Spark学习之数据读取与保存总结(二)
8、Hadoop输入输出格式
除了 Spark 封装的格式之外,也可以与任何 Hadoop 支持的格式交互。Spark 支持新旧两套Hadoop 文件 API,提供了很大的灵活性。
要使用新版的 Hadoop API 读入一个文件,需要告诉 Spark 一些东西。 newAPIHadoopFile接收一个路径以及三个类。第一个类是“格式”类,代表输入格式。相似的函数hadoopFile() 则用于使用旧的 API 实现的 Hadoop 输入格式。第二个类是键的类,最后一个类是值的类。如果需要设定额外的 Hadoop 配置属性,也可以传入一个 conf 对象。
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("hadoop").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val inputFile = "pandainfo.json"//读取csv文件
// 新式API
val job = new Job()
val data = sc.newAPIHadoopFile("pandainfo.json", classOf[KeyValueTextInputFormat], classOf[Text], classOf[Text], job.getConfiguration)
data.foreach(println)
data.saveAsNewAPIHadoopFile("hadoop_json", classOf[Text], classOf[Text], classOf[TextOutputFormat[Text,Text]], job.getConfiguration)
// // 旧式API
// val input = sc.hadoopFile[Text,Text,KeyValueTextInputFormat](inputFile).map{
// case(x,y) => (x.toString,y.toString)
// }
// input.foreach(println)
} }

9、文件压缩
在大数据工作中,我们经常需要对数据进行压缩以节省存储空间和网络传输开销。对于大多数 Hadoop 输出格式来说,我们可以指定一种压缩编解码器来压缩数据。我们已经提过,Spark 原生的输入方式( textFile 和 sequenceFile )可以自动处理一些类型的压缩。在读取压缩后的数据时,一些压缩编解码器可以推测压缩类型。
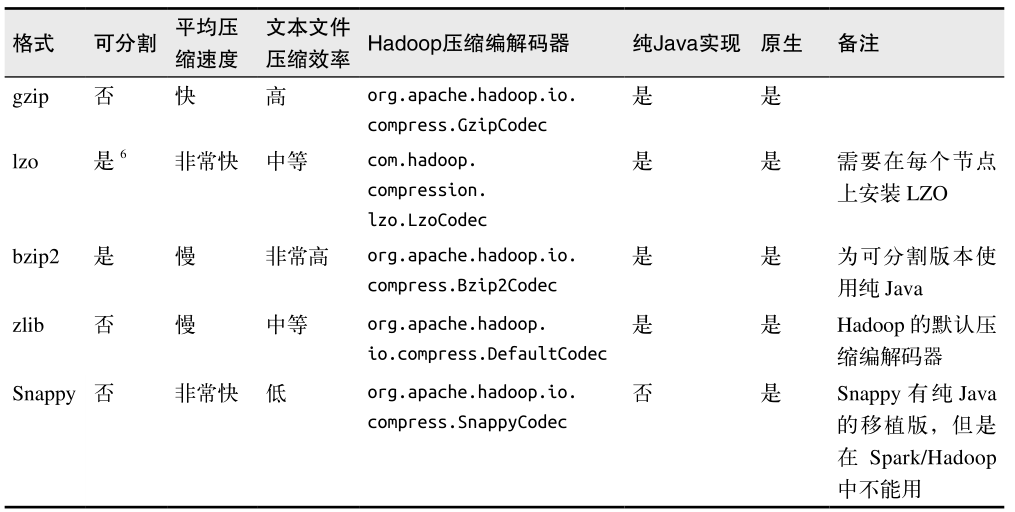
这些压缩选项只适用于支持压缩的 Hadoop 格式,也就是那些写出到文件系统的格式。写入数据库的 Hadoop 格式一般没有实现压缩支持。如果数据库中有压缩过的记录,那应该是数据库自己配置的。表列出了可用的压缩选项。
三、文件系统
Spark 支持读写很多种文件系统,可以使用任何我们想要的文件格式。
本地/“常规”文件系统:Spark 支持从本地文件系统中读取文件,不过它要求文件在集群中所有节点的相同路径下都可以找到。
Amazon S3:将一个以s3n://开头的路径以s3n://bucket/path-within-bucket的形式传给Spark的输入方法。
HDFS:在Spark中使用HDFS只需要将输入路径输出路径指定为hdfs://master:port/path就可以了。
四、Spark SQL中的结构化数据
1、Apache Hive
Apache Hive 是 Hadoop 上的一种常见的结构化数据源。Hive 可以在 HDFS 内或者在其他存储系统上存储多种格式的表。这些格式从普通文本到列式存储格式,应有尽有。SparkSQL 可以读取 Hive 支持的任何表。
要把 Spark SQL 连接到已有的 Hive 上,你需要提供 Hive 的配置文件。你需要将 hive-site.xml 文件复制到 Spark 的 ./conf/ 目录下。这样做好之后,再创建出 HiveContext 对象,也就是 Spark SQL 的入口,然后你就可以使用 Hive 查询语言(HQL)来对你的表进行查询,并以由行组成的 RDD 的形式拿到返回数据。
//用scala创建HiveContext并查询数据
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val hiveCtx = new HiveContext(sc)
val rows = hiveCtx.sql("SELECT name,age FROM users")
val firstRow = rows.first()
println(firstRow.getString(0)) // 字段0是name字段
2、JSON
如果你有记录间结构一致的 JSON 数据,Spark SQL 也可以自动推断出它们的结构信息,并将这些数据读取为记录,这样就可以使得提取字段的操作变得很简单。要读取 JSON 数据,首先需要和使用 Hive 一样创建一个 HiveContext 。(不过在这种情况下我们不需要安装好 Hive,也就是说你也不需要 hive-site.xml 文件。)然后使用 HiveContext.jsonFile 方法来从整个文件中获取由 Row 对象组成的 RDD。除了使用整个 Row 对象,你也可以将 RDD数据注册为一张表,然后从中选出特定的字段。例如:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.SQLContext object Test {
def main(args: Array[String]): Unit = {
// 再Scala中使用SparkSQL读取json数据
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val hiveCtx = new HiveContext(sc)
val input = hiveCtx.jsonFile("tweets.json")
input.registerTempTable("tweets")
val results = hiveCtx.sql("SELECT user.name,text FROM tweets")
results.collect().foreach(println)
} }

3、数据库
通过数据库提供的 Hadoop 连接器或者自定义的 Spark 连接器,Spark 可以访问一些常用的数据库系统。常见的有四种常见的连接器:Java数据库连接、Cassandra、HBase、Elasticsearch。下面演示如何使用 jdbcRDD 连接 MySQL 数据库。
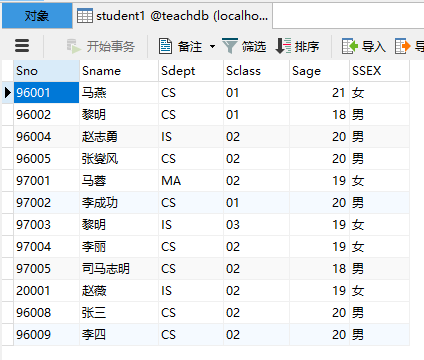
首先我们有一个名为teachdb的数据库,里面有一张名为student1的表,有如下数据:
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.SQLContext object Test {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("wordcount").setMaster("local")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN") // 设置日志显示级别
val sqlContext = new SQLContext(sc)
val mysql = sqlContext.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/teachdb")
.option("dbtable", "student1").option("driver", "com.mysql.jdbc.Driver") // 注意这儿需要导入"mysql-connector-java-5.1.40-bin"包
.option("user", "root").option("password", "0000").load()
mysql.registerTempTable("student1")
mysql.sqlContext.sql("select * from student1").collect().foreach(println)
} }
这篇博文主要来自《Spark快速大数据分析》这本书里面的第五章,内容有删减,还有本书的一些代码的实验结果。
Spark学习之数据读取与保存总结(二)的更多相关文章
- Spark学习之数据读取与保存(4)
Spark学习之数据读取与保存(4) 1. 文件格式 Spark对很多种文件格式的读取和保存方式都很简单. 如文本文件的非结构化的文件,如JSON的半结构化文件,如SequenceFile结构化文件. ...
- Spark学习之数据读取与保存总结(一)
一.动机 我们已经学了很多在 Spark 中对已分发的数据执行的操作.到目前为止,所展示的示例都是从本地集合或者普通文件中进行数据读取和保存的.但有时候,数据量可能大到无法放在一台机器中,这时就需要探 ...
- Spark学习笔记——数据读取和保存
spark所支持的文件格式 1.文本文件 在 Spark 中读写文本文件很容易. 当我们将一个文本文件读取为 RDD 时,输入的每一行 都会成为 RDD 的 一个元素. 也可以将多个完整的文本文件一次 ...
- 【原】Learning Spark (Python版) 学习笔记(二)----键值对、数据读取与保存、共享特性
本来应该上周更新的,结果碰上五一,懒癌发作,就推迟了 = =.以后还是要按时完成任务.废话不多说,第四章-第六章主要讲了三个内容:键值对.数据读取与保存与Spark的两个共享特性(累加器和广播变量). ...
- Spark学习笔记4:数据读取与保存
Spark对很多种文件格式的读取和保存方式都很简单.Spark会根据文件扩展名选择对应的处理方式. Spark支持的一些常见文件格式如下: 文本文件 使用文件路径作为参数调用SparkContext中 ...
- Spark基础:(四)Spark 数据读取与保存
1.文件格式 Spark对很多种文件格式的读取和保存方式都很简单. (1)文本文件 读取: 将一个文本文件读取为一个RDD时,输入的每一行都将成为RDD的一个元素. val input=sc.text ...
- Spark(十二)【SparkSql中数据读取和保存】
一. 读取和保存说明 SparkSQL提供了通用的保存数据和数据加载的方式,还提供了专用的方式 读取:通用和专用 保存 保存有四种模式: 默认: error : 输出目录存在就报错 append: 向 ...
- 【Spark机器学习速成宝典】基础篇03数据读取与保存(Python版)
目录 保存为文本文件:saveAsTextFile 保存为json:saveAsTextFile 保存为SequenceFile:saveAsSequenceFile 读取hive 保存为文本文件:s ...
- matlab各格式数据读取与保存函数
数据处理及matlab的初学者,可能最一开始接触的就是数据的读取与保存: %matlab数据保存与读入 function datepro clear all; %产生随机数据 mat = rand(, ...
随机推荐
- Redis+Django(Session,Cookie、Cache)的用户系统
转自 http://www.cnblogs.com/BeginMan/p/3890761.html 一.Django authentication django authentication 提供了一 ...
- RocketMQ源码 — 八、 RocketMQ消息重试
RocketMQ的消息重试包含了producer发送消息的重试和consumer消息消费的重试. producer发送消息重试 producer在发送消息的时候如果发送失败了,RocketMQ会自动重 ...
- 使用webpack打包vue工程
记得去年十月份的时候,自己在研究webpack,当时只是知道大致的用法,写了一个简单的demo,现在,经过了7个月对公司产品架构的使用,以及对vue-cli的使用,在了解了实际应用中各种需求之后,我自 ...
- 115个Java面试题和答案——终极列表(上)【转】
本文我们将要讨论Java面试中的各种不同类型的面试题,它们可以让雇主测试应聘者的Java和通用的面向对象编程的能力.下面的章节分为上下两篇,第一篇将要讨论面向对象编程和它的特点,关于Java和它的功能 ...
- 初学JSP
一. 基本了解 JSP是应用最广泛的表现层技术,它和Servlet是Java EE的两个基本成员.JSP和Servlet本质是一样的,因为JSP最终编译成ServLet才能运行. 1.1 we ...
- 关于ajax原理阐述
ajax是什么呢?说白了就是一个请求,一个读取服务器资源以及提交资源到服务器的中间处理机制,那它具体是怎样工作的,又有怎样的原理呢?var ajax=function(url,fnSucceed,fn ...
- Oracle12c中分区(Partition)新特性之TRUNCATEPARTITION和EXCHANGE PARTITION级联功能
TRUNCATE [SUB]PARTITION和EXCHANGE [SUB]PARTITION命令如今可以包括CASCADE子句,从而允许参照分区表向下级联这些操作.为确保该选项正常,相关外键也必须包 ...
- java ArrayList集合
ArrayList集合是程序中最常见的一种集合,它属于引用数据类型(类).在ArrayList内部封装了一个长度可变的数组,当存入的元素超过数组长度时,ArrayList会在内存中分配一个更大的数组来 ...
- 夜神模拟器链接Android studoid
在cmd 窗口输入:adb.exe connect 127.0.0.1:62001然后as就自动匹配了夜神经常忘记,特此提醒
- python+selenium实现登录账户
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Gr ...