Python 爬取 中关村CPU名字和主频
0.准备工作
1.相关教程
2.说明
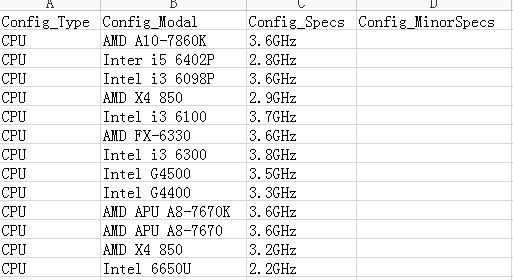
3.效果
1.获取CPU型号和主频信息
1.神伤的AJAX
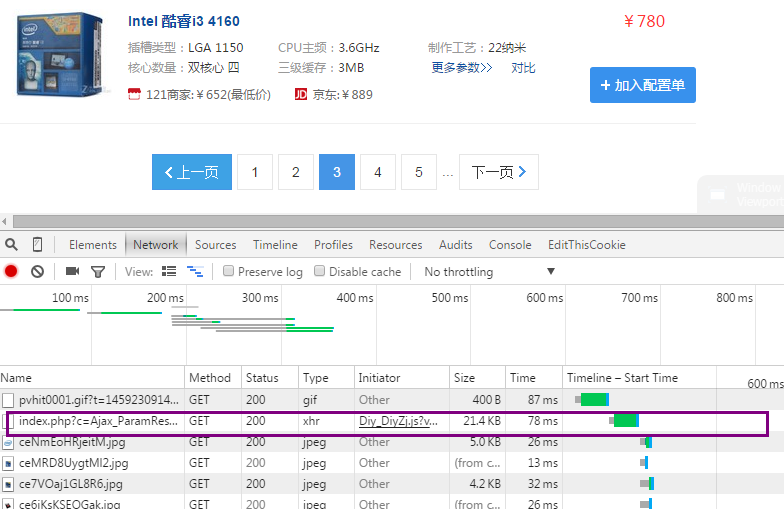
2.获取CPU名字
#-*- coding: UTF-8 -*-
import urllib
import re
from bs4 import BeautifulSoup
url='http://zj.zol.com.cn/index.php?c=Ajax_ParamResponse&a=GetGoods&subcateId=28&type=0&priceId=noPrice&page=2&manuId=¶mStr=&keyword=&locationId=1&queryType=0'
html = urllib.urlopen(url).read()
soup=BeautifulSoup(html,"html.parser")
listModal=[]
listSpecs=[]
tags = soup.find_all("a",attrs={"target":"\\\"_blank\\\""})
cnt=0
for tag in tags:
cnt+=1
modalSubstr=tag.contents[0]
#print 'modalSubstr:'+modalSubstr
manufacturer=re.findall('(.+?) ',modalSubstr)[0]#非贪心匹配 遇到空格即中止,返回第一个匹配项
#print 'manufacturer:'+manufacturer
detailSubstr=re.findall(' ([0-9a-zA-Z- ]+)',modalSubstr)
#print detailSubstr
detailSubstr0=detailSubstr[0]
#针对i3、i5、i7的处理
if "i3" in modalSubstr:
modalDetail="i3 "+detailSubstr0
elif "i5" in modalSubstr:
modalDetail="i5 "+detailSubstr0
elif "i7" in modalSubstr:
modalDetail="i7 "+detailSubstr0
else:
modalDetail=detailSubstr0
#针对APU的处理
if modalDetail=="APU":
modalDetail+=" "+detailSubstr[1] modal=manufacturer+" "+modalDetail
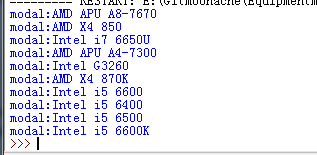
print "modal:"+modal
3.获取CPU主频
#-*- coding: UTF-8 -*-
import urllib
import re
from bs4 import BeautifulSoup
url='http://zj.zol.com.cn/index.php?c=Ajax_ParamResponse&a=GetGoods&subcateId=28&type=0&priceId=noPrice&page=2&manuId=¶mStr=&keyword=&locationId=1&queryType=0'
html = urllib.urlopen(url).read()
soup=BeautifulSoup(html,"html.parser")
listModal=[]
listSpecs=[]
tags = soup.find_all("a",attrs={"target":"\\\"_blank\\\""})
cnt=0
for tag in tags:
cnt+=1
print cnt
substr=str(tag)[100:500]
#以title='\"开头+任意小数+ GHz结尾
specsDictionary=re.findall(r'title=\'\\\"([0-9.]+GHz)',substr)
try:
specs=specsDictionary[0]
except IndexError:
specs="Data Missed"
print specs

4.循环读取下一页并自动终止

urlLeft='http://zj.zol.com.cn/index.php?c=Ajax_ParamResponse&a=GetGoods&subcateId=28&type=0&priceId=noPrice&page='
urlRight='&manuId=¶mStr=&keyword=&locationId=1&queryType=0'
urlPageIndex=1
while (1):
url=urlLeft+str(urlPageIndex)+urlRight
html = urllib.urlopen(url).read()
soup=BeautifulSoup(html,"html.parser")
soupSub=str(soup)[0:50]
pageIndex=int(re.findall('page\":([0-9]+)',soupSub)[0])
if urlPageIndex==pageIndex:
tags = soup.find_all("a",attrs={"target":"\\\"_blank\\\""})
cnt=0
for tag in tags:
......省略
print "yes"+str(urlPageIndex)
urlPageIndex+=1
else:
print "no"+str(urlPageIndex)
break
5.输出为csv
import csv
with open('excel_2010_ms-dos.csv', 'rb') as csvfile:
spamreader = csv.reader(csvfile, dialect='excel')
for row in spamreader:
print ', '.join(row)
6.最终代码
#-*- coding: UTF-8 -*-
import urllib
import re
import csv
from bs4 import BeautifulSoup
listModal=[]
listSpecs=[]
urlLeft='http://zj.zol.com.cn/index.php?c=Ajax_ParamResponse&a=GetGoods&subcateId=28&type=0&priceId=noPrice&page='
urlRight='&manuId=¶mStr=&keyword=&locationId=1&queryType=0'
urlPageIndex=1
while (1):
url=urlLeft+str(urlPageIndex)+urlRight
html = urllib.urlopen(url).read()
soup=BeautifulSoup(html,"html.parser")
soupSub=str(soup)[0:50]
pageIndex=int(re.findall('page\":([0-9]+)',soupSub)[0])
if urlPageIndex==pageIndex:
tags = soup.find_all("a",attrs={"target":"\\\"_blank\\\""})
cnt=0
for tag in tags:
cnt+=1
modalSubstr=tag.contents[0]
manufacturer=re.findall('(.+?) ',modalSubstr)[0]#非贪心匹配 遇到空格即中止,返回第一个匹配项
detailSubstr=re.findall(' ([0-9a-zA-Z- ]+)',modalSubstr)
detailSubstr0=detailSubstr[0]
#针对i3、i5、i7的处理
if "i3" in modalSubstr:
modalDetail="i3 "+detailSubstr0
elif "i5" in modalSubstr:
modalDetail="i5 "+detailSubstr0
elif "i7" in modalSubstr:
modalDetail="i7 "+detailSubstr0
else:
modalDetail=detailSubstr0
#针对APU的处理
if modalDetail=="APU":
modalDetail+=" "+detailSubstr[1]
modal=manufacturer+" "+modalDetail
listModal.append(modal)
substr=str(tag)[100:500]
#以title='\"开头+任意小数+ GHz结尾
specsDictionary=re.findall(r'title=\'\\\"([0-9.]+GHz)',substr)
try:
specs=specsDictionary[0]
except IndexError:
specs="Data Missed"
listSpecs.append(specs)
print "yes"+str(urlPageIndex)
urlPageIndex+=1
else:
print "no"+str(urlPageIndex)
break
with open('Config.csv', 'wb') as csvfile:
spamwriter = csv.writer(csvfile, dialect='excel')
#write 标题行
spamwriter.writerow(['Config_Type','Config_Modal','Config_Specs','Config_MinorSpecs'])
i=0
for elementModal in listModal:
spamwriter.writerow(['CPU',listModal[i], listSpecs[i]])
i+=1
Python 爬取 中关村CPU名字和主频的更多相关文章
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取LOL英雄皮肤
Python爬取LOL英雄皮肤 Python 爬虫 一 实现分析 在官网上找到英雄皮肤的真实链接,查看多个后发现前缀相同,后面对应为英雄的ID和皮肤的ID,皮肤的ID从00开始顺序递增,而英雄ID跟 ...
- 萌新学习Python爬取B站弹幕+R语言分词demo说明
代码地址如下:http://www.demodashi.com/demo/11578.html 一.写在前面 之前在简书首页看到了Python爬虫的介绍,于是就想着爬取B站弹幕并绘制词云,因此有了这样 ...
- Python爬取网页信息
Python爬取网页信息的步骤 以爬取英文名字网站(https://nameberry.com/)中每个名字的评论内容,包括英文名,用户名,评论的时间和评论的内容为例. 1.确认网址 在浏览器中输入初 ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- Python爬取 | 唯美女生图片
这里只是代码展示,且复制后不能直接运行,需要配置一些设置才行,具体请查看下方链接介绍: Python爬取 | 唯美女生图片 from selenium import webdriver from fa ...
- Python爬取 | 王者荣耀英雄皮肤海报
这里只展示代码,具体介绍请点击下方链接. Python爬取 | 王者荣耀英雄皮肤海报 import requests import re import os import time import wi ...
- Python 爬取途虎养车 全系车型 轮胎 保养 数据
Python 爬取途虎养车 全系车型 轮胎 保养 数据 2021.7.27 更新 增加标题.发布时间参数 demo文末自行下载,需要完整数据私聊我 2021.2.19 更新 增加大保养数据 2020. ...
随机推荐
- 让SpringMVC Restful API优雅地支持多版本
好久没有更新博客,难得有空,记录一下今天写的一个小工具,供有需要的朋友参考. 在移动APP开发中,多版本接口同时存在的情况经常发生,通常接口支持多版本,有以下两种方式: 1.通过不同路径区分不同版本 ...
- JAVAEE——BOS物流项目04:学习计划、datagrid、分页查询、批量删除、修改功能
1 学习计划 1.datagrid使用方法(重要) n 将静态HTML渲染为datagrid样式 n 发送ajax请求获取json数据创建datagrid n 使用easyUI提供的API创建data ...
- 浅学vue
因之前项目接触了vue,从此我被迷住,简洁而不失优雅,小巧而不乏大匠. 首先我们要了解vue,什么是vue,正如官网所说:Vue.js 是一套构建用户界面的渐进式框架,Vue 的核心库只关注视图层.V ...
- composer引用本地git做为源库
PHP使用者大多对composer是又爱又恨,爱的是composer require后,很多类库不用去下载了,恨的是网速卡成翔,虽然国内有很多道友做了镜象,但对于bower库这些都还是整体更新. 那么 ...
- macbook air扩展显示器全屏滑动怎样不一起滑动?
macbook air 外接了一个显示器(扩展),当我有多个桌面时,用手指滑动触控板切换桌面时,扩展屏幕也跟着切换桌面有什么办法能让我在切换主屏幕桌面的时候,扩展屏幕保持不动呢?上周还好好的,昨晚关机 ...
- dnspython模块安装
wget http://www.dnspython.org/kits/1.12.0/dnspython-1.12.0.tar.gz tar -zxvf dnspython-1.12.0.tar.gz ...
- 关于ruby -gem无法切换淘宝源
ruby官网提供的 淘宝的gem源 不起作用 https://ruby.taobao.org/ taobao Gems 源已停止维护,现由 ruby-china 提供镜像服务 http://gems. ...
- linux磁盘及分区详解
1.Linux 分区简介 1.1 主分区 vs 扩展分区 硬盘分区表中最多能存储四个分区,但我们实际使用时一般只分为两个分区,一个是主分区(Primary Partion)一个是扩展分区(extend ...
- 自定义JpaUtil,快速完成Hql执行逻辑(一)
这段时间学习Spring Data JPA功能模块.Java持久性API(简称JAP)是类和方法的集合,以海量数据关系映射持久并存储到数据库,这是由Oracle公司提供方案技术.在JAVA社区,深受爱 ...
- HDU - 3038 种类并查集
思路:种类并查集的每个节点应该保存它的父节点以及他和父节点之间的关系.假设root表示根结点,sum[i-1]表示i到根结点的和,那么sum[j-1] - sum[i]可以得到区间[j, i]的和.那 ...