tensorflow让程序学习到函数y = ax + b中a和b的值
今天我们通过tensorflow来实现一个简单的小例子:
假如我定义一个一元一次函数y = 0.1x + 0.3,然后我在程序中定义两个变量 Weight 和 biases 怎么让我的这两个变量自己学习然后最终学习的成果就是让Weight ≈ 0.1和 biases ≈ 0.3. 开始吧!
import tensorflow as tf
import numpy as np # create data
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.1 + 0.3 ### create tensorflow structure start ### Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
biases = tf.Variable(tf.zeros([1]))
y = Weights*x_data + biases
loss = tf.reduce_mean(tf.square(y-y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss) ### create tensorflow structure end ### sess = tf.Session()
init = tf.global_variables_initializer() #very important if you define Variable
sess.run(init)
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(Weights), sess.run(biases))
接下来是运行结果图:
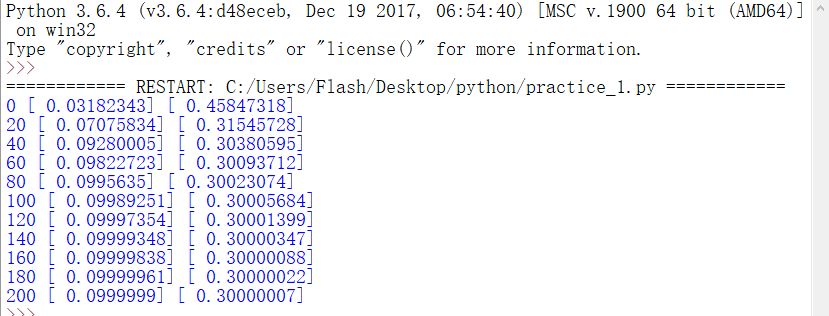
注意:我用的是python3.6版本,是在window下运行的。
我给大家介绍一下这个程序的流程吧:
首先我们需要用到tensorflow 和 numpy 模块所以要导入它们到我们的程序里面,大家习惯上给tensorflow重新命名为tf,numpy命名为np. 如果大家没有这两个版块的话网上有很多教程的...
导入版块成功以后呢,我们就开始构建数据类型了! 因为我们定义的是一元一次函数所以说我们需要自变量x, 和因变量y。 我们定义x_data为x, y_data为y
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.1 + 0.3
x_data = np.random.rand(100).astype(np.float32) 的意思是我们为x_data这个变量赋值,赋值的范围呢是100以内的随机数,这些随机数的类型是float32,因为在tensorflow里面数据类型大多都是默认为float32的。
y_data = x_data*0.1 + 0.3 就是给了y_data随xdata变化而变化的函数关系式。
接下来就是最重要的了定义Weights,biases这两个变量:
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
biases = tf.Variable(tf.zeros([1]))
y = Weights*x_data + biases
tensorflow 里面有:placeholder(占位符) 和 Variable变量 这两个可以容纳我们需要传入的值我们之所以选择Variable 是因为Variable 在运算的过程中是可以改变的,我们就是需要Weights和biases这两个变量通过不断的学习而改变自身的值最后得到相对准确的值 所以选择Variable.
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0)) 产生一个-1到1之间均匀的随机数(因为不断学习最后的值会趋近于0.1) 维度为1即一维数组也可以理解为含有一个数的列表或者就只是代表一个数
biases = tf.Variable(tf.zeros([1])) 初始值为1 维度为一
y = Weights*x_data + biases
这里的y是因为要让Weights 和 biases 学习而构建出来的 满足的函数关系式和y_data一样
loss = tf.reduce_mean(tf.square(y-y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
这步很重要,也是tensorflow学习的经典 叫做 反向传播 首先我们定义损失函数loss 因为相同x 和相同函数关系但是y和y_data的值不一样 我们通过计算(y-y_data)^2 这个表达式 然后求平均得到一个衡量标准就是要学习的y 与 正确的y_data 之间的差别loss. 然后我们构造一个优化器optimizer,optimizer = tf.train.GradientDescentOptimizer(0.5) 可以理解为这个优化器的学习效率为0.5 (0,1)之间选择,可以自己更改值来试试^_^。有了loss 有了优化器optimizer,我们干嘛呢,我们需要通过优化器来减小我们的误差(loss) 。我们称减小误差这个步骤叫做训练过程 这也是train = optimizer.minimize(loss)这句话的含义了通过减小loss从而反向修正Weights和biases的值使之更为合理
结构什么的都构建好了我们就可以开始核心部分了:
sess = tf.Session()
init = tf.global_variables_initializer() #very important if you define Variable
sess.run(init)
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(Weights), sess.run(biases))
首先开启一个Session会话,习惯上用sess = tf.Session() 用sess简化tf.Session()。
请记住程序中定义了Variable的话呢我们必须初始化它 Weights 和 biases 为 Variable变量
在window下使用tensorflow的初始化语句为tf.global_variables_initializer()
在linux下使用tensorflow的初始化语句为tf.initialize_all_variable()
初始化变量以后就开始运行这些定义的变量,要通过Session会话里面的run()函数。
我们可以假设学习200次(你可以用for循环定义任何你喜欢的次数),每次学习的内容其实就是减小误差也就是每次都运行我们定义的train方法。
然后每隔20次输出一次我们变量Weights和biases的值,值得注意的是输出的时候也要通过Session会话来运行这两个Variable 从而显示此时Weights和biases的值 也就是我们最开始说的y = ax +b 中 a 和 b 的值
可以从结果看到 Weights的值为0.099999 biases的值为0.30000007 都是非常接近于0.1 和0.3 的值的,这代表什么呢?学习成果啦~~^_^
最后请谅解:
我是第一次写这样的文章,好吧是第一次写文章,有不对的地方或者大家不清楚的地方我们可以一起探讨!
然后有些地方其实解释的也不是很详细(一些函数的用法这篇文章没有细讲)因为我最近在做c#的一个项目所以没有时间和大家一起学习和探讨一些tensorflow基础的函数,等过段时间我会完善一些函数的解释还有就是和大家一起学习一些好玩儿的东西。
最后希望大家都能互相帮助互相进步 ^_^。
tensorflow让程序学习到函数y = ax + b中a和b的值的更多相关文章
- C运行时库(C Run-time Library)详解(提供的另一个最重要的功能是为应用程序添加启动函数。Visual C++对控制台程序默认使用单线程的静态链接库,而MFC中的CFile类已暗藏了多线程)
一.什么是C运行时库 1)C运行时库就是 C run-time library,是 C 而非 C++ 语言世界的概念:取这个名字就是因为你的 C 程序运行时需要这些库中的函数. 2)C 语言是所谓的“ ...
- 90、Tensorflow实现分布式学习,多台电脑,多个GPU 异步试学习
''' Created on 2017年5月28日 @author: weizhen ''' import time import tensorflow as tf from tensorflow.e ...
- MySql学习(四) —— 函数、视图
注:该MySql系列博客仅为个人学习笔记. 本篇博客主要涉及MySql 函数(数学函数.字符串函数.日期时间函数.流程控制函数等),视图. 一.函数 1. 数学函数 对于数学函数,若发生错误,所有数学 ...
- [转] PostgreSQL学习手册(函数和操作符)
一.逻辑操作符: 常用的逻辑操作符有:AND.OR和NOT.其语义与其它编程语言中的逻辑操作符完全相同. 二.比较操作符: 下面是PostgreSQL中提供的比较操作符列表: 操作符 描述 < ...
- 从0开始的Python学习007函数&函数柯里化
简介 函数是可以重用的程序段.首先这段代码有一个名字,然后你可以在你的程序的任何地方使用这个名称来调用这个程序段.这个就是函数调用,在之前的学习中我们已经使用了很多的内置函数像type().range ...
- Windows下编译TensorFlow1.3 C++ library及创建一个简单的TensorFlow C++程序
由于最近比较忙,一直到假期才有空,因此将自己学到的知识进行分享.如果有不对的地方,请指出,谢谢!目前深度学习越来越火,学习.使用tensorflow的相关工作者也越来越多.最近在研究tensorflo ...
- TensorFlow和深度学习入门教程(TensorFlow and deep learning without a PhD)【转】
本文转载自:https://blog.csdn.net/xummgg/article/details/69214366 前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络,并把 ...
- TensorFlow和深度学习新手教程(TensorFlow and deep learning without a PhD)
前言 上月导师在组会上交我们用tensorflow写深度学习和卷积神经网络.并把其PPT的參考学习资料给了我们, 这是codelabs上的教程:<TensorFlow and deep lear ...
- python学习8—函数之高阶函数与内置函数
python学习8—函数之高阶函数与内置函数 1. 高阶函数 a. map()函数 对第二个输入的参数进行第一个输入的参数指定的操作.map()函数的返回值是一个迭代器,只可以迭代一次,迭代过后会被释 ...
随机推荐
- python全栈开发-Day5 元组、字典
python全栈开发-Day5 元组.字典 一.前言 首先,不管学习什么数据类型,我们都带着以下几个问题展开学习: #1:基本使用 1 .用途 2 .定义方式 3.常用操作+内置的方法 #2:该类型 ...
- PHP 简单的加密解密方法
本算法的基础:给定字符A B,A^B=C,C^B=A,即两次异或运算可得到原字符.实现代码如下: /** * @desc加密 * @param string $str 待加密字符串 * @param ...
- Java中调用文件中所有bat脚本
//调用外部脚本String fileips=null;//所有的路径String[] files=null;String fileip=null;//单个路径try { InputStream is ...
- SpringBoot工作机制
1:前言 回顾探索Spring框架 1.spring ioc IoC其实有两种方式,一种就是DI,而另一种是DL,即Dependency Lookup(依赖查找),前者是当前软件实体被动接受其依赖的其 ...
- RabbitMQ第四篇:Spring集成RabbitMQ
前面几篇讲解了如何使用rabbitMq,这一篇主要讲解spring集成rabbitmq. 首先引入配置文件org.springframework.amqp,如下 <dependency> ...
- V-bind详细使用
v-bind 主要用于属性绑定,Vue官方提供了一个简写方式 :bind,例如: <!-- 完整语法 --> <a v-bind:href="url">& ...
- bash下常用快捷键
Ctrl-A 相当于HOME键,用于将光标定位到本行最前面Ctrl-E 相当于End键,即将光标移动到本行末尾Ctrl-B 相当于左箭头键,用于将光标向左移动一格Ctrl-F 相当于右箭头键,用于将光 ...
- IntelliJIDEA中如何使用JavaDoc
IntelliJ IDEA 12.1.6,本身提供了很好的 JavaDoc 生成功能,以及标准 JavaDoc 注释转换功能,其实质是在代码编写过程中,按照标准 JavaDoc 的注释要求,为需要暴露 ...
- img之间的间隙问题
前言:关于基线(base line),中线(middle line),行高(line height)的了解还是比较浅的,所以引用前辈的成果,稍带解释下 1)行高:两行文字之间"基线" ...
- B-day5
1.昨天的困难,今天解决的进度,以及明天要做的事情 昨天的困难:昨天虽然完成了风险数据的图表统计,但是界面风格仍然不太满意,还在抓紧调试中:还有登录页的背景图,在想应该如何设计, 什么样的风格才好. ...