【深度学习篇】--神经网络中的调优一,超参数调优和Early_Stopping
一、前述
调优对于模型训练速度,准确率方面至关重要,所以本文对神经网络中的调优做一个总结。
二、神经网络超参数调优
1、适当调整隐藏层数
对于许多问题,你可以开始只用一个隐藏层,就可以获得不错的结果,比如对于复杂的问题我们可以在隐藏层上使用足够多的神经元就行了, 很长一段时间人们满足了就没有去探索深度神经网络,
但是深度神经网络有更高的参数效率,神经元个数可以指数倍减少,并且训练起来也更快!(因为每个隐藏层上面神经元个数减少了可以完成相同的功能,则连接的参数就少了)
就好像直接画一个森林会很慢,但是如果画了树枝,复制粘贴树枝成大树,再复制粘贴大树成森林却很快。真实的世界通常是这种层级的结构,DNN就是利用这种优势。
前面的隐藏层构建低级的结构,组成各种各样形状和方向的线,中间的隐藏层组合低级的结构,譬如方块、圆形,后面的隐藏层和输出层组成更高级的结构,比如面部。
仅这种层级的结构帮助DNN收敛更快,同时增加了复用能力到新的数据集,例如,如果你已经训练了一个神经网络去识别面部,你现在想训练一个新的网络去识别发型,你可以复用前面的几层,就是不去随机初始化Weights和biases,你可以把第一个网络里面前面几层的权重值赋给新的网络作为初始化,然后开始训练(整体来看会提高速度)。
这样网络不必从原始训练低层网络结构,它只需要训练高层结构,例如,发型
对于很多问题,一个到两个隐藏层就是够用的了,MNIST可以达到97%当使用一个隐藏层上百个神经元,达到98%使用两
个隐藏层,对于更复杂的问题,你可以逐渐增加隐藏层,直到对于训练集过拟合。(会经常过拟合,因为会不断地调整参数)
非常复杂的任务譬如图像分类和语音识别,需要几十层甚至上百层,但不全是全连接,并且它们需要大量的数据,不过,你很少需要从头训练,非常方便的是复用一些提前训练好的类似业务的经典的网络。那样训练会快很多并且需要不太多的数据
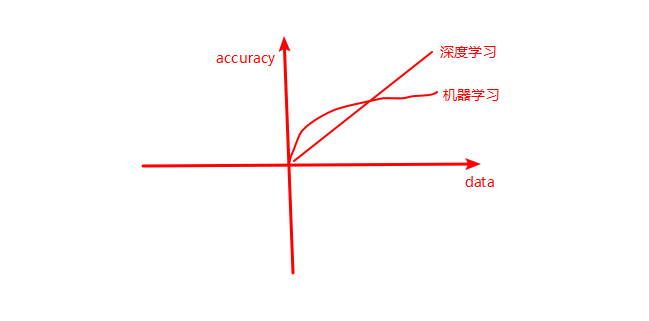
当数据量不大的时候选择机器学习(浅层模型)准确率好,数据量大的时候选择深度学习。
2、每个隐藏层的神经元个数
输入层和输出层的神经元个数很容易确定,根据需求,比如MNIST输入层28*28=784,输出层10
通常的做法是每个隐藏层的神经元越来越少,比如第一个隐藏层300个神经元,第二个隐藏层100个神经元,可是,现在更多的是每个隐藏层神经元数量一样,比如都是150个,这样超参数需要调节的就少了,正如前面寻找隐藏层数量一样,可以逐渐增加数量直到过拟合,找到完美的数量更多还是黑科技。
简单的方式是选择比你实际需要更多的层数和神经元个数(很容易过拟合),然后使用early stopping去防止过拟合,还有L1、L2正则化技术,还有dropout
三、防止过拟合技术
1、Early stopping(需要验证集)
去防止在训练集上面过拟合,
1.1 一个很好的手段是early stopping,
当在验证集上面开始下降的时候中断训练,一种方式使用TensorFlow去实现,是间隔的比如每50 steps,在验证集上去评估模型,然后保存一下快照如果输出性能优于前面的快照,记住最后一次保存快照时候迭代的steps的数量,当到达step的limit次数的时候,restore最后一次胜出的快照。
尽管early stopping实际工作做不错,你还是可以得到更好的性能当结合其他正则化技术一起的话
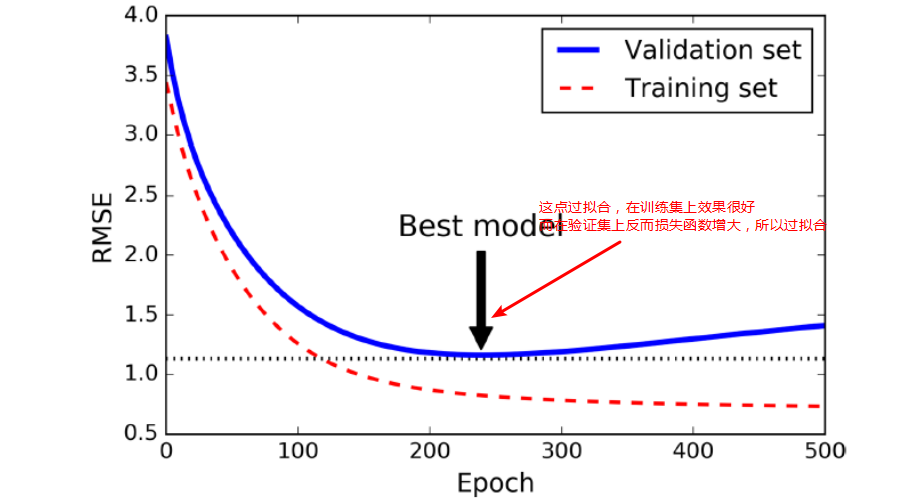
上图中则需要当迭代次数运行完后,resotore损失函数最小的w参数。
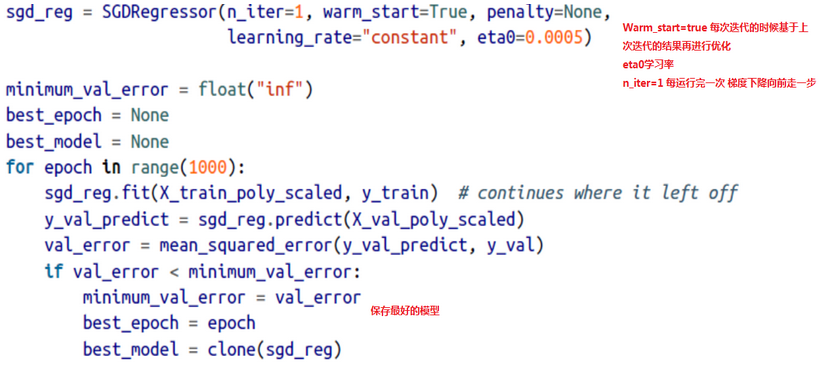
1.2、代码示范:
【深度学习篇】--神经网络中的调优一,超参数调优和Early_Stopping的更多相关文章
- 吴恩达《深度学习》第二门课(3)超参数调试、Batch正则化和程序框架
3.1调试处理 (1)不同超参数调试的优先级是不一样的,如下图中的一些超参数,首先最重要的应该是学习率α(红色圈出),然后是Momentum算法的β.隐藏层单元数.mini-batch size(黄色 ...
- 【深度学习与神经网络】深度学习的下一个热点——GANs将改变世界
本文作者 Nikolai Yakovenko 毕业于哥伦比亚大学,目前是 Google 的工程师,致力于构建人工智能系统,专注于语言处理.文本分类.解析与生成. 生成式对抗网络-简称GANs-将成为深 ...
- 【腾讯Bugly干货分享】深度学习在OCR中的应用
本文来自于腾讯bugly开发者社区,未经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/5809bb47cc5e52161640c5c8 Dev Club 是一个交流移动 ...
- 【AI in 美团】深度学习在OCR中的应用
AI(人工智能)技术已经广泛应用于美团的众多业务,从美团App到大众点评App,从外卖到打车出行,从旅游到婚庆亲子,美团数百名最优秀的算法工程师正致力于将AI技术应用于搜索.推荐.广告.风控.智能调度 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1
3.Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.2
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.2 http://blog.csdn.net/sunbow0 ...
- 针对深度学习(神经网络)的AI框架调研
针对深度学习(神经网络)的AI框架调研 在我们的AI安全引擎中未来会使用深度学习(神经网络),后续将引入AI芯片,因此重点看了下业界AI芯片厂商和对应芯片的AI框架,包括Intel(MKL CPU). ...
- 【深度学习】CNN 中 1x1 卷积核的作用
[深度学习]CNN 中 1x1 卷积核的作用 最近研究 GoogLeNet 和 VGG 神经网络结构的时候,都看见了它们在某些层有采取 1x1 作为卷积核,起初的时候,对这个做法很是迷惑,这是因为之前 ...
- 深度学习训练过程中的学习率衰减策略及pytorch实现
学习率是深度学习中的一个重要超参数,选择合适的学习率能够帮助模型更好地收敛. 本文主要介绍深度学习训练过程中的6种学习率衰减策略以及相应的Pytorch实现. 1. StepLR 按固定的训练epoc ...
随机推荐
- rabbit入门教程
简介 rabbitmq是一个消息代理系统,为应用提供一个通用得消息发布,接受平台,为应用提供非阻塞的消息系统,方便进行异步处理. 优点 消息的可靠性.持久化消息,消息接受确认,消息重传等可靠机制. 灵 ...
- 爬虫之scrapy-splash
什么是splash Splash是一个Javascript渲染服务.它是一个实现了HTTP API的轻量级浏览器,Splash是用Python实现的,同时使用Twisted和QT.Twisted(QT ...
- api_response.go
, "METHOD_NOT_ALLOWED"} }, Log(l), V1)(w, req, nil) }) }
- 1.2 lambda 表达式的语法
1.2 lambda 表达式的语法 还以上一节中的排序为例.我们传递代码来检查某个字符串的长度是否小于另一个字符串的长度,如下所示: Integer.compare(first.length(), s ...
- vector作为函数返回值
在实际的操作中,我们经常会碰到需要返回一序列字符串或者一列数字的时候,以前会用到数组来保存这列的字符串或者数字,现在我们可以用vector来保存这些数据.但是当数据量很大的时候使用vector效率就比 ...
- bzoj 1098 poi2007 办公楼 bfs+链表
题意很好理解,求给出图反图的联通块个数. 考虑这样一个事情:一个联通块里的点,最多只会被遍历一次,再遍历时没有任何意义 所以用链表来存,每遍历到一个点就将该点删掉 #include<cstdio ...
- BZOJ_4197_[Noi2015]寿司晚宴_状态压缩动态规划
BZOJ_4197_[Noi2015]寿司晚宴_状态压缩动态规划 Description 为了庆祝 NOI 的成功开幕,主办方为大家准备了一场寿司晚宴.小 G 和小 W 作为参加 NOI 的选手,也被 ...
- 显著性检测(saliency detection)评价指标之NSS的Matlab代码实现
calcNSSscore.m function [ score ] = calcNSSscore( salMap, eyeMap ) %calcNSSscore Calculate NSS score ...
- gin框架使用注意事项
gin框架使用注意事项 本文就说下这段时间我在使用gin框架过程中遇到的问题和要注意的事情. 错误处理请求返回要使用c.Abort,不要只是return 当在controller中进行错误处理的时候, ...
- ssm框架搭建和整合流程
Spring + SpringMVC + Mybatis整合流程 1 需求 1.1 客户列表查询 1.2 根据客户姓名模糊查询 2 整合思路 第一步:整合dao层 ...