dotNetSpider 手记
准备工作:
从github上download工程。
安装VS2017。
安装 .net core 2.0。
编译通过。
基础架构:
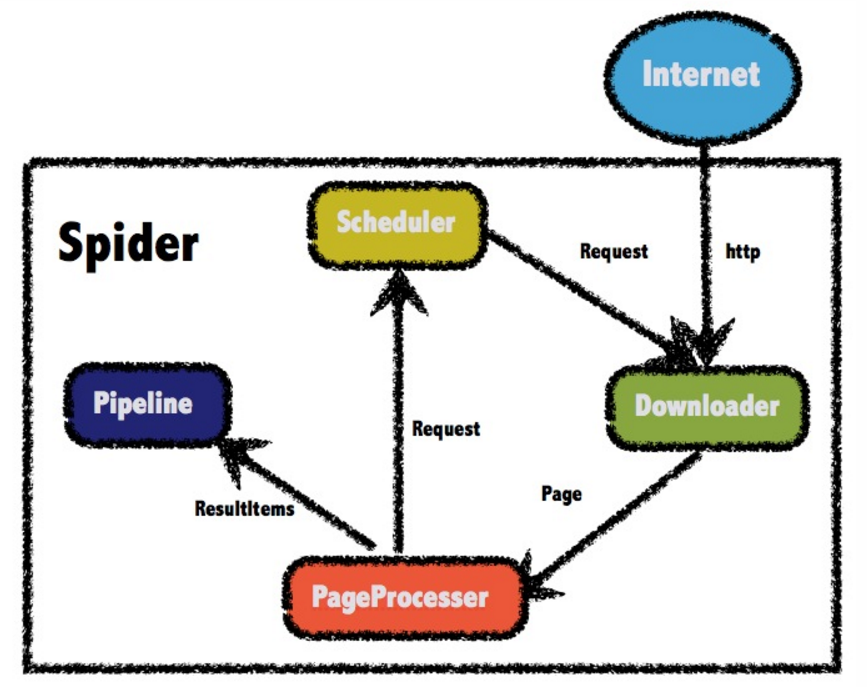
调度器 Scheduler 从根site开始,向 Downloader 分配请求任务。
Downloader 根据分配到的请求任务,向目标site 下载 page,并交由 PageProcessor 进行页面处理。
PageProcessor 将处理的结果推入 Pipeline,将解析出的新的链接,推入 Scheduler。
循环直至 Scheduler 没有新的请求可以处理。
Spider.Create:
设定根访问节点、唯一身份标识、请求调度器 Scheduler,页面处理器 PageProcessor。
以给出的 Sample 样例中,遍历 cnblog 站点为例进行解析:
Scheduler 是 QueueDuplicateRemovedScheduler。就是一个存放 Request 的队列。
PageProcessor 是默认的 DefaultPageProcessor。
这里涉及到 XPath 的知识,需要快速了解。
XPath:XPath 使用路径表达式在 XML 文档中进行导航,选取 XML 文档中的节点或者节点集。
主要知识点见:http://www.runoob.com/xpath/xpath-syntax.html
页面处理流程 BasePageProcessor.Process:

public void Process(Page page)
{
bool isTarget = true; if (_targetUrlPatterns.Count > 0 && !_targetUrlPatterns.Contains(null))
{
foreach (var regex in _targetUrlPatterns)
{
isTarget = regex.IsMatch(page.Url);
if (isTarget)
{
break;
}
}
} if (!isTarget)
{
return;
} Handle(page); page.ResultItems.IsSkip = page.ResultItems.Results.Count == 0; if (!page.SkipExtractTargetUrls)
{
ExtractUrls(page);
}
}
在 Sample 中,调用的是 DefaultPageProcessor 提供的 hanlde:
page.AddResultItem("title", page.Selectable.XPath("//title").GetValue());
page.AddResultItem("html", page.Content);
默认的页面处理,是找出 “title” 元素,以及整个 html 内容。
接着在下载好的页面内容中,查找更多的 url。
dotNetSpider 手记的更多相关文章
- Linux.NET实战手记—自己动手改泥鳅(上)
各位读者大家好,不知各位读者有否阅读在下的前一个系列<Linux.NET 学习手记>,在前一个系列中,我们从Linux中Mono的编译安装开始,到Jexus服务器的介绍,以及如何在Linu ...
- Linux.NET学习手记(7)
前一篇中,我们简单的讲述了下如何在Linux.NET中部署第一个ASP.NET MVC 5.0的程序.而目前微软已经提出OWIN并致力于发展VNext,接下来系列中,我们将会向OWIN方向转战. 早在 ...
- Linux.NET学习手记(8)
上一回合中,我们讲解了Linux.NET面对OWIN需要做出的准备,以及介绍了如何将两个支持OWIN协议的框架:SignalR以及NancyFX以OwinHost的方式部署到Linux.NET当中.这 ...
- 关于《Linux.NET学习手记(8)》的补充说明
早前的一两天<Linux.NET学习手记(8)>发布了,这一篇主要是讲述OWIN框架与OwinHost之间如何根据OWIN协议进行通信构成一套完整的系统.文中我们还直接学习如何直接操作OW ...
- U3D DrawCall优化手记
在最近,使用U3D开发的游戏核心部分功能即将完成,中间由于各种历史原因,导致项目存在比较大的问题,这些问题在最后,恐怕只能通过一次彻底的重构来解决 现在的游戏跑起来会有接近130-170个左右的Dra ...
- 信息系统实践手记5-CACHE设计一例
说明:信息系统实践手记系列是系笔者在平时研发中先后遇到的大小的问题,也许朴实和细微,但往往却是经常遇到的问题.笔者对其中比较典型的加以收集,描述,归纳和分享. 摘要:此文描述了笔者接触过的部分信息系统 ...
- 信息系统实践手记6-JS调用Flex的性能问题一例
说明:信息系统实践手记系列是系笔者在平时研发中先后遇到的大小的问题,也许朴实和细微,但往往却是经常遇到的问题.笔者对其中比较典型的加以收集,描述,归纳和分享. 摘要:此文描述了笔者接触过的部分信息系统 ...
- SQL Server 2016 CTP2.2 安装手记
SQL Server 2016 CTP2.2 安装手记 下载一个iso文件,解压出来(大约2.8G左右),在该路径下双击Setup.exe即可开始安装. 安装之前请先安装.NET 3.5 SP1,在服 ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [二] 基本使用
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 使用环境 Visual Studio 2015 or later .NET 4 ...
随机推荐
- 数据结构笔记之跳表(SkipList)
一.跳表简述 跳表可以看做是一个带有索引的链表,在介绍跳表之前先看一下一个普通的链表,假如当前维护了一个有序的链表: 现在要在这个链表中查找128,因为事先不知道链表中数值的分布情况,我们只能从前到后 ...
- 【ARTS】01_06_左耳听风-20181217~1223
ARTS: Algrothm: leetcode算法题目 Review: 阅读并且点评一篇英文技术文章 Tip/Techni: 学习一个技术技巧 Share: 分享一篇有观点和思考的技术文章 Algo ...
- Linux内核源码分析--内核启动之(1)zImage自解压过程(Linux-3.0 ARMv7) 【转】
转自:http://blog.chinaunix.net/uid-25909619-id-4938388.html 研究内核源码和内核运行原理的时候,很总要的一点是要了解内核的初始情况,也就是要了解内 ...
- 经典sql-获取当前文章的上一篇和下一篇
我们在做资讯类的网站的时候,肯定会有这么一个需求,就是在资讯内容页的下方需要给出上一篇和下一篇资讯的链接.上次我一同事兼好友兼室友就遇到了这么一个需求,一开始我们都把问题想复杂了,先取的是符合条件的资 ...
- ubuntu 安装(install) pwntcha[一个做"验证码识别"的开源程序]
一.安装 1. sudo apt-get install libsdl1.2-dev libsdl1.2debian sudo apt-get install libsdl1.2-dev(比较大,10 ...
- maven dependencies 报错
maven配置的环境变量有问题: 用最新的maven替换系统默认的setting.xml文件即可
- Coursera台大机器学习技法课程笔记12-Neural Network
由perceptron线性组成的一个神经网络: 通过赋予g不同的权值,来实现不同的切分功能: 但有的切分只通过一次特征转换是不够的,需要多次转换,如下: Neural Network Hypothes ...
- python强大的数据类型转换
# 原始的二维表数据集 jsonObj=[] # 添加模拟的数据 for i in range(1001,1004): for j in range(1,34): jsonObj.append({&q ...
- 16.网络《果壳中的c#》
16.1 网络体系结构 System.Net.* 命名空间包含各种支持标准网络协议的通信. WebClient 外观类:支持通信HTTP或FTP执行简单的下载/上传操作. WebRequest 和 W ...
- lrzsz安装
当服务器没有安装FTP等工具上传文件时,可以通过rz上传文件,sz 文件名 进行下载文件,默认下载路径为: C:\Users\用户\Downloads,安装如下: yum install lr ...