将 SecondaryNameNode 配置到 s105 节点上
相关链接
0. 说明
SecondaryNameNode 的作用 参考【待补充】
在 Hadoop 完全分布式的基础之上配置
将 SecondaryNameNode 配置到 s105 节点上
集群规划如下
| 服务器主机名 | ip | 节点配置 |
| s101 | 192.168.23.101 | NameNode / ResourceManager |
| s102 | 192.168.23.102 | DataNode / NodeManager |
| s103 | 192.168.23.103 | DataNode / NodeManager |
| s104 | 192.168.23.104 | DataNode / NodeManager |
| s105 | 192.168.23.105 | SecondaryNameNode |
1. 配置 root 用户的 SSH 免密登陆
1.1 在 s101 节点上切换到 root 用户
su root
1.2 生成公私密钥对
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
1.3 配置免密登陆(完成后退出 root 用户)
ssh-copy-id root@s101
ssh-copy-id root@s102
ssh-copy-id root@s103
ssh-copy-id root@s104
ssh-copy-id root@s105
2. 编写 xcall.sh 脚本
说明
xcall.sh 脚本编写是为了多个节点同时执行相同的命令
xcall.sh 脚本如下:
#!/bin/bash # for循环
for((i= ; i<=; i++)) ; do
# 更改文本颜色
tput setaf
# 输出以下文本
echo ==================== s$i $@ ===================
# 更改文本颜色
tput setaf
# ssh 远程登陆主机 s$i ,执行输入的参数的命令
ssh s$i $@
done
为 xcall.sh 赋予可执行权限
chmod a+x xcall.sh
编写完成之后,将其发送到 /usr/local/bin 下。
mv xcall.sh /usr/local/bin
创建 jps 软链接
在 /usr/local/bin 中为 jps 创建软连接(每个服务器都要创建)
ln -s /soft/jdk/bin/jps /usr/local/bin/jps
3. 编写 xsync.sh 脚本
说明
xsync.sh 脚本编写是为了从主节点同步配置文件到子节点
xsync.sh 脚本如下:
#!/bin/bash # 指出当前用户名
name=`whoami`
# 指定文件所在文件夹名称
dir=`dirname $`
# 指定文件的文件名
filename=`basename $`
# 进入到dir中
cd $dir
# 得到当前目录的绝对路径
fullpath=`pwd` for((i= ; i<=; i++)) ; do
tput setaf
echo ==================== s$i $@ ===================
tput setaf
# 远程同步命令 l 保留软连接 r 递归文件夹
rsync -lr $filename "$name"@s"$i":$fullpath
done
为 xsync.sh 赋予可执行权限
chmod a+x xsync.sh
编写完成之后,将其发送到 /usr/local/bin 下。
mv xsync.sh /usr/local/bin
使用 root 用户权限在所有机器上安装 rsync
xcall.sh yum install -y rsync
4. 修改 & 分发配置文件
4.1 修改配置文件 [ hdfs-site.xml ]
位置在 /soft/hadoop/etc/hadoop/hdfs-site.xml
添加配置
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s105:50090</value>
</property>
4.2 分发配置文件
删除其他节点的所有 hdfs-site.xml
ssh s102 rm -r /soft/hadoop/etc/hadoop/hdfs-site.xml
ssh s103 rm -r /soft/hadoop/etc/hadoop/hdfs-site.xml
ssh s104 rm -r /soft/hadoop/etc/hadoop/hdfs-site.xml
ssh s105 rm -r /soft/hadoop/etc/hadoop/hdfs-site.xml
使用 xsync.sh 脚本将所有配置文件进行同步
xsync.sh /soft/hadoop/etc/hadoop/hdfs-site.xml
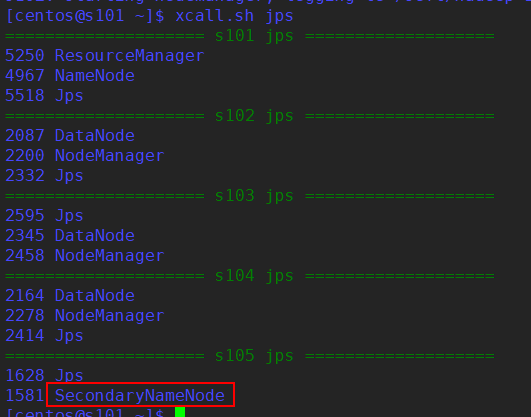
5. 启动 Hadoop & 验证 SecondaryNameNode 配置成功
启动 Hadoop
start-all.sh
验证 SecondaryNameNode 配置成功
xcall.sh jps
将 SecondaryNameNode 配置到 s105 节点上的更多相关文章
- OpenStack-Ocata版+CentOS7.6 云平台环境搭建 — 6.在计算节点上安装并配置计算服务Nova
安装和配置计算节点这个章节描述如何在计算节点上安装和配置计算服务. 计算服务支持几种不同的 hypervisors.为了简单起见,这个配置在计算节点上使用 :KVM <kernel-based ...
- 从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点)
从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www ...
- TaskTracker节点上的内存管理器
Hadoop平台的最大优势就是充分地利用了廉价的PC机,这也就使得集群中的工作节点存在一个重要的问题——节点所在的PC机内存资源有限(这里所说的工作节点指的是TaskTracker节点),执行任务时常 ...
- SQL Server Alwayson配置两个节点加共享文件夹仲裁见证
标签:MSSQL/节点和共享文件夹多数 概述 之前讲过多数节点的仲裁配置,多数节点一般3个节点以上的奇数个节点:常见的是使用3个节点节点多了也是浪费因为Alwayson的只读路由只能利用到一个只读副本 ...
- OpenStack搭建Q版在控制节点上的环境准备(step2)
接下来是只需要在控制节点上准备的环境配置.其中虽然NTP服务需要在所有节点上都安装,但NTP服务在控制节点和其他的节点上的配置是不同的,所以不把它放在step1的公共配置中进行准备.如下: 1.配置N ...
- NodePort 只能在node节点上访问,外部无法访问
创建了一个NodePort类型的jenkins service,node port 30000,node节点ip为192.168.56.101, 在node节点上通过浏览器能正常访问http://19 ...
- OpenStack-Ocata版+CentOS7.6 云平台环境搭建 — 5.在控制节点上部署计算服务Nova
计算服务Nova使用OpenStack Compute来托管和管理云计算系统. OpenStack Compute是基础架构即服务(IaaS)系统的主要部分. 主要模块用Python实现.OpenSt ...
- hdfs 如何实现退役节点快速下线(也就是退役节点上的数据块快速迁移)speed up decommission blocks removal
以下是选择复制源节点的代码 代码总结: A=datanode上要复制block的Queue size与 target datanode没被选出之前待处理复制工作数之和. 1. 优先选择退役中的节点,因 ...
- 三、安装并配置Kubernetes Node节点
1. 安装并配置Kubernetes Node节点 1.1 安装Kubernetes Node节点所需服务 yum -y install kubernetes 通过yum安装kubernetes服 ...
随机推荐
- ASP.NET MVC 表格操作
Beginners Guide for Creating GridView in ASP.NET MVC 5 http://www.codeproject.com/Articles/1114208/B ...
- ASP.NET MVC HtmlHelper 类的扩展方法
再ASP.NET MVC编程中用到了R语法,在View页面编辑HTML标签的时候,ASP.NET MVC 为我们准备好了可以辅助我们写这些标签的办法,它们就是HtmlHelper.微软官方地址是:ht ...
- linux firefox 快捷方式
.输入:cd /usr/share/applications .输入:vi firefox.desktop 在vi里面输入以下内容,然后保存并退出: [Desktop Entry] Name=Fire ...
- java arrayList vector 区别
1. 关系图 List接口一共有三个实现类,分别是ArrayList.Vector和LinkedList 2. ArrayList.Vector和LinkedList区别 ArrayList是最常用的 ...
- layer插件学习——icon样式
本文是自己整理的关于layer插件的icon样式结果 一.准备工作 下载jQuery插件和layer插件,并引入插件(注意:jQuery插件必须在layer插件之前引用) 百度云资源链接: jQuer ...
- ruby中字符串转换为类
最近有个需求,需要根据一个字符串当作一个类来使用,例如: 有一个字符串 “ChinaMag”,根据这个字符串调用 类 ChinaMag下的方法. 解决办法: 1. rails可以使用 constant ...
- ThreadLocal剧集(一)
总述 最近做了一个日志调用链路跟踪的项目,涉及到操作标识在线程和子线程,线程池以及远程调用之间的传递问题.最终采用了阿里开源的TransmittableThreadLocal插件(https: ...
- 创建第一个MVC应用程序
整个国庆期假,Insus.NET没有出门,在家静心修炼MVC.这意味着Insus.NET将来的日子里会以MVC为学习,开发,应用作为重点,不过现在才开始踏出第一步...... 路慢慢...... 下载 ...
- C# winform 无边框 窗体的拖动
当船体设置为FormborderStyle='none' [DllImport("user32.dll")] public static extern bool ReleaseCa ...
- [javaSE] 集合框架(体系概述)
为什么出现集合类 为了方便对多个对象的操作,对对象进行存储,集合就是存储对象最常用的一种方式 数组和集合的不同 数组是固定长度的,集合是可变长度的 数组可以存储基本数据类型,集合只能存储对象 数组只能 ...