单机配置kafka和zookeeper
1:环境准备
jdk 推荐oracle,不建议open sdk
在/etc/profile加入下列环境变量

在PATH中将jdk和jre的bin加入path里面
$JAVA_HOME/bin:$JRE_HOME/bin
2:安装zookeeper
下载zookeeper tar
url: https://archive.apache.org/dist/zookeeper/zookeeper-3.4.5/zookeeper-3.4.5.tar.gz
将压缩包移动到/usr/local下面
tar -zxvf ***
更改配置文件
(1)将conf/zoo_sample.cfg更改为zoo.cfg
(2)更改配置如下
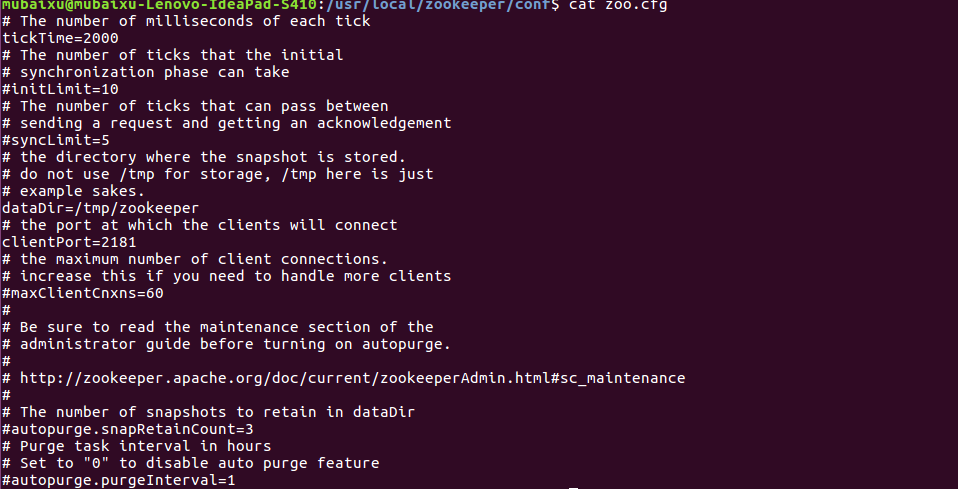
注意:
*其中默认port为2181。
*datadir需手动创建 mkdir -p datadir
*注释掉的参数在单机中无用
(3)加入环境变量 /etc/profile

测试:
可以cd 到bin目录下通过执行 zkServer.sh shell脚本启动、停止或者查看状态
eg:
./zkServer.sh start/stop/status
3:安装kafka
先下载tar包、解压、mv到/usr/local下面
wget https://www.apache.org/dyn/closer.cgi?path=/kafka/0.11.0.0/kafka_2.11-0.11.0.0.tgz
sudo mv *** /usr/local
cd /usr/local
sudo tar -zxvf ****
sudo rm **.tar.gz
修改config目录下配置文件
vim server.properties
修改如下参数
#broker.id需改成正整数,单机为1就好
broker.id=
#指定端口号
port=
#localhost这一项还有其他要修改,详细见下面说明
host.name=localhost
#指定kafka的日志目录
log.dirs=/usr/local/kafka_2.-0.11.0.0/kafka-logs
#连接zookeeper配置项,这里指定的是单机,所以只需要配置localhost,若是实际生产环境,需要在这里添加其他ip地址和端口号
zookeeper.connect=localhost:
vim zookeeper.properties
修改如下参数
#数据目录
dataDir=/usr/local/kafka_2.-0.11.0.0/zookeeper/data
#客户端端口
clientPort=
host.name=localhost
producer.properties and consumer.properties
zookeeper.connect=localhost:
4:启动kafka
bin/zookeeper-server-start.sh config/zookeeper.properties
bin/kafka-server-start.sh config/server.properties
终端都是info log
注意:如果是非root用户,可能会使用到sudo去启动zookeeper和kafka,但是那样会失败必须将kafka整个目录下的文件的owner和group都改为自己的用户。
可以通过jps命令查看两者是否启动成功

2576 QuorumPeerMain表示zookeeper
如果发现没启动成功,可以在zookeeper/config/zookeeper.out里debug。
成功启动后,可以简单通过demo进行测试
github有各种语言的kafka支持
url:https://github.com/edenhill/librdkafka/tree/v0.9.5
可以简单通过go的demo进行测试
consumer
import (
"fmt"
"github.com/confluentinc/confluent-kafka-go/kafka"
) func main() { c, err := kafka.NewConsumer(&kafka.ConfigMap{
"bootstrap.servers": "localhost",
"group.id": "myGroup",
"auto.offset.reset": "earliest",
}) if err != nil {
panic(err)
} c.SubscribeTopics([]string{"myTopic", "^aRegex.*[Tt]opic"}, nil) for {
msg, err := c.ReadMessage(-)
if err == nil {
fmt.Printf("Message on %s: %s\n", msg.TopicPartition, string(msg.Value))
} else {
fmt.Printf("Consumer error: %v (%v)\n", err, msg)
break
}
} c.Close()
}
producer
import (
"fmt"
"github.com/confluentinc/confluent-kafka-go/kafka"
) func main() { p, err := kafka.NewProducer(&kafka.ConfigMap{"bootstrap.servers": "localhost"})
if err != nil {
panic(err)
} go func() {
for e := range p.Events() {
switch ev := e.(type) {
case *kafka.Message:
if ev.TopicPartition.Error != nil {
fmt.Printf("Delivery failed: %v\n", ev.TopicPartition)
} else {
fmt.Printf("Delivered message to %v\n", ev.TopicPartition)
}
}
}
}() topic := "myTopic"
for _, word := range []string{"Welcome", "to", "the", "Confluent", "Kafka", "Golang", "client"} {
p.Produce(&kafka.Message{
TopicPartition: kafka.TopicPartition{Topic: &topic, Partition: kafka.PartitionAny},
Value: []byte(word),
}, nil)
} p.Flush( * )
}
单机配置kafka和zookeeper的更多相关文章
- Windows单机配置Kafka环境
首先确保机器已经安装好Zookeeper,Zookeeper安装参考 Windows单机配置Zookeeper环境 然后确保Zookeeper是正常启动状态 下载Kafka http://kafka. ...
- centOS7安装kafka和zookeeper
wget http://mirrors.hust.edu.cn/apache/kafka/2.0.0/kafka_2.11-2.0.0.tgz tar zxvf kafka_2.-.tgz cd ka ...
- Kafka单机配置部署
摘要:上节 学习了Kafka的理论知识,这里安装单机版以便后续的测试. 首先安装jdk 一.单机部署zk 1.1安装: tar -zxf zookeeper-3.4.10.tar.gz -C /opt ...
- 使用kafka bin目录中的zookeeper-shell.sh来查看kafka在zookeeper中的配置
cd kafka_2.11-0.10.2.1\bin\windowsecho ls /brokers/ids | zookeeper-shell.bat localhost:2181 使用kafka ...
- hadoop+yarn+hbase+storm+kafka+spark+zookeeper)高可用集群详细配置
配置 hadoop+yarn+hbase+storm+kafka+spark+zookeeper 高可用集群,同时安装相关组建:JDK,MySQL,Hive,Flume 文章目录 环境介绍 节点介绍 ...
- kafka与zookeeper
kafka简介 kafka (官网地址:http://kafka.apache.org)是一款分布式消息发布和订阅的系统,具有高性能和高吞吐率. 下载地址:http://kafka.apache.or ...
- centos7单机安装kafka,进行生产者消费者测试
[转载请注明]: 原文出处:https://www.cnblogs.com/jstarseven/p/11364852.html 作者:jstarseven 码字挺辛苦的..... 一.k ...
- linux单机部署kafka(filebeat+elk组合)
filebeat+elk组合之kafka单机部署 准备: kafka下载链接地址:http://kafka.apache.org/downloads.html 在这里下载kafka_2.12-2.10 ...
- Java面试题(Kafka篇+zookeeper 篇)
Kafka 152.kafka 可以脱离 zookeeper 单独使用吗?为什么? kafka 不能脱离 zookeeper 单独使用,因为 kafka 使用 zookeeper 管理和协调 kafk ...
随机推荐
- centos 5.3 安装(samba 3.4.4)
centos 5.3 安装(samba 3.4.4) 博客分类: 操作系统 Linux 随着Linux的普及,如何共享Linux下的文件成为用户关心的问题.其实,几乎所有的Linux发行套件都提供 ...
- HashMap 深入分析
/** *@author annegu *@date 2009-12-02 */ Hashmap是一种非常常用的.应用广泛的数据类型,最近研究到相关的内容,就正好复习一下.网上 ...
- GitHub awesome Resource
各种Awesome技术资源的资源聚合: https://github.com/sindresorhus/awesome Contents Platforms Programming Languages ...
- OCR智能识别身份信息
本人研究了两款OCR智能识别的API,下面做详解! 第一款是百度云的OCR识别,填写配置信息,每天有五百次免费的识别次数,适合中小型客户流量可以使用.API文档:http://ai.baidu.com ...
- 【转】javascript 分号问题
javascript的分号代表语句的结束符,但由于javascript具有分号自动插入规则,所以它是一个十分容易让人模糊的东西,在一般情况下,一个换行就会产生一个分号,但实际情况却不然,也就是说在ja ...
- Tornado day1
Tornado 之路由配置 首先导入模块,使用Application方法中可配置多个路由,格式必须为列表中是元组 元组的第一个是配置的url,第二个参数时自定义的类(继承自RequestHandler ...
- Python_字符串的大小写变换
''' lower().upper().capitalize().title().swapcase() 这几个方法分别用来将字符串转换为小写.大写字符串.将字符串首字母变为大写.将每个首字母变为大写以 ...
- PAT1009:Product of Polynomials
1009. Product of Polynomials (25) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yu ...
- 并发库应用之十二 & 常用集合问题汇总
1. List遍历时修改报错 别的先什么都不说,直接上代码看看就知道了: public class ListTest { public static void main(String[] args) ...
- 搭建Hadoop完全分布式
Centos7搭建hadoop完全分布式 虽然说是完全分布式,但三个节点也都是在一台机器上.拿来练手也只能这样咯,将就下.效果是一样滴.这个我自己都忘了步骤,一起来回顾下吧. 必备知识: Linux基 ...