《T-SQL查询》读书笔记Part 3.索引的基本知识
索引优化是查询优化中最重要的一部分,索引是一种用于排序和搜索的结构,在查找数据时索引可以减少对I/O的需要;当计划中的某些元素需要或是可以利用经过排序的数据时,也会减少对排序的需要。某些方面的优化可以适度提高性能,而索引优化经常可以大幅度地提高查询性能。
一、表和索引的结构
1.1 页和区
页是MSSQL存储数据的基本单位,大小为8KB,是MSSQL可以读写的最小I/O单位。=> 即使只访问一行,MS SQL也会将整个页加载到缓存,再从换从中读取数据。
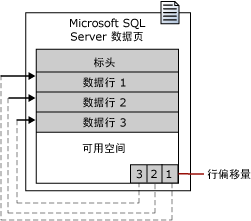
区是由8个物理上连续的页组成的单元。=> 当表或索引需要更多空间以存储数据时,MSSQL会为对象分配一个完整的区。
为了使空间分配更有效,SQL Server 不会将所有区分配给包含少量数据的表。MSSQL有两种类型的区:混合区和统一区,区别详见参考资料(4)。

PS:看来MSSQL比较喜欢8这个数字。此外,我们需要了解的就是I/O操作中开销最大的部分是磁盘臂(Disk Arm)的移动,而真正的磁盘读写操作的开销要小得多;因此,读取一个页和读取整个区所用的时间几乎一样长。
1.2 表的组织方式

堆(Heap)
堆是不含聚集索引的表(所以只有非聚集索引的表也是堆),因为它的数据不会按照任何顺序进行组织,而是按分区组队数据进行组织。=> 当你使用SELECT语句访问堆表时,MSSQL在执行计划里会使用表扫描(Table Scan)运算符,因为你没有定义合适的聚集索引。表扫描意味着你必须扫描整张表,不以你表拥有的数据量来衡量。你的数据量越多,操作花费(时间)越长。
在堆中,有一个索引分配映射(IAM)的位图页用于保存数据之间的关系,在下图中,MSSQL维护着指向第一个IAM页和堆中第一个数据也的内部指针。
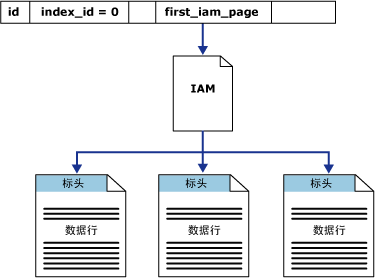
这些指针可以在系统视图sys.system_internals_allocation_units中找到。

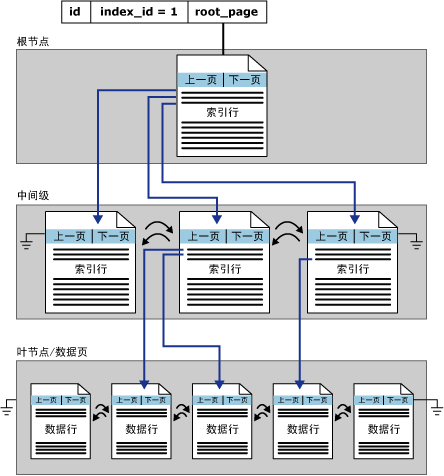
B树
MSSQL中的所有聚集索引都是按照B树结构组织的,B树中的每一页称为一个索引节点。每个索引行包含一个键值和一个指针。指针指向B树上的某一中间级页(比如根节点指向中间级节点中的索引页)或叶级索引中的某个数据行(比如中间级索引页中的某个索引行指向叶子节点中的数据页)。每级索引中的页均被链接在双向链接列表中。数据链内的页和行将按聚集索引键值进行排序,聚集索引保证了表格的数据按照索引行的顺序排列。
二、索引的访问方法
2.1 表扫描/无序聚集索引扫描
表扫描/无序聚集索引扫描是对表的所有数据页进行扫描。下面的查询就对Orders表(结构化为堆,因此查询之前需要首先删除该表的聚集索引)执行表扫描:
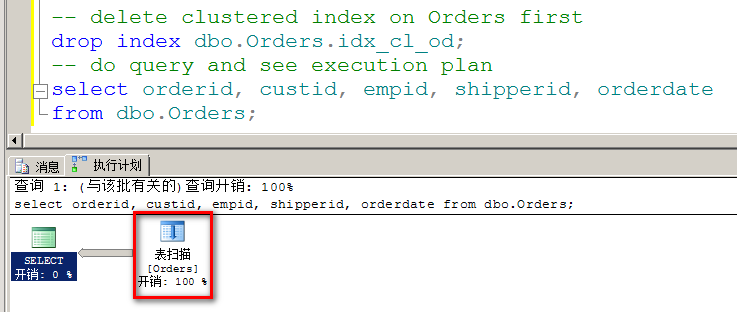
运行这个查询后,通过STATISTICS IO, STATISTICS TIME得到的性能指标如下所示:
-- clear cache
dbcc dropcleanbuffers;
-- statistics io
set statistics io on;
-- statistics time
set statistics time on;

如果该表包含聚集索引,那么采用的访问方法将会是无序聚集索引扫描(Clustered Index Scan运算符,其Ordered属性为False)。下图展示了优化器为该查询将生成的执行计划。
这里首先给Orders表加一个聚集索引。
-- add clustered index for Orders
create clustered index idx_cl_od on dbo.Orders(orderdate);
再次查看执行计划,从表扫描变成了聚集索引扫描。这里可以看到其中已排序这个属性为False,就关系引擎来说,该运算符不需要返回有序的数据。(即返回任何顺序的数据都没有问题)

运行这个查询后,通过STATISTICS IO, STATISTICS TIME得到的性能指标如下所示:

可以看到,表扫描和无序聚集索引扫描的查询效率差不多的。
2.2 无序覆盖非聚集索引扫描
无序覆盖非聚集索引扫描类似于无序聚集索引扫描,覆盖索引的概念表示非聚集索引包含在查询中指定的所有列中。MSSQL只需要访问索引数据就可以找到满足查询所需的全部数据。
这里我们来看看下面的查询,假设我们之前在Orders表的orderid列上建立了一个非聚集索引PK_Orders(主键),即所有orderid都处于索引的叶级。因此,索引覆盖了这个查询。
-- pk_orders
select orderid
from dbo.Orders;
其执行计划如下图所示:
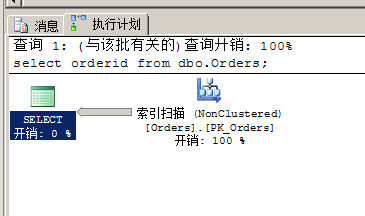
运行这个查询后,通过STATISTICS IO, STATISTICS TIME得到的性能指标如下所示:

可以看到,逻辑读取次数减少了近10倍,而执行时间减少了一半。
2.3 有序聚集索引扫描
有序聚集索引扫描是针对聚集索引的叶级执行的一种完整扫描,可以确保按照索引顺序为下一个运算符返回数据。
例如,下面的查询请求按orderdate排序的所有订单:
-- ordered clustered index scan
select orderid, custid, empid, shipperid, orderdate
from dbo.Orders
order by orderdate;
其执行计划如下图所示,可以看到这次已排序属性值变成了True。这就表示,从运算符返回来的数据应该是有序的,而且存储引擎只能以索引顺序扫描。
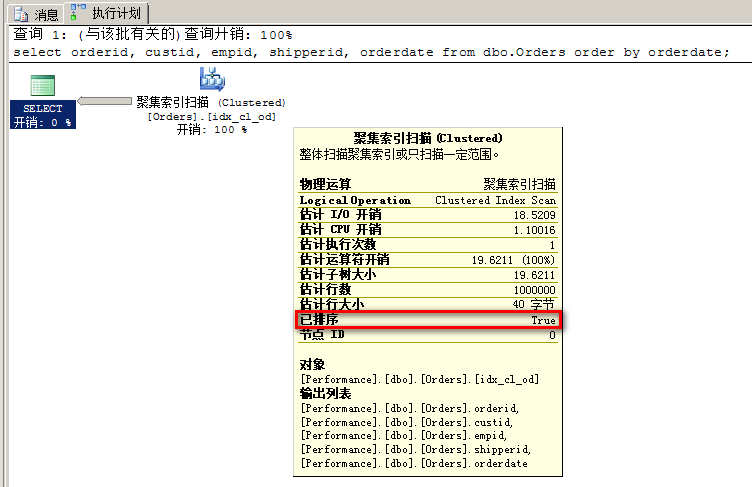
运行这个查询后,通过STATISTICS IO, STATISTICS TIME得到的性能指标如下所示:

可以看到,查询效率和表扫描、无序聚集索引扫描差不多,执行时间略多于前两者。
参考资料

(1)[美] Itzik Ben-Gan 著,成保栋 译,《Microsoft SQL Server 2008技术内幕:T-SQL查询》
(2)Hyber Wang,《重新理解SQL Server的聚集索引表与堆表》
(3)悉路,《SQL Server性能优化(8)堆表结构介绍》
(4)Microsoft TechNet,《TN 页和区》
(5)xwdreamer,《Sql Server中的表组织和索引组织(聚集索引结构,非聚集索引结构,堆结构)》
《T-SQL查询》读书笔记Part 3.索引的基本知识的更多相关文章
- SQL查询(笔记2——实体查询)
SQL查询(笔记2——实体查询) 二.实体查询 如果查询返回了某个数据表的全部数据列,且该数据表有对应的持久化类映射,我们就把查询结果转换成实体查询.将查询结果转换成实体,可以使用SQLQuery提供 ...
- 《Programming Hive》读书笔记(两)Hive基础知识
<Programming Hive>读书笔记(两)Hive基础知识 :第一遍读是浏览.建立知识索引,由于有些知识不一定能用到,知道就好.感兴趣的部分能够多研究. 以后用的时候再具体看.并结 ...
- 【MySQL 读书笔记】普通索引和唯一索引应该怎么选择
通常我们在做这个选择的时候,考虑得最多的应该是如果我们需要让 Database MySQL 来帮助我们从数据库层面过滤掉对应字段的重复数据我们会选择唯一索引,如果没有前者的需求,一般都会使用普通索引. ...
- 多线程处理慢sql查询小笔记~
多线程处理慢sql查询以及List(Array)的拆分 系统数据量不大,但是访问速度特别慢,使用多线程优化一下!!! 优化结果:访问时间缩短了十几秒 25s --> 8s 一.List的拆分: ...
- SQL.Cookbook 读书笔记5 元数据查询
第五章 元数据查询 查询数据库本身信息 表结构 索引等 5.1 查询test库下的所有表信息 MYSQL SELECT * from information_schema.`TABLES` WHERE ...
- SQL.Cookbook 读书笔记2 查询结果排序
第二章 查询结果排序 2.1 按查询字段排序 order by sal asc; desc;-- 3表示sal 2.2 按子串查询 );--按job的最后两个字符排序 2.3 对字符数字混合排序 cr ...
- SQL SERVER 读书笔记:非聚集索引
对于有聚集索引的表,数据存储在聚集索引的叶子节点,而非聚集索引则存储 索引键值 和 聚集索引键值.对于非聚集索引,如果查找的字段没有包含在索引键值,则还要根据聚集索引键值来查找详细数据,此谓 Book ...
- SQL SERVER读书笔记:内存
系统先操作地址空间,真正要用的时候才申请物理内存,进行使用. Reserved Memory 保留内存,虚拟内存 Commited Memory 提交内存,物理内存 [如何判断SQL SERVER ...
- SQL SERVER读书笔记:TempDB
每次SQL SERVER启动的时候,会重新创建. 用于 0.临时表 1.排序 2.连接(merge join,hash join) 3.行版本控制 临时表与表变量的区别: 1)表变量是存储在内存中的, ...
随机推荐
- (NO.00001)iOS游戏SpeedBoy Lite成形记(二十二)
自己的游戏自己更需要多玩,这样才能首先发现不足的地方.所以本猫到现在已经忍一个地方很久了,就是弹出moneyLayer后每次都要输入数字才能关闭,这多少让人不爽.于是本篇我们就修正这个小小的不便. 首 ...
- 再回首UML之上篇
UML,统一建模语言,是一种用来对真实世界物体进行建模的标准标记,这个建模的过程是开发面向对象设计方法的第一步,UML不是一种方法学,不需要任何正式的工作产品. UML提供多种类型的模型描述图,当在某 ...
- 如何优化你的布局层级结构之RelativeLayout和LinearLayout及FrameLayout性能分析
转载请注明出处:http://blog.csdn.net/hejjunlin/article/details/51159419 如何优化你的布局层级结构之RelativeLayout和LinearLa ...
- Gradle 1.12用户指南翻译——第二十八章. Jetty 插件
其他章节的翻译请参见: http://blog.csdn.net/column/details/gradle-translation.html 翻译项目请关注Github上的地址: https://g ...
- linux上 java 使用 javasqlite
linux上 java 使用 javasqlite http://www.ch-werner.de/javasqlite/ 1) 下载: http://www.ch-werner.de/javasql ...
- Linux自动安装JDK的shell脚本
Linux自动安装JDK的shell脚本 A:本脚本运行的机器,Linux B:待安装JDK的机器, Linux 首先在脚本运行的机器A上确定可以ssh无密码登录到待安装jdk的机器B上,然后就可以在 ...
- FNDCPASS Troubleshooting Guide For Login and Changing Applications Passwords
In this Document Goal Solution 1. Error Starting Application Services After Changing APPS Pass ...
- 不用局部变量实现C语言两数交换算法
关于交换算法,我想非常简单,所以,这次不做分析,直接上代码: #include <stdio.h> #include <stdlib.h> //用异或方式实现 void swa ...
- OpenCV kmeans代码
代码:出处忘了 // // Example 13-1. Using K-means // // /* *************** License:************************* ...
- Unity修改Particles Render Material(Unity3D开发之二十三)
猴子原创,欢迎转载.转载请注明: 转载自Cocos2Der-CSDN,谢谢! 原文地址: http://blog.csdn.net/cocos2der/article/details/48372999 ...