EF查询之性能优化技巧
前言
EF相信大部分同学都已经经常使用了,可是你的查询高效吗?
今天我就以个人使用经验来讲讲在使用EF做查询的时候大家都容易忽略的性能提升点。
本文将继续接着上一篇(EF使用CodeFirst方式生成数据库&技巧经验)来写
数据准备
public ActionResult Index()
{
using (var db = new Core.EF.MyDbContext())
{ //添加测试数据
for (int i = ; i < ; i++)
{
Public_Area area1 = new Public_Area()
{
ID = Guid.NewGuid(),
Name = "上海"+i,
ParentID = Guid.NewGuid() };
db.Public_Area.Add(area1);
Public_Area area2 = new Public_Area()
{
ID = Guid.NewGuid(),
Name = "市区" + i,
ParentID = area1.ID };
db.Public_Area.Add(area2);
Public_Area area3 = new Public_Area()
{
ID = Guid.NewGuid(),
Name = "嘉定区" + i,
ParentID = area2.ID };
db.Public_Area.Add(area3); T_Classes classes = new T_Classes()
{
Name = "高中二班" + i,
Money =
};
db.T_Classes.Add(classes);
T_Student student = new T_Student()
{
ClassesID = classes.ID,
Name = "李四" + i,
Phone = "",
Sex = true,
ProvinceID = area1.ID,
CityID = area2.ID,
CountyID = area3.ID,
};
db.T_Student.Add(student);
db.SaveChanges(); } }
return View();
}
查询监视
EF生成的sql语句是什么样子的呢?我们有多种方式查看到。
- 通过SQL Server Profiler来监控执行的sql语句
- 使用插件MiniProfiler来监控执行的sql语句
测试代码:
var profiler = MiniProfiler.Current;
using (profiler.Step("查询第一条班级的数据数据"))
{
using (var db = new Core.EF.MyDbContext())
{
var classes= db.T_Classes.Where(c => true).FirstOrDefault(); }
}
测试结果如下:

延迟加载的开关
默认情况下延迟加载是开启的,我们可以通过如下两种方式设置是否开启延迟加载。
- 第一种在dbcontex中设置:
public MyDbContext(System.Data.Common.DbConnection oConnection)
: base(oConnection, true)
{
this.Configuration.LazyLoadingEnabled = true;
}
2.第二种在使用DbContext的时候设置:
using (var db = new Core.EF.MyDbContext())
{
db.Configuration.LazyLoadingEnabled = false;
var classes= db.T_Student.Where(c => true).FirstOrDefault();
int a = ;
}
延迟加载开启和关闭的结果测试
1.当关闭延迟加载的时候我们查不到对应表的关联表中的数据,如上,我们在查询学生表的数据时关闭了延迟加载,查询结果如下:
当我们不需要使用子表的数据时,我们可以选择关闭延迟加载
using (var db = new Core.EF.MyDbContext())
{
db.Configuration.LazyLoadingEnabled = false;
var classes= db.T_Student.Where(c => true).FirstOrDefault();
int a = ;
}

2.打开延迟加载,查询结果如下:
当我们需要使用子表数据时需要打开延迟加载
using (var db = new Core.EF.MyDbContext())
{
var classes= db.T_Student.Where(c => true).FirstOrDefault();
int a = ;
}

延迟加载时使用Include提高性能
使用Include的两大前提
- 开启延迟加载
- 在使用Include的类上using System.Data.Entity;
不使用Include的情况
代码:
var profiler = MiniProfiler.Current;
using (profiler.Step("查询第一条班级的数据数据"))
{
using (var db = new Core.EF.MyDbContext())
{
var students = db.T_Student.Where(c => true).Take().ToList();
foreach (var item in students)
{
var c = item.T_Classes;
}
int a = ;
}
}
结果:
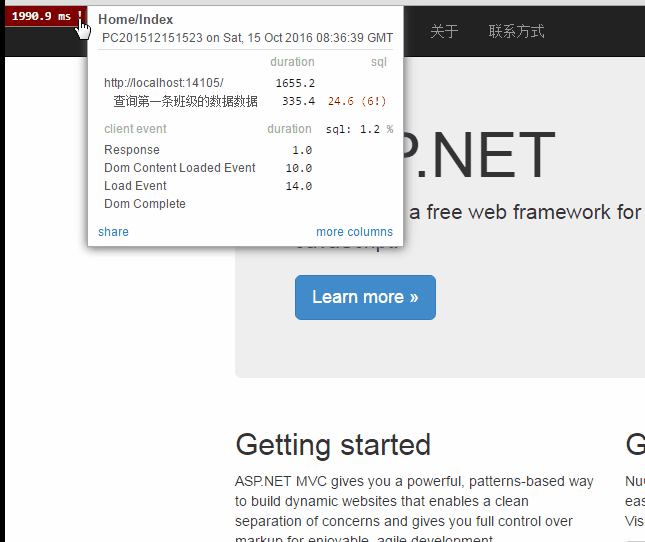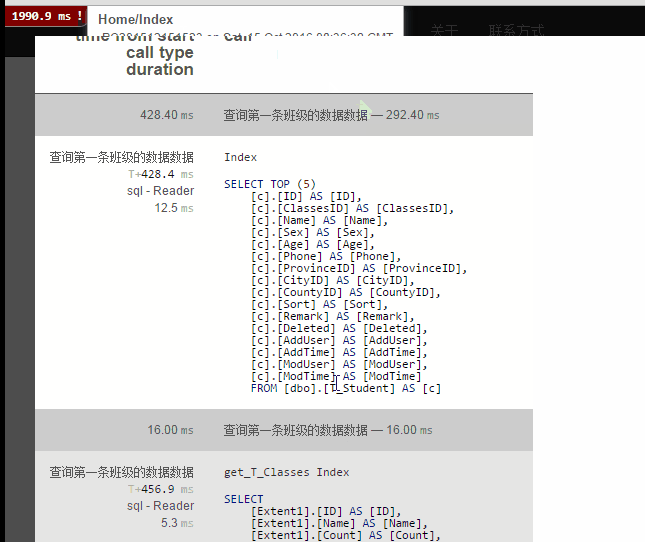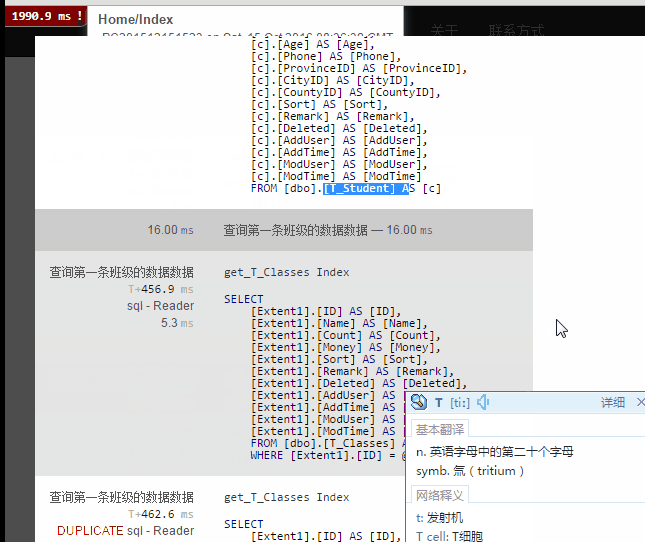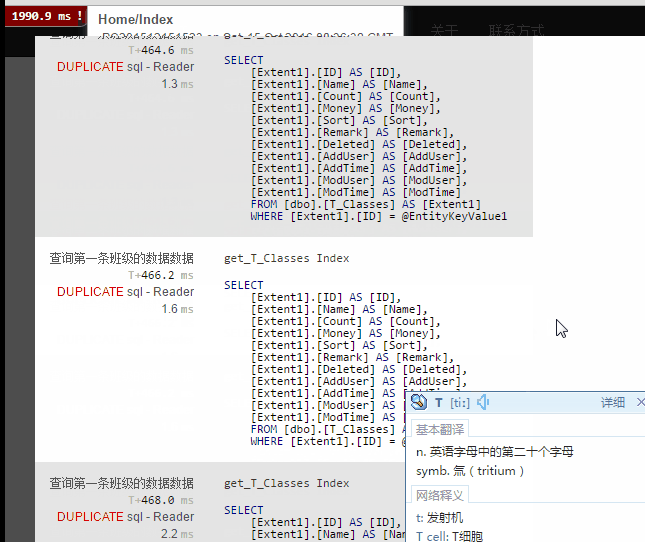
结论:我们发现一共查询了六次数据库。
使用Include的情况
代码:
var profiler = MiniProfiler.Current;
using (profiler.Step("查询第一条班级的数据数据"))
{
using (var db = new Core.EF.MyDbContext())
{
var students = db.T_Student.Where(c => true).Take().Include(c=>c.T_Classes).ToList();
foreach (var item in students)
{
var c = item.T_Classes;
}
int a = ;
}
}
结果:

结论:只查询了一次,将班级和学生表进行了连表查询
AsNoTracking提高查询性能
AsNoTracking的作用就是在查询的时候不做追踪,这样会查询的更快,但是这样做会有一个缺陷(不能对查询的数据做修改操作)。
测试代码如下:
var profiler = MiniProfiler.Current;
using (profiler.Step("查询数据"))
{
using (var db = new Core.EF.MyDbContext())
{
var student1 = db.T_Student.Where(c => c.Name== "李四50").Take().ToList();
var student2 = db.T_Student.Where(c => c.Name == "李四50").Take().AsNoTracking().ToList(); }
}
测试结果如下:

多字段排序
先按name升序,再按age升序。
错误的写法:age的排序会把name的排序冲掉
var student2 = db.T_Student.Where(c => c.Name == "李四50").OrderBy(c=>c.Name).OrderBy(c=>c.Age).AsNoTracking().ToList();
正确的写法:
var student2 = db.T_Student.Where(c => c.Name == "李四50").OrderBy(c=>c.Name).ThenBy(c=>c.Age).AsNoTracking().ToList();
EF中使用sql
在实际开发中,对于比较复杂的查询,或者存储过程的使用就不得不使用原生的sql语句来操作数据库。其实EF已经给我们预留好了sql语句查询的接口,代码如下:
db.Database.SqlQuery<T>("sql","parameters")
这种写法还支持将sql语句查询的结果集(DataSet或者DataTable)直接转换成对应的强类型集合(List<T>)。
特别需要注意的地方:
如果使用db.Database.SqlQuery<T>("sql语句")进行分页查询的话,要注意避免内存分页。
错误的写法:内存分页
db.Database.SqlQuery<T>("select * from table").OrderByDescending(c => c.CreateTime).Skip(pageSize * (pageIndex - )).Take(pageSize).ToList();
这种写法会导致在内存中分页。
正确的写法:
string sql="select * from table";
string orderBy="CreateTime desc";
int pageSize=;
int pageIndex=;
StringBuilder sb = new StringBuilder();
sb.Append(string.Format(@"select * from
(
select *, row_number() over (order by {0} ) as row from
(
", orderBy));
sb.Append(sql);
sb.Append(@"
)as t
)
as s
where s.row between " + (pageIndex * pageSize - pageSize + ) + " and " + (pageIndex * pageSize));
var list = db.Database.SqlQuery<T>(sb.ToString()).ToList();
存在性之Any
在实际开发中,我们经常会遇到这样的需求:判断某个表是否包含字段=xx的记录。下面我们就看看这种需求用EF一共有多少种写法,以及每种写法的性能怎么样。
代码如下:
var profiler = MiniProfiler.Current;
using (profiler.Step("查询数据"))
{
using (var db = new Core.EF.MyDbContext())
{
//测试班级表中是否包含‘高中二班4’
bool a = db.T_Classes.Where(c => c.Name == "高中二班4").Count() > ;
bool b = db.T_Classes.Count(c => c.Name == "高中二班4") > ;
bool e = db.T_Classes.Where(c => c.Name == "高中二班4").FirstOrDefault() != null;
bool d = db.T_Classes.Any(c => c.Name == "高中二班4");
}
}
到目前为止我一共整理了如上四种写发。
生成的查询语句及耗时如下。
第一次刷新页面结果如下:

第二次刷新页面结果如下:

结论:我们可以看到第一种写法和第二种写法生成的sql语句是一样的,第三种写法和第四种写法的耗时明显比第一种写法少。
多表查询
等值连接的写法
代码如下:
using (var db = new Core.EF.MyDbContext())
{
//等值连接Lambda写法
var result1 = db.T_Classes.Where(t=>t.Money==).Join(db.T_Student, c => c.ID, s => s.ClassesID, (c, s) => new {
CName=c.Name,
SName=s.Name
}).ToList();
//等值连接Linq写法
var result2 = (from c in db.T_Classes
join s in db.T_Student
on c.ID equals s.ClassesID
where c.Money==
select new
{
CName = c.Name,
SName = s.Name
}).ToList();
}
生成的sql语句如下:我们可以看出两种写法生成的sql语句是一样的
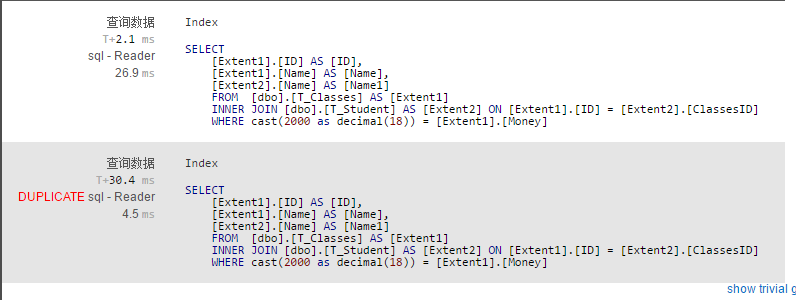
左(右)连接的写法
代码如下:
//左外连接的写法
var result3 = (from c in db.T_Classes.Where(a=>a.Money==)
join s in db.T_Student on c.ID equals s.ClassesID into temp //临时表
from t in temp.DefaultIfEmpty()
select new
{
CName = c.Name,
SName = t.Name
}).ToList();
生成的sql语句如下:

分页查询封装
工欲善其事必先利其器,简单的查询语句我们可以直接通过db.xx.where().ToList()的方式来实现。
如果是复杂的查询呢,比如分页查询,这时候我们不但要返回分页数据,还要返回总页数总记录数,这个时候对查询进行封装就显得很重要了。
分页类代码:
using System;
using System.Collections.Generic;
using System.Data;
using System.Data.Common;
using System.Data.Entity;
using System.Data.SqlClient;
using System.Linq;
using System.Linq.Expressions;
using System.Text;
using System.Threading.Tasks; namespace EFDemo.Core.EF
{
public static class Repository
{
public static EntityList<TEntity> GetPagedEntitys<TEntity, Sort>(DbContext db, int pageIndex, int pageSize, Expression<Func<TEntity, bool>> whereLambds, bool isAsc, Expression<Func<TEntity, Sort>> orderByLambds) where TEntity : class, new()
{
var temp = db.Set<TEntity>().Where<TEntity>(whereLambds);
var rows = temp.Count();
var totalPage = rows % pageSize == ? rows / pageSize : rows / pageSize + ;
temp = isAsc ? temp.OrderBy<TEntity, Sort>(orderByLambds) : temp.OrderByDescending<TEntity, Sort>(orderByLambds);
temp = temp.Skip<TEntity>(pageSize * (pageIndex - )).Take<TEntity>(pageSize); var list = temp.ToList<TEntity>();
var dataList = Activator.CreateInstance(typeof(EntityList<TEntity>)) as EntityList<TEntity>;
dataList.List = list;
dataList.TotalRows = rows;
dataList.TotalPages = totalPage;
return dataList;
} public static EntityList<TEntity> GetPagedEntitys<TEntity, Sort1, Sort2>(DbContext db, int pageIndex, int pageSize, Expression<Func<TEntity, bool>> whereLambds, bool isAsc1, Expression<Func<TEntity, Sort1>> orderByLambd1, bool isAsc2, Expression<Func<TEntity, Sort2>> orderByLambd2) where TEntity : class, new()
{
var temp = db.Set<TEntity>().Where<TEntity>(whereLambds);
var rows = temp.Count();
var totalPage = rows % pageSize == ? rows / pageSize : rows / pageSize + ; IOrderedQueryable<TEntity> temp1 = isAsc1 ? temp.OrderBy<TEntity, Sort1>(orderByLambd1) : temp.OrderByDescending<TEntity, Sort1>(orderByLambd1);
temp1 = isAsc2 ? temp1.ThenBy<TEntity, Sort2>(orderByLambd2) : temp1.ThenByDescending<TEntity, Sort2>(orderByLambd2); var temp2 = temp1.AsQueryable<TEntity>().Skip<TEntity>(pageSize * (pageIndex - )).Take<TEntity>(pageSize); var list = temp2.ToList<TEntity>();
var dataList = Activator.CreateInstance(typeof(EntityList<TEntity>)) as EntityList<TEntity>;
dataList.List = list;
dataList.TotalRows = rows;
dataList.TotalPages = totalPage;
return dataList;
} //拼接sqlWhere返回单表分页Entity数据,paramss格式为 p={0}
public static EntityList<TEntity> GetPagedEntitysBySqlWhere<TEntity>(DbContext db, int pageIndex, int pageSize, string where, string orderKey, params object[] paramss) where TEntity : class, new()
{ string sqls = "";
string tableName = typeof(TEntity).Name;//获取表名
string sql = string.Format("select *, row_number() over (order by {0} ) as row_number from {1}", string.IsNullOrEmpty(orderKey) ? "Id" : orderKey, tableName);
string where1 = !string.IsNullOrEmpty(where) ? " where 1=1 " + where : "";
int tag = (pageIndex - ) * pageSize;
sqls = string.Format(@"select top ({0}) * from
(
{1}
{2}
) as t
where t.row_number > {3}", pageSize, sql, where1, tag); //获取数据
var list = db.Database.SqlQuery<TEntity>(sqls, paramss).ToList<TEntity>(); //通过自定义的class R 取得总页码数和记录数
string sqlCount = string.Format("select count(1) as Rows from {0} {1}", tableName, where1);
var rows = (int)db.Database.SqlQuery<int>(sqlCount, paramss).ToList()[];
var totalPage = rows % pageSize == ? rows / pageSize : rows / pageSize + ; var dataList = Activator.CreateInstance(typeof(EntityList<TEntity>)) as EntityList<TEntity>;
dataList.List = list;
dataList.TotalRows = rows;
dataList.TotalPages = totalPage;
return dataList;
}
//ADO.net方式返回连表查询Table数据
public static TableList GetPagedTable(DbContext db, int pageIndex, int pageSize, string sql, string orderKey, params SqlParameter[] paramss)
{ StringBuilder sb = new StringBuilder();
sb.Append(string.Format(@"select * from
(
select *, row_number() over (order by {0} ) as row from
(
", orderKey));
sb.Append(sql);
sb.Append(@"
)as t
)
as s
where s.row between " + (pageIndex * pageSize - pageSize + ) + " and " + (pageIndex * pageSize)); sb.Append(";select count(1)from(" + sql + ") as t;");
var con = db.Database.Connection as SqlConnection;
using (SqlCommand cmd = new SqlCommand())
{
cmd.Connection = con;
cmd.CommandText = sb.ToString();
cmd.Parameters.AddRange(paramss);
DbDataAdapter adapter = new SqlDataAdapter(cmd);
DataSet ds = new DataSet();
adapter.Fill(ds);
var rows = Convert.ToInt32(ds.Tables[].Rows[][]);
var totalPage = rows % pageSize == ? rows / pageSize : rows / pageSize + ;
cmd.Parameters.Clear();
var tableList = Activator.CreateInstance(typeof(TableList)) as TableList;
tableList.DataTable = ds.Tables[];
tableList.TotalRows = rows;
tableList.TotalPages = totalPage;
return tableList;
}
} }
}
返回类代码:
public class EntityList<TEntity> where TEntity : class, new()
{
public int TotalRows { get; set; }
public int TotalPages { get; set; }
public List<TEntity> List { get; set; }
}
public class TableList
{ public int TotalRows { get; set; }
public int TotalPages { get; set; }
public DataTable DataTable { get; set; }
}
测试使用代码:
//单条件排序
var r1= Repository.GetPagedEntitys<T_Classes, int>(db, , , c => c.Deleted == false, false, c => c.ID);
//多条件排序
var r2 = Repository.GetPagedEntitys<T_Classes, int,bool>(db, , , c => c.Deleted == false, false, c => c.ID, true, c =>c.Deleted);
//sql查询转强类型
var r3 = Repository.GetPagedEntitysBySqlWhere<T_Classes>(db, , , "and Deleted=0", "ID DESC");
//纯sql操作
var r4 = Repository.GetPagedTable(db, , , "select * from T_Classes where Deleted=0", "ID DESC");
项目位置:
Expressions扩展(强烈推荐)
在我们做项目的时候,带查询和分页的数据列表展示页是经常用的一个页面。
如下发货单界面所示:我们需要根据很多条件筛选把查询结果显示出来

经过分页的封装我们已经可以很方便的搞定数据列表的分页查询了。
现在我们又遇到了另一个问题,那就是条件的拼接(当满足某个固定条件时才把对应的条件拼接出来)
原始的写法如下:
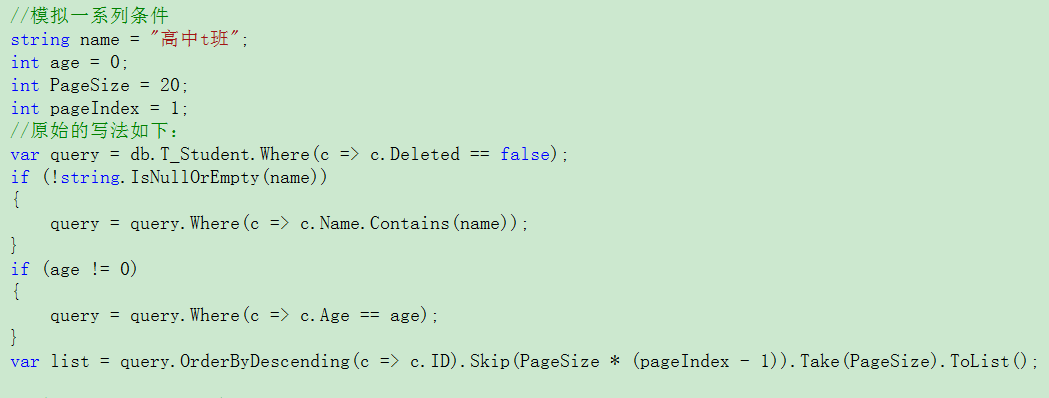
无法和封装的分页类进行集成,返回的数据只有列表集合,没有总页数和总记录数。
对Linq.Expressions进行扩展
扩展代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Linq.Expressions;
using System.Text;
using System.Threading.Tasks; namespace System.Linq.Expressions//注意命名空间
{
public static partial class ExtLinq
{ public static Expression<Func<T, bool>> True<T>() { return param => true; }
public static Expression<Func<T, bool>> False<T>() { return param => false; }
public static Expression<Func<T, bool>> And<T>(this Expression<Func<T, bool>> first, Expression<Func<T, bool>> second)
{
return first.Compose(second, Expression.AndAlso);
}
public static Expression<Func<T, bool>> Or<T>(this Expression<Func<T, bool>> first, Expression<Func<T, bool>> second)
{
return first.Compose(second, Expression.OrElse);
}
private static Expression<T> Compose<T>(this Expression<T> first, Expression<T> second, Func<Expression, Expression, Expression> merge)
{
var map = first.Parameters
.Select((f, i) => new { f, s = second.Parameters[i] })
.ToDictionary(p => p.s, p => p.f);
var secondBody = ParameterRebinder.ReplaceParameters(map, second.Body);
return Expression.Lambda<T>(merge(first.Body, secondBody), first.Parameters);
}
private class ParameterRebinder : ExpressionVisitor
{
readonly Dictionary<ParameterExpression, ParameterExpression> map;
/// <summary>
/// Initializes a new instance of the <see cref="ParameterRebinder"/> class.
/// </summary>
/// <param name="map">The map.</param>
ParameterRebinder(Dictionary<ParameterExpression, ParameterExpression> map)
{
this.map = map ?? new Dictionary<ParameterExpression, ParameterExpression>();
}
/// <summary>
/// Replaces the parameters.
/// </summary>
/// <param name="map">The map.</param>
/// <param name="exp">The exp.</param>
/// <returns>Expression</returns>
public static Expression ReplaceParameters(Dictionary<ParameterExpression, ParameterExpression> map, Expression exp)
{
return new ParameterRebinder(map).Visit(exp);
}
protected override Expression VisitParameter(ParameterExpression p)
{
ParameterExpression replacement; if (map.TryGetValue(p, out replacement))
{
p = replacement;
}
return base.VisitParameter(p);
}
}
}
}
多条件查询+分页的极速简单写法(强烈推荐写法):

结合分页的封装,很简单的就可以实现多条件查询+分页
EF预热
使用过EF的都知道针对所有表的第一次查询都很慢,而同一个查询查询过一次后就会变得很快了。
假设场景:当我们的查询编译发布部署到服务器上时,第一个访问网站的的人会感觉到页面加载的十分缓慢,这就带来了很不好的用户体验。
解决方案:在网站初始化时将数据表遍历一遍
在Global文件的Application_Start方法中添加如下代码:
using (var dbcontext = new MyDbContext())
{
var objectContext = ((IObjectContextAdapter)dbcontext).ObjectContext;
var mappingCollection = (StorageMappingItemCollection)objectContext.MetadataWorkspace.GetItemCollection(DataSpace.CSSpace);
mappingCollection.GenerateViews(new List<EdmSchemaError>());
}
Demo完整代码下载
EF查询之性能优化技巧的更多相关文章
- MySQL 性能优化技巧
原文地址:MySQL 性能优化技巧 博客地址:http://www.extlight.com 一.背景 最近公司项目添加新功能,上线后发现有些功能的列表查询时间很久.原因是新功能用到旧功能的接口,而这 ...
- JavaScript 如何工作:渲染引擎和性能优化技巧
翻译自:How JavaScript works: the rendering engine and tips to optimize its performance 这是探索 JavaScript ...
- SQLSERVER SQL性能优化技巧
这篇文章主要介绍了SQLSERVER SQL性能优化技巧,需要的朋友可以参考下 1.选择最有效率的表名顺序(只在基于规则的优化器中有效) SQLSERVER的解析器按照从右到左的顺序处理F ...
- Oracle SQL 性能优化技巧
Select语句完整的执行顺序: SQL Select语句完整的执行顺序: 1. from子句组装来自不同数据源的数据: 2.where子句基于指定的条件对记录行进行筛选: 3.group by子句将 ...
- SQL性能优化技巧
作者:IT王小二 博客:https://itwxe.com 这里就给小伙伴们带来工作中常用的一些 SQL 性能优化技巧总结,包括常见优化十经验.order by 与 group by 优化.分页查询优 ...
- Java程序性能优化技巧
Java程序性能优化技巧 多线程.集合.网络编程.内存优化.缓冲..spring.设计模式.软件工程.编程思想 1.生成对象时,合理分配空间和大小new ArrayList(100); 2.优化for ...
- Python代码性能优化技巧
摘要:代码优化能够让程序运行更快,可以提高程序的执行效率等,对于一名软件开发人员来说,如何优化代码,从哪里入手进行优化?这些都是他们十分关心的问题.本文着重讲了如何优化Python代码,看完一定会让你 ...
- Python 代码性能优化技巧(转)
原文:Python 代码性能优化技巧 Python 代码优化常见技巧 代码优化能够让程序运行更快,它是在不改变程序运行结果的情况下使得程序的运行效率更高,根据 80/20 原则,实现程序的重构.优化. ...
- Python 代码性能优化技巧
选择了脚本语言就要忍受其速度,这句话在某种程度上说明了 python 作为脚本的一个不足之处,那就是执行效率和性能不够理想,特别是在 performance 较差的机器上,因此有必要进行一定的代码优化 ...
随机推荐
- 简单实用的进度条加载组件loader.js
本文提供一个简单的方法实现一个流程的进度条加载效果,以便在页面中可以通过它来更好地反馈耗时任务的完成进度.要实现这个功能,首先要考虑怎样实现一个静态的进度条效果,类似下面这样的: 这个倒是比较简单,两 ...
- 导出BOM表
1.Report->Bill of Materials for Project 将Value拖上左上角的Grouped Columns 2.在Excel表中全选器件,右键设置"设置单元 ...
- const 与 readonly知多少
原文地址: http://www.cnblogs.com/royenhome/archive/2010/05/22/1741592.html 尽管你写了很多年的C#的代码,但是可能当别人问到你cons ...
- spring源码:web容器启动(li)
web项目中可以集成spring的ApplicationContext进行bean的管理,这样使用起来bean更加便捷,能够利用到很多spring的特性.我们比较常用的web容器有jetty,tomc ...
- 《连载 | 物联网框架ServerSuperIO教程》- 5.轮询通讯模式开发及注意事项。附:网友制作的类库说明(CHM)
1.C#跨平台物联网通讯框架ServerSuperIO(SSIO)介绍 <连载 | 物联网框架ServerSuperIO教程>1.4种通讯模式机制. <连载 | 物联网框架Serve ...
- JDBC关于时间的存取
Oracle数据库默认时间存储是java.sql.date,而java程序中的时间默认是java.util.date,所以通过JDBC存取的 时候会涉及到时间的转换问题. 1.日期存取 存入数据库的时 ...
- 基于Nuclear的Web组件-Todo的十一种写法
刀耕火种 刀耕火种是新石器时代残留的农业经营方式.又称迁移农业,为原始生荒耕作制. var TodoApp = Nuclear.create({ add: function (evt) { evt.p ...
- JVM之上的语言小集
1 JVM上的编程语言https://en.wikipedia.org/wiki/List_of_JVM_languages主要的有:Clojure, a functional Lisp dialec ...
- Android Weekly Notes Issue #219
Android Weekly Issue #219 August 21st, 2016 Android Weekly Issue #219 ARTICLES & TUTORIALS Andro ...
- JSPatch来更新已上线的App中出现的BUG(超级详细)
JSPatch的作用是什么呢? 简单来说:(后面有具体的操作步骤以及在操作过程中会出现的错误) 1.iOS应用程序上架到AppStore需要等待苹果公司的审核,一般审核时间需要1到2周.虽然程序在上架 ...