在Visual Studio中使用Debug Visualizers在C++中实现对原始类的自定义调试信息显示
在Visual Studio中使用Debug Visualizers在C++中实现对原始类的自定义调试信息显示
当我们在VS的C++中使用vector、list、map等这些STL容器,在开启调试的时候可以看到这样的信息:
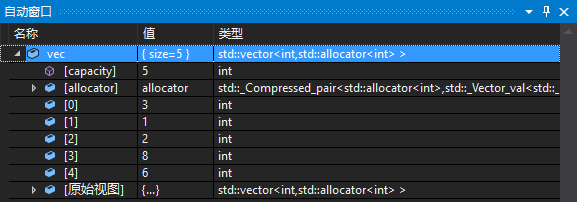
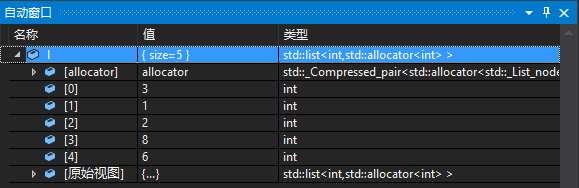
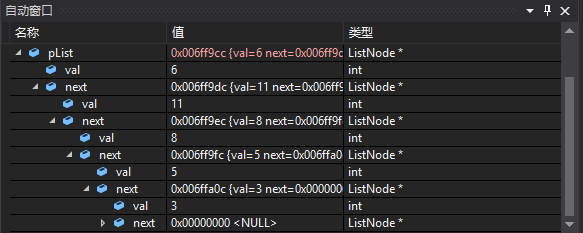
然而在我们自己手写链表,调试的时候却要像这样一级一级展开,很是麻烦。
有时候会想,如果要能像STL里面的list那样子直接显示出来就方便许多。经过几番寻找,终于被我找到了方法。
使用 .natvis 文件
.natvis文件使用了xml格式来进行扩展,在%VSINSTALLDIR%\Common7\Packages\Debugger\Visualizers路径中,stl.nativs文件包含了C++中几乎所有常用类的自定义调试信息,可以去翻阅里面的一些常用类来学习使用,原理也不是很复杂。
你可以自行编写一个.natvis的文件,但是需要将该文件放到以下两个路径之一:
%VSINSTALLDIR%\Common7\Packages\Debugger\Visualizers(需求管理员权限)
%USERPROFILE%\My Documents\Visual Studio 2017\Visualizers(若不存在Visualizers文件夹可自行新建一个)
该文件的编写有一个好处:你可以保持VS在调试状态,然后实时去修改.natvis文件。当你保存的时候,就会立即作用于调试窗口。而如果编写出现语法错误的话,则调试器会以原始的形式显示(或者找到另一个可用的显示)。
在你想要开始尝试编写该种格式的文件前,可以先在工具--选项--调试--输出窗口--Natvis诊断信息(仅限C++)选择为详细,这样在保存.natvis没得到理想结果后在输出窗口可以看到错误消息,不需要的时候再关掉即可。
新建一个 .natvis 文件
在项目中右键添加新建项,选择Visual C++中的实用工具,找到调试器可视化文件,然后修改新建位置到上述两个路径之一。
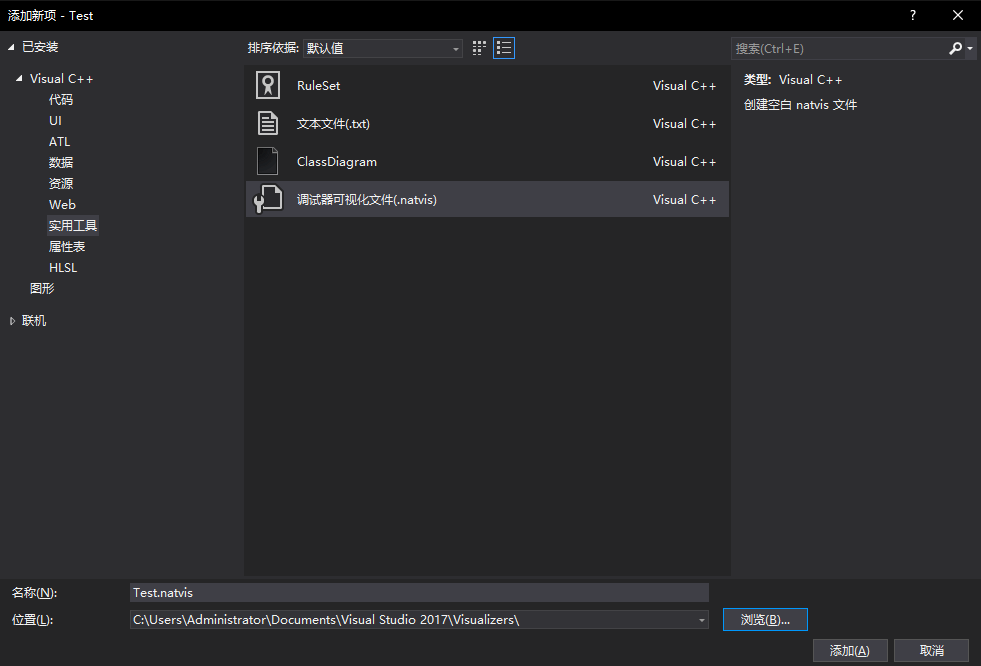
新建好后,就可以看到它默认生成的代码。
这篇博文并不打算从繁杂的语法开始讲起,而是直接以各种实例来进行说明。而且在输入这些代码的时候会有代码补全和功能提示,可以自己多动手尝试。有兴趣的话可以去参考文章末尾的链接。
自定义数组结构体/类
现在有一个简易的数组结构体:
typedef struct Array
{
int *data;
int size;
} Array;
又或者是个类:
class Array
{
//...
private:
int *data;
int size;
};
然后对应的.natvis格式文件如下:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="Array">
<DisplayString> {{ size = {size} }}</DisplayString>
<Expand>
<Item Name="[size]">size</Item>
<ArrayItems>
<Size>size</Size>
<ValuePointer>data</ValuePointer>
</ArrayItems>
</Expand>
</Type>
</AutoVisualizer>
最终的显示效果如下:
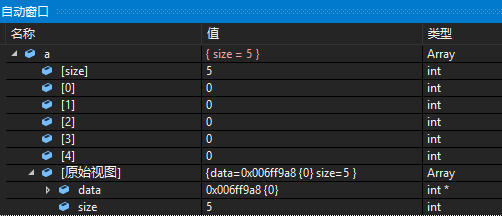
当Array为class的时候上述文件也是有效的。
其中,Type Name指定了需要可视化的类型名。
在DisplayString中的内容指定了该变量在值这一列中需要显示的内容,{{}}两对大括号使得在调试器中输出{},而{}单对大括号用于引用变量内的成员。
Expand用于指定变量展开时需要显示的项,其中显示的原始视图对应未使用Debug Visualizers的情况。
Item可以指定需要添加可视化输出的成员项,这里可以指定Name的字符串来决定在名称这一列显示什么,而中间的size则是指定了需要显示的成员的值(这里不需要加任何别的修饰)。
ArrayItems说明需要显示的数据类型是连续内存的数组,在内部的Size指定了需要显示的数目,这里绑定到成员size,而ValuePointer则需要绑定数组首元素的指针。
当你需要将一维数组当多维数组来使用,或者使用定容的多维数组(如int[2][3])时,可以添加指定数组的秩信息。以一维扩展成二维为例:
struct Matrix
{
//...
int *mat; // 矩阵
int dimen[2]; // 两个维度对应的大小
};
对应的.natvis文件格式如下:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="Matrix">
<DisplayString> {{ row = {dimen[0]}, column = {dimen[1]} }}</DisplayString>
<Expand>
<Item Name="[row]">dimen[0]</Item>
<Item Name="[col]">dimen[1]</Item>
<ArrayItems>
<Direction>Forward</Direction>
<Rank>2</Rank>
<Size>dimen[$i]</Size>
<ValuePointer>mat</ValuePointer>
</ArrayItems>
</Expand>
</Type>
</AutoVisualizer>
最终调试窗口效果如下:
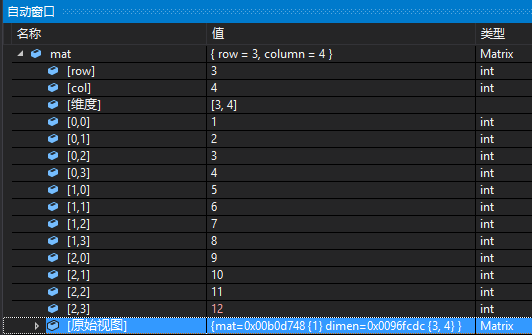
其中,Direction决定了如何展开多维数组的索引,Forward采用行优先展开,Backward采用列优先展开。
Rank指定了矩阵的维度。
Size中使用了$i作为循环遍历用的索引,需要在原结构体中有一个数组存储每一维度下的大小,然后在Size中指定该数组。
ValuePointer中如果指向的数组不是一维的,则需要在.natvis文件中写成 (T*)data的形式。
自定义非连续内存的数组结构体/类
该节适用于那些使用指针数组、多级指针的多维数组,特点都是数组在内存上是非连续的。但使用该项的缺点是仅可以一维展开显示,不能像上面那样多维显示。参考下面的类:
template<class T>
class Table
{
//...
private:
T** data;
int col;
int row;
};
对应的.natvis文件格式如下(对于字符串中的左、右尖括号请用对应的转义字符替代):
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="Table<*>">
<DisplayString> {{ row = {row}, column = {col} }}</DisplayString>
<Expand>
<Item Name="[row]">row</Item>
<Item Name="[col]">col</Item>
<IndexListItems>
<Size>row * col</Size>
<ValueNode>data[$i / col][$i % col]</ValueNode>
</IndexListItems>
</Expand>
</Type>
</AutoVisualizer>
显示效果如下:
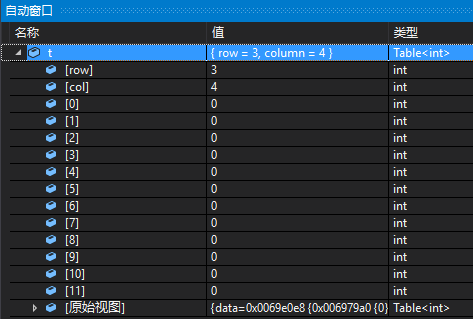
在Type Name这里第一次用到了类模板,为了能够让我们的类型名能够适配所有类型,需要用到通配符*来匹配任意数目的字符。
注意:Table<*>的左右尖括号是其XML对应的转义字符,而不是直接输入<>。
由于IndexListItems仅能指定Size和ValueNode两个类型,因此它所能做的事情还是非常有限的。
其中Size指定了元素总数目。
注意到ValueNode在这里一定要显式指定$i以循环遍历输出的对应元素,这里采用的是行优先展开的形式来输出的。
自定义链表
现有自定义的链表结构体如下:
struct ListNode
{
//...
int val;
ListNode *next;
};
struct List
{
//...
ListNode* head;
int size;
};
对应的.natvis文件格式如下:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="List">
<DisplayString> {{ size = {size} }}</DisplayString>
<Expand>
<Item Name="[size]">size</Item>
<LinkedListItems Condition="size > 0">
<Size>size</Size>
<HeadPointer>head</HeadPointer>
<NextPointer>next</NextPointer>
<ValueNode>val</ValueNode>
</LinkedListItems>
</Expand>
</Type>
</AutoVisualizer>
最终显示的效果如下:
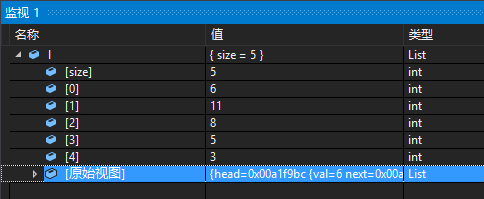
这里用到的类型为LinkedListItems,在后面还添加了Condition作为显示的条件,字符串的内容即为需要判别的表达式。当表达式为true时,才会显示该项内容。
Size指定了链表的元素数目,这样调试器就会根据该项显示指定数目的元素。若这里没有指定Size,则调试器会自动对链表进行推导直到遇到空指针结束。通常指定大小的话可以提高调试程序的性能。
HeadPointer指定要用到的头结点指针
NextPointer指定头结点中的next指针
ValueNode指定结点中的值成员
自定义二叉排序树
由于调试输出是按照中序遍历的形式进行的,一般来说常用在二叉排序树上(如map和set等),当然也可以是带指向parent的三叉树。如果你想要直接用普通的二叉树的话也是可以的。现在有如下结构体/类:
struct TreeNode
{
//...
TreeNode* leftChild;
TreeNode* rightChild;
int val;
};
class BSTree
{
//...
private:
TreeNode* root;
int size;
};
对应的.natvis文件代码如下:
<?xml version="1.0" encoding="utf-8"?>
<AutoVisualizer xmlns="http://schemas.microsoft.com/vstudio/debugger/natvis/2010">
<Type Name="BSTree">
<DisplayString> {{ size = {size} }}</DisplayString>
<Expand>
<Item Name="[size]">size</Item>
<TreeItems Condition="size > 0">
<Size>size</Size>
<HeadPointer>root</HeadPointer>
<LeftPointer>leftChild</LeftPointer>
<RightPointer>rightChild</RightPointer>
<ValueNode>val</ValueNode>
</TreeItems>
</Expand>
</Type>
</AutoVisualizer>
最终调试输出效果如下:
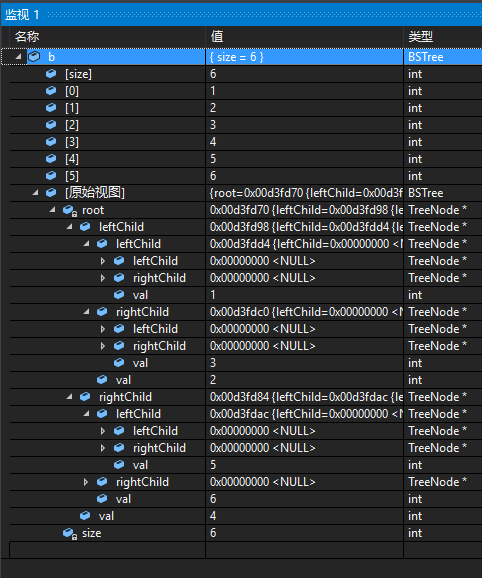
这里用到的类型为TreeItems
Size指定了树的元素数目,这样调试器就会根据该项显示指定数目的元素。若这里没有指定Size,则调试器会自动对链表进行推导直到遇到空指针结束。通常指定Size的话可以提高调试程序的性能。
HeadPointer指定了树的根结点指针
LeftPointer指定了结点的左孩子指针
RightPointer指定了结点的右孩子指针
ValueNode指定了要输出的值
如果这里用到的是key和value的组合的话,只需要将<ValueNode>修改成<ValueNode Name = "[{key}]">的形式即可。
还有许多高级的功能可以尝试自行摸索。
参考链接:
https://blogs.msdn.microsoft.com/vcblog/2015/09/28/debug-visualizers-in-visual-c-2015/
https://msdn.microsoft.com/zh-cn/library/jj620914(v=vs.110).aspx
在Visual Studio中使用Debug Visualizers在C++中实现对原始类的自定义调试信息显示的更多相关文章
- Visual Studio 2010(.NET 4.0)中使用SQLite.NET
Visual Studio 2010(.NET 4.0)中使用SQLite.NET 2011年4月1日 | 分类: DataBase, DOTNET | 标签: .net 4.0, SQLite. ...
- 【C#】Visual Studio 2017 一边Debug,一边修改代码
好久没写C#了,最近在学习著名***工具 shadowsocks-windows 的源代码,想着可以边断点调试,边加上一些注释以方便理解,stackoverflow 和 msdn 随便翻了一下,竟发现 ...
- 如何把visual studio 2010的工程文件迁入TFS2010中管理
如何在VS2010里面创建项目并添加到TFS2010里面. 新建一个项目,并把它添加到TFS,我们会收到下面的错误: 这是因为我们没有为项目创建Team project,而把它直接添加到了Team p ...
- 006.Adding a controller to a ASP.NET Core MVC app with Visual Studio -- 【在asp.net core mvc 中添加一个控制器】
Adding a controller to a ASP.NET Core MVC app with Visual Studio 在asp.net core mvc 中添加一个控制器 2017-2-2 ...
- 在 Visual Studio 2017 中找回消失的“在浏览器中查看”命令
不知为何,在新安装 Visual Studio 2017 后,发现所有 Web 项目上右键菜单的"在浏览器中查看"命令消失了,只能以调试模式启动网站,非常别扭. 最后在 Stack ...
- Visual Studio 2017&C#打包应用程序详细教程,重写安装类获取安装路径
Visual Studio搞了个Click One,在线升级是方便了,但对于俺们这苦逼的业余程序猿就... 别着急,折腾一下,还是能做出打包安装程序的.请移步CSDN看smallbabylong的文章 ...
- Visual Studio Code——PHP Debug扩展
最近在使用PHP开发,使用了很多IDE,发现都不是很顺手,之前一直都在使用Sublime Text,但是作为一个爱折腾的人,当我发现VS Code以后觉得很是很适合自己的编程需要的.配置过程中遇到了一 ...
- Visual Studio 2015在.NET Core RC2项目中的一个错误。
更新了.NET Core RC2 之后,VS的Web Tools更新为“Preview 1”了. 这个版本有一个问题,害我折腾了一个下午. 就是在项目界面的“依赖项 - NPM”上面错误地显示了不必要 ...
- 使用 Visual Studio Team Test 进行单元测试和java中的测试
C#中test测试地 方法一. 1.从NUnit官网(http://www.nunit.org/index.php)下载最新版本NUnit,当前版本为NUnit2.5.8. 2.安装后,在VS2008 ...
随机推荐
- ZooKeeper 客户端的使用
连接zk 1 2 cd bin zkCli.sh -timeout 5000 -server 27.154.242.214:5091 输入h,回车查看帮助 1 2 3 4 5 6 7 8 9 10 1 ...
- java缓存系统
第一版 package cache; import java.util.HashMap; import java.util.Map; public class Cache1 { private Map ...
- RDS和ROS使用小结
微软的RDS和linux下的ROS,都已经使用了一段时间,RDS已经很久不更新了,前景必然不如ROS,但无奈用得顺手,还是偶尔怀旧一下. 使用RDS除了内置的文档需要仔细阅读,有些corobot.pr ...
- android采用SurfaceView实现文字滚动效果
前言 为了实现文字的滚动效果,之前也重写了TextView效果都不太好,后来对SurfaceView进行完善. 声明 欢迎转载,但请保留文章原始出处:) 小崔博客:http://blog.c ...
- android Titlebar一行代码实现沉浸式效果
github地址 一个简单易用的导航栏TitleBar,可以轻松实现IOS导航栏的各种效果 整个代码全部集中在TitleBar.java中,所有控件都动态生成,动态布局.不需要引用任何资源文件,拷贝 ...
- DEVICE_ATTR实例分析
在内核中, sysfs 属性一般是由 __ATTR 系列的宏来声明的,如对设备的使用 DEVICE_ATTR ,对总线使用 BUS_ATTR ,对驱动使用 DRIVER_ATTR ,对类别(class ...
- SpriteBuilder中的CCSprite9Slice是个什么鬼?
CCSprite大家都知道,但是加上后面那一串又变成了神马呢? 我们可以首先到官方的API文档网站查一下,如下: http://www.cocos2d-swift.org/docs/api/Class ...
- mybatis ---- 实现数据的增删改查
前面介绍了接口方式的编程,需要注意的是:在book.xml文件中,<mapper namespace="com.mybatis.dao.IBookDao"> ,命名空间 ...
- CentOS 7 下安装mosquitto
简介 MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)是IBM开发的一个即时通讯协议,有可能成为物联网的重要组成部分.该协议支持所有平台,几乎可以把 ...
- MQ队列管理器搭建(二)
MQ级联方式使用场景 使用场景: 如上图所示,Application1与Application2要进行通信或者消息互换,使用MQ中间件作为中介.上图中,Application1与Applica ...