqldump -h服务器名 -u用户名 -p密码 --database 库名 > 备份路径. ...
- RAID : 独立磁盘冗余阵列(Redundant Array of Independent Disks)
RAID 分为不用的等级(RAID0 - RAID5),以满足不同的数据应用需求. RAID 是由多个独立的高性能磁盘驱动器组成的磁盘子系统,从而提供比单个磁盘更高的存储性能和数据冗余的技术. AID ...
- PHP标准库 SPL
PHP SPL笔记 这几天,我在学习PHP语言中的SPL. 这个东西应该属于PHP中的高级内容,看上去很复杂,但是非常有用,所以我做了长篇笔记.不然记不住,以后要用的时候,还是要从头学起. 由于这是供 ...
- lambda表达式(c++11)
1.概念 1)lambda表达式是一个可调用的代码单元,它由一个捕获列表.一个参数列表.一个箭头.一个返回类型.一个函数体组成: 2)可以忽略参数列表和返回类型,但必须包含捕获列表和函数体: 3)忽略 ...