Python encode和decode
今天在写一个StringIO.write(int)示例时思维那么一发散就拐到了字符集的问题上,顺手搜索一发,除了极少数以外,绝大多数中文博客都解释的惨不忍睹,再鉴于被此问题在oracle的字符集体系中蹂躏过,因此在过往笔记的基础上增删了几个示例贴出来。
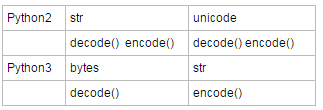
Python2:
首先清楚两个Python 2中的概念:str和unicode 这是python2中的两种用于表示文本的类型,一般来说你直接打出的字符都属于前者,加了u前缀的字符则属于后者。
str is text representation in bytes, unicode is text representation in characters.
此观点来自stackoverflow,是得票最多的一个回答,也是我认为最好的一个,但是从我个人的角度来看这个表述依然不足,最适合的表述应当是:
str is text representation in bytes, unicode is text representation in unicode characters(or unicode bytes).
貌似没多大区别......可能会被人打,但我的意思是python2里的unicode是字符和编码绑定的,只要是unicode类型那么他的编码和字符都已经固定了,但是str类型却只有编码,只有最初打出它的人才知道他的字符是什么(或者说才能通过适当的字符集解码为人眼可懂的字符)。
Python2里的str是十六进制表示的二进制编码,unicode是一个字符:
通俗点来说就是Python2里的str类型是一堆二进制编码,如果不知道是什么字符集那么你除了一堆十六进制
数什么都看不出来(当然平时你使用的工具都是能看到的,因为工具已经做了转码),通过decode可以将其按固定的字符集解码,生成unicode字符。
例如下例(python2环境下的windows cmd窗口):
>>> a='你好'
>>> a.decode('utf-8')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Python27\lib\encodings\utf_8.py", line 16, in decode
return codecs.utf_8_decode(input, errors, True)
UnicodeDecodeError: 'utf8' codec can't decode byte 0xc4 in position 0: invalid continuation byte
错误的原因是这里的“你好”字符是cp936编码(相当于gbk),utf-8属于非ANSI体系的编码,“你好”的gbk二进制码不符合unicode体系的编码规则因此报错。
>>> print a.decode('gbk'),type(a.decode('gbk'))
你好 <type 'unicode'>
这样就可以啦,既然a是gbk编码的str那么按gbk进行decode解码,自然能得到unicode的你好字符。
decode: str to unicode,decode的输入必须是str类型,输出一定是unicode类型
str.decode(encoding='UTF-8',errors='strict')
encode: unicode to str,encode的输入必须是unicode类型,输出一定是str类型
unicode_char.encode(encoding='gbk',errors='strict')
Python3:
在Python3中str调用decode()方法会遇到: AttributeError: 'str' object has no attribute 'decode' .
why?
这是因为python3中表示文本的只有一种类型了,那就是str,你以为这是python2里的那个str吗?No! 这个str是python2中的unicode类型......
那么原来的str哪里去了?被命名为bytes类型了,decode方法也随之给了bytes类型,encode给了str类型。
这样做的好处是:
在Python2中str和unicode都有decode,encode两种方法,但是字符集参数不设置正确的话,函数经常报错,文本能否正确流通取决于大家是否清楚输入编码的字符集,这对于全球化的网站来说是个巨坑,而在Python3中无论你输入什么字符,统一都是str类型的(也就是python2里的unicode类型),通过bytes和str类型的分离将decode,encode这两种方法分离,encode函数不会出错,因为编码与字符集是绑定的,你可以随意将unicode字符转化为任意ANSI体系字符集的bytes类型,此时在已知ANSI字符集的情况下,你对bytes类型的decode转码一定不会出错。通过这种方式就避免了python2中输入str类型带来的编码混乱问题。
[root@python ~]# python3
Python 3.6.5 (default, Apr 9 2018, 17:15:34)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-4)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> a='你好'
>>> type(a)
<class 'str'>
>>> a.encode('gbk')
b'\xc4\xe3\xba\xc3'
>>> type(a.encode('gbk'))
<class 'bytes'>
通过encode方式我们可以把unicode字符转为任意字符集的bytes类型,这种bytes类型可以通过decode()来重新转为unicode。
使用相似的观点来表述Python3中的bytes和str的区别就是:
bytes is text representation in bytes only if you know the charset, str is text representation in unicode characters(or unicode bytes).
Python encode和decode的更多相关文章
- python encode和decode函数说明【转载】
python encode和decode函数说明 字符串编码常用类型:utf-8,gb2312,cp936,gbk等. python中,我们使用decode()和encode()来进行解码和编码 在p ...
- python encode和decode函数说明
字符串编码常用类型:utf-8,gb2312,cp936,gbk等. Python中,我们使用decode()和encode()来进行解码和编码 在python中,使用unicode类型作为编码的基础 ...
- 【python】python新手必碰到的问题---encode与decode,中文乱码[转]
转自:http://blog.csdn.net/a921800467b/article/details/8579510 为什么会报错“UnicodeEncodeError:'ascii' codec ...
- 【python】浅谈encode和decode
对于encode和decode,笔者也是根据自己的理解,有不对的地方还请多多指点. 编码的理解: 1.编码:utf-8,utf-16,gbk,gb2312,gb18030等,编码为了便于理解,可以把它 ...
- python的str,unicode对象的encode和decode方法
python的str,unicode对象的encode和decode方法 python中的str对象其实就是"8-bit string" ,字节字符串,本质上类似java中的byt ...
- Python字符串的encode与decode研究心得——解决乱码问题
转~Python字符串的encode与decode研究心得——解决乱码问题 为什么Python使用过程中会出现各式各样的乱码问题,明明是中文字符却显示成“/xe4/xb8/xad/xe6/x96/x8 ...
- 【Python】关于decode和encode
#-*-coding:utf-8 import sys ''' *首先要搞清楚,字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码, 即先将 ...
- Python 关于 encode与decode 中文乱码问题
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(en ...
- [转]python新手必碰到的问题---encode与decode,中文乱码--转载
edu.codepub.com/2009/1029/17037.php 这个问题在python3.0里已经解决了. 这有篇很好的文章,可以明白这个问题: 为什么会报错“UnicodeEncodeErr ...
随机推荐
- 基于html5 plus + Mui 移动App开发(三)-食全库
食全库-食品安全知识库. 食品安全(food safety)指食品无毒.无害,符合应当有的营养要求,对人体健康不造成任何急性.亚急性或者慢性危害.根据倍诺食品安全定义,食品安全是“食物中有毒.有害物质 ...
- Android项目实战(五十四):zxing 生成二维码图片去除白色内边距的解决方案
目录:zxing->encoding->EncodingHandler类 中修改 createQRCode方法 private static final int BLACK = 0xff0 ...
- 关于微信JS-SDK 分享接口的两个报错记录
一.前提: 微信测试号,用微信开发者工具测试 二.简单复述文档: 1.引入JS文件 在需要调用JS接口的页面引入如下JS文件,(支持https):http://res.wx.qq.com/open/j ...
- windows之自动化在虚拟机部署操作系统并自带python环境
(1)使用详情: **************************** * 操作说明 * **************************** 1.修改Config文件夹中的Se ...
- scrapy设置代理的方法
方法一: 直接在spider文件下设置代理,通过传参的方式设置在Request中 import scrapy class MimvpSpider(scrapy.spiders.Spider): nam ...
- SpringBoot2.0之五 优雅整合SpringBoot2.0+MyBatis+druid+PageHelper
上篇文章我们介绍了SpringBoot和MyBatis的整合,可以说非常简单快捷的就搭建了一个web项目,但是在一个真正的企业级项目中,可能我们还需要更多的更加完善的框架才能开始真正的开发,比如连接池 ...
- 在asp.net core2.1中添加中间件以扩展Swashbuckle.AspNetCore3.0支持简单的文档访问权限控制
Swashbuckle.AspNetCore3.0 介绍 一个使用 ASP.NET Core 构建的 API 的 Swagger 工具.直接从您的路由,控制器和模型生成漂亮的 API 文档,包括用于探 ...
- Android框架式编程之RxJava(一):HelloWorld
Hello World 源码: import android.graphics.Bitmap; import android.graphics.BitmapFactory; import androi ...
- 学习EtherCAT的感想
第一次进入到自动化领域,接触的第一个项目就是EtherCAT的测试.初次接触以太网,有一点茫然,百度看了很多关于EtherCAT的介绍,看了一些相关的论文.EtherCAT的资料很多:ETG1000. ...
- web服务器之nginx和apache的区别
① apache属于重量级的服务器,nginx属于轻量级的服务器; 区别在于对一些功能的支持,比如: pathinfo,php模块方面 ② nginx抗高并发能力强. 由于nginx采用的是异步非阻 ...