dotNetSpider 手记
准备工作:
从github上download工程。
安装VS2017。
安装 .net core 2.0。
编译通过。
基础架构:
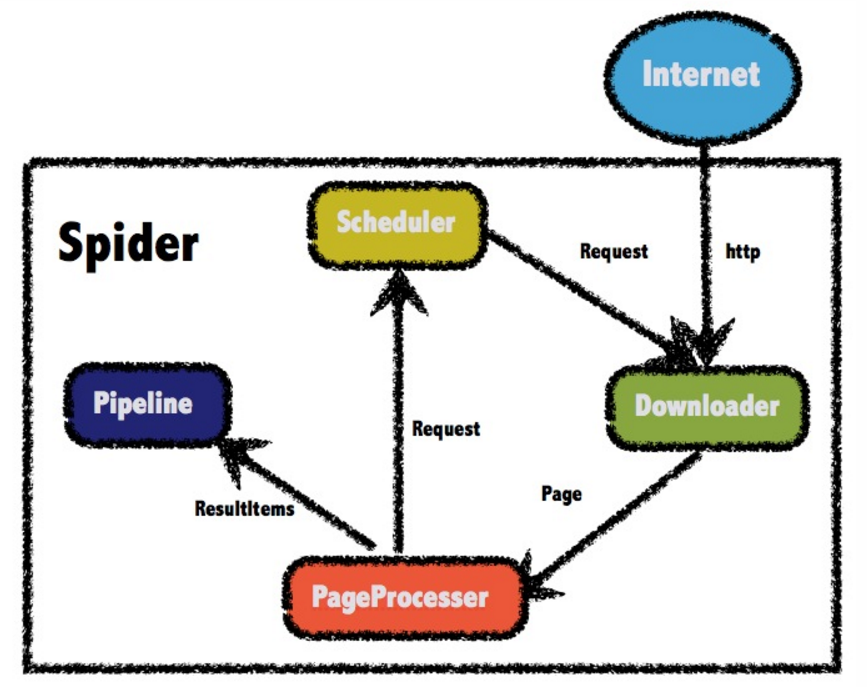
调度器 Scheduler 从根site开始,向 Downloader 分配请求任务。
Downloader 根据分配到的请求任务,向目标site 下载 page,并交由 PageProcessor 进行页面处理。
PageProcessor 将处理的结果推入 Pipeline,将解析出的新的链接,推入 Scheduler。
循环直至 Scheduler 没有新的请求可以处理。
Spider.Create:
设定根访问节点、唯一身份标识、请求调度器 Scheduler,页面处理器 PageProcessor。
以给出的 Sample 样例中,遍历 cnblog 站点为例进行解析:
Scheduler 是 QueueDuplicateRemovedScheduler。就是一个存放 Request 的队列。
PageProcessor 是默认的 DefaultPageProcessor。
这里涉及到 XPath 的知识,需要快速了解。
XPath:XPath 使用路径表达式在 XML 文档中进行导航,选取 XML 文档中的节点或者节点集。
主要知识点见:http://www.runoob.com/xpath/xpath-syntax.html
页面处理流程 BasePageProcessor.Process:

public void Process(Page page)
{
bool isTarget = true; if (_targetUrlPatterns.Count > 0 && !_targetUrlPatterns.Contains(null))
{
foreach (var regex in _targetUrlPatterns)
{
isTarget = regex.IsMatch(page.Url);
if (isTarget)
{
break;
}
}
} if (!isTarget)
{
return;
} Handle(page); page.ResultItems.IsSkip = page.ResultItems.Results.Count == 0; if (!page.SkipExtractTargetUrls)
{
ExtractUrls(page);
}
}
在 Sample 中,调用的是 DefaultPageProcessor 提供的 hanlde:
page.AddResultItem("title", page.Selectable.XPath("//title").GetValue());
page.AddResultItem("html", page.Content);
默认的页面处理,是找出 “title” 元素,以及整个 html 内容。
接着在下载好的页面内容中,查找更多的 url。
dotNetSpider 手记的更多相关文章
- Linux.NET实战手记—自己动手改泥鳅(上)
各位读者大家好,不知各位读者有否阅读在下的前一个系列<Linux.NET 学习手记>,在前一个系列中,我们从Linux中Mono的编译安装开始,到Jexus服务器的介绍,以及如何在Linu ...
- Linux.NET学习手记(7)
前一篇中,我们简单的讲述了下如何在Linux.NET中部署第一个ASP.NET MVC 5.0的程序.而目前微软已经提出OWIN并致力于发展VNext,接下来系列中,我们将会向OWIN方向转战. 早在 ...
- Linux.NET学习手记(8)
上一回合中,我们讲解了Linux.NET面对OWIN需要做出的准备,以及介绍了如何将两个支持OWIN协议的框架:SignalR以及NancyFX以OwinHost的方式部署到Linux.NET当中.这 ...
- 关于《Linux.NET学习手记(8)》的补充说明
早前的一两天<Linux.NET学习手记(8)>发布了,这一篇主要是讲述OWIN框架与OwinHost之间如何根据OWIN协议进行通信构成一套完整的系统.文中我们还直接学习如何直接操作OW ...
- U3D DrawCall优化手记
在最近,使用U3D开发的游戏核心部分功能即将完成,中间由于各种历史原因,导致项目存在比较大的问题,这些问题在最后,恐怕只能通过一次彻底的重构来解决 现在的游戏跑起来会有接近130-170个左右的Dra ...
- 信息系统实践手记5-CACHE设计一例
说明:信息系统实践手记系列是系笔者在平时研发中先后遇到的大小的问题,也许朴实和细微,但往往却是经常遇到的问题.笔者对其中比较典型的加以收集,描述,归纳和分享. 摘要:此文描述了笔者接触过的部分信息系统 ...
- 信息系统实践手记6-JS调用Flex的性能问题一例
说明:信息系统实践手记系列是系笔者在平时研发中先后遇到的大小的问题,也许朴实和细微,但往往却是经常遇到的问题.笔者对其中比较典型的加以收集,描述,归纳和分享. 摘要:此文描述了笔者接触过的部分信息系统 ...
- SQL Server 2016 CTP2.2 安装手记
SQL Server 2016 CTP2.2 安装手记 下载一个iso文件,解压出来(大约2.8G左右),在该路径下双击Setup.exe即可开始安装. 安装之前请先安装.NET 3.5 SP1,在服 ...
- [开源 .NET 跨平台 数据采集 爬虫框架: DotnetSpider] [二] 基本使用
[DotnetSpider 系列目录] 一.初衷与架构设计 二.基本使用 三.配置式爬虫 四.JSON数据解析与配置系统 使用环境 Visual Studio 2015 or later .NET 4 ...
随机推荐
- 20155303 2016-2017-2 《Java程序设计》课程总结
20155303 2016-2017-2 <Java程序设计>课程总结 目录 一.每周作业及实验报告链接汇总 二.关于博客 自认为写得最好一篇博客是?为什么? 作业中阅读量最高的一篇博客是 ...
- 安装odbc驱动
1.下载对应的驱动 (32位/64位) http://www.oracle.com/technetwork/database/database-technologies/instant-client/ ...
- Windows运行命令
winver---------检查Windows版本 wmimgmt.msc----打开windows管理体系结构 wupdmgr--------windows更新程序 winver--------- ...
- centos6.5环境通过shell脚本备份php的web及mysql数据库并做远程备份容灾
centos6.5环境通过shell脚本备份php的web及mysql数据库并做远程备份容灾 系统:centos6.5 1.创建脚本目录 mkdir -p /usr/local/sh/ 创建备份web ...
- 字符串格式化格式 -- Numeric Format Strings
- PHP跨域访问
1.允许所有域名访问 header('Access-Control-Allow-Origin: *'); 2.允许单个域名访问 header('Access-Control-Allow-Origin: ...
- 算法笔记(C++)
一.基础篇 C++标准模板库(STL) 1.vector 可以理解为“变长数组” #include <vector> vector<typename> name; vector ...
- 如何使用 Java 删除 ArrayList 中的重复元素
如何使用 Java 删除 ArrayList 中的重复元素 (How to Remove Duplicates from ArrayList in Java) Given an ArrayList w ...
- JdbcTemplate使用小结
org.springframework.jdbc.core.JdbcTemplate.query(String sql, Object[] args, RowMapper<StaffUnionV ...
- [转]C++实现平衡二叉树
作者:Rest探路者 出处:http://www.cnblogs.com/Java-Starter/ 本文版权归作者和博客园共有,欢迎转载,但未经作者同意请保留此段声明,请在文章页面明显位置给出原文 ...