python 线程队列、线程池、全局解释器锁GIL
一、线程队列
队列特性:取一个值少一个,只能取一次,没有值的时候会阻塞,队列满了,也会阻塞
queue队列 :使用import queue,用法与进程Queue一样
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
三种类型:
(1)先进先出 (fifo) q=queue.Queue
先进先出队列
(2)#后进先出,先进后出 (Lifo) q=queue.LifoQueue
先进后出队列
(3)优先队列 (Priority) q=queue.PriorityQueue(5)
优先队列
二、python 标准模块--concurrent.futures
到这里就差我们的线程池没有讲了,我们用一个新的模块给大家讲,早期的时候我们没有线程池,现在python提供了一个新的标准或者说内置的模块,这个模块里面提供了新的线程池和进程池,之前我们说的进程池是在multiprocessing里面的,现在这个在这个新的模块里面,他俩用法上是一样的。
为什么要将进程池和线程池放到一起呢,是为了统一使用方式,使用threadPollExecutor和ProcessPoolExecutor的方式一样,而且只要通过这个concurrent.futures导入就可以直接用他们两个了.
模块方法解析
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class. #2 基本方法
#submit(fn, *args, **kwargs)
异步提交任务 #map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作 #shutdown(wait=True)
相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前 #result(timeout=None)
取得结果 #add_done_callback(fn)
回调函数
三、concurrent.futures模块的应用:线程池、进程池
submit()和shutdown()的应用
import time
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def fun(n):
time.sleep(1)
return n*n if __name__ == '__main__':
t_p=ThreadPoolExecutor(max_workers=4) #创建线程池,池子中只有四个线程可以同时运行
#从concurrent.futures引入ThreadPoolExecutor,ProcessPoolExecutor,可以让进程与线程之间的代码通用,只需将
# ThreadPoolExecutor与ProcessPoolExecutor互换
# t_p=ProcessPoolExecutor(max_workers=4)#创建进程池,池子中只有四个进程可以同时运行,
res_lst=[]
for i in range(1,11):
res=t_p.submit(fun,i) #submit(func,*args) 创建线程,返回值是线程对象
# print(res) #获取线程对象,并没有执行线程的函数 <Future at 0x1df505f2390 state=pending>
# print(res.result()) #for 循环内部的result获取对象结果,会阻塞程序运行,直至拿到该线程的结果
res_lst.append(res) #按照先后循序存放线程结果 [res1,res2...res10]
t_p.shutdown() #相当于 pool.close() +pool.join() 确保池子里面的线程全部执行完毕,再进行主程序代码
print("主程序结束")
#从结果对象列表中取数据
for res1 in res_lst:
print(res1.result())
submit+shutdown线程代码
我们只需要更改一句语句就可以实现,线程到进程的改变
(更改前)t_p=ThreadPoolExecutor(max_workers=4)
(更改后)t_p=ProcessPoolExecutor(max_workers=4)
import time
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def fun(n):
time.sleep(1)
return n*n if __name__ == '__main__':
# t_p=ThreadPoolExecutor(max_workers=4) #创建线程池,池子中只有四个线程可以同时运行
#从concurrent.futures引入ThreadPoolExecutor,ProcessPoolExecutor,可以让进程与线程之间的代码通用,只需将
# ThreadPoolExecutor与ProcessPoolExecutor互换
t_p=ProcessPoolExecutor(max_workers=4)#创建进程池,池子中只有四个进程可以同时运行,
res_lst=[]
for i in range(1,11):
res=t_p.submit(fun,i) #submit(func,*args) 创建线程,返回值是线程对象
# print(res) #获取线程对象,并没有执行线程的函数 <Future at 0x1df505f2390 state=pending>
# print(res.result()) #for 循环内部的result获取对象结果,会阻塞程序运行,直至拿到该线程的结果
res_lst.append(res) #按照先后循序存放线程结果 [res1,res2...res10]
t_p.shutdown() #相当于 pool.close() +pool.join() 确保池子里面的线程全部执行完毕,再进行主程序代码
print("主程序结束")
#从结果对象列表中取数据
for res1 in res_lst:
print(res1.result())
submit+shutdown进程代码
map方法的使用:
import time
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor
from multiprocessing import Pool def func(n):
time.sleep(1)
return n * n if __name__ == '__main__':
t_p = ThreadPoolExecutor(max_workers=4)
#map(func,可迭代对象) 表示异步提交任务
res = t_p.map(func,range(10)) #与进程的方式一样 ,但是不自带close()+join()
t_p.shutdown()
print('主线程结束')
for i in res:
print(i)
#multiprocess中Pool.map
pool=Pool(4)
ret=pool.map(func,range(10)) #自带pool.close()+pool.join()
print(ret) #结果列表
for i in ret:
print(i)
与multiprocess中的map对比
callback回调函数的使用
importtimefromconcurrent.futuresimportThreadPoolExecutor,ProcessPoolExecutordeffun(n):time.sleep(1)returnn*ndefcall_back(m):print(">>>",m)print(m.result())return"返回"if__name__=='__main__':t_p=ThreadPoolExecutor(max_workers=4)res=t_p.submit(fun,10).add_done_callback(call_back)#无法接收回调函数的值print(res)#None
回调函数的使用
四、全局解释器锁GIL (详情参考:https://www.cnblogs.com/clschao/articles/9705317.html)
首先,一些语言(java、c++、c)是支持同一个进程中的多个线程是可以应用多核CPU的,也就是我们会听到的现在4核8核这种多核CPU技术的牛逼之处。那么我们之前说过应用多进程的时候如果有共享数据是不是会出现数据不安全的问题啊,就是多个进程同时一个文件中去抢这个数据,大家都把这个数据改了,但是还没来得及去更新到原来的文件中,就被其他进程也计算了,导致数据不安全的问题啊,所以我们是不是通过加锁可以解决啊,多线程大家想一下是不是一样的,并发执行就是有这个问题。但是python最早期的时候对于多线程也加锁,但是python比较极端的(在当时电脑cpu确实只有1核)加了一个GIL全局解释锁,是解释器级别的,锁的是整个线程,而不是线程里面的某些数据操作,每次只能有一个线程使用cpu,也就说多线程用不了多核,但是他不是python语言的问题,是CPython解释器的特性,如果用Jpython解释器是没有这个问题的,Cpython是默认的,因为速度快,Jpython是java开发的,在Cpython里面就是没办法用多核,这是python的弊病,历史问题,虽然众多python团队的大神在致力于改变这个情况,但是暂没有解决。(这和解释型语言(python,php)和编译型语言有关系吗???待定!,编译型语言一般在编译的过程中就帮你分配好了,解释型要边解释边执行,所以为了防止出现数据不安全的情况加上了这个锁,这是所有解释型语言的弊端??)
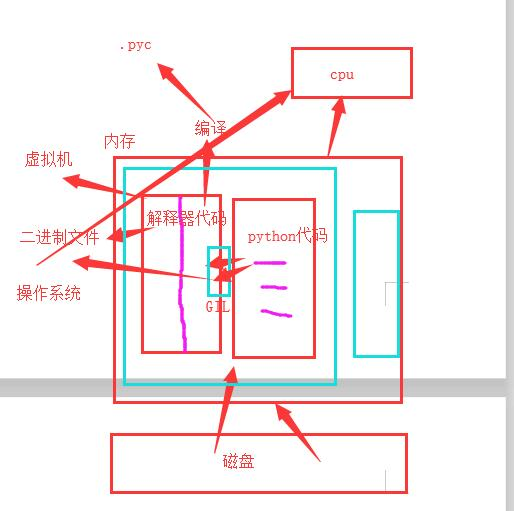
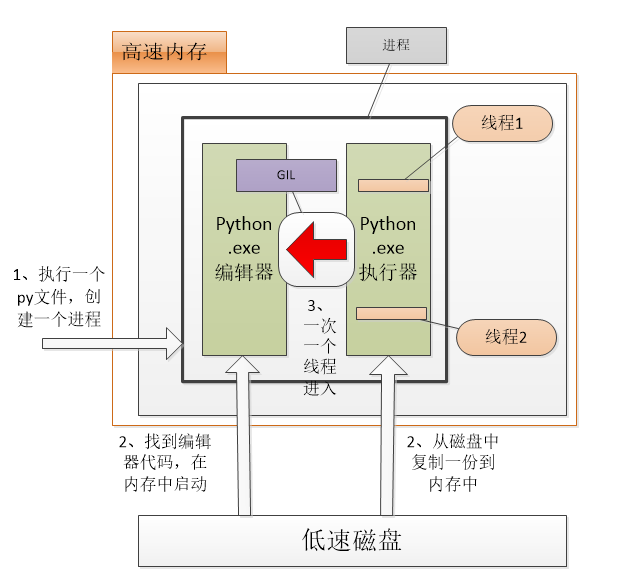
简述:1、执行.py文件的时候,首先创建一个进程;
2、找到python.exe执行器,在内存中执行,并且将py文件中的python代码拷贝一份到内存中;
3、同时只允许一个线程进入GIL锁里面进行编译成.pyc文件和通过虚拟机编译二进制文件,编译好的二进制文件直接给cpu运行。
注意:GIL锁是互斥锁,当一个线程进入了python.exe解析器中,如果遇到I/O操作,系统自动回收GIL权限,并记录切换的状态,下一个线程通过GIL锁进入了python.exe中解析,遇到i/o操作就切换,不断的执行。
五、GIL与Lock
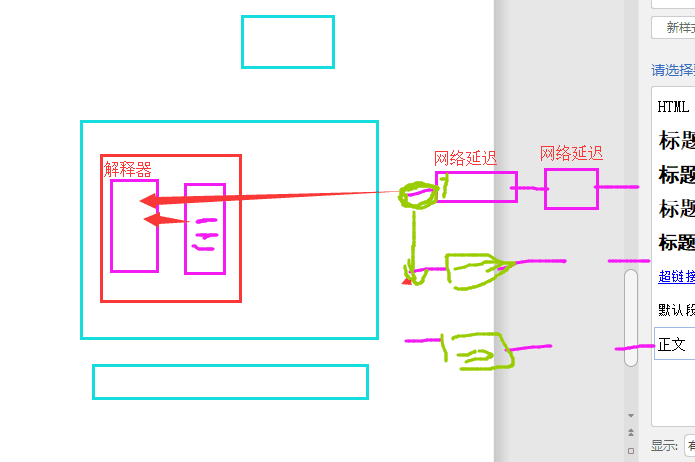
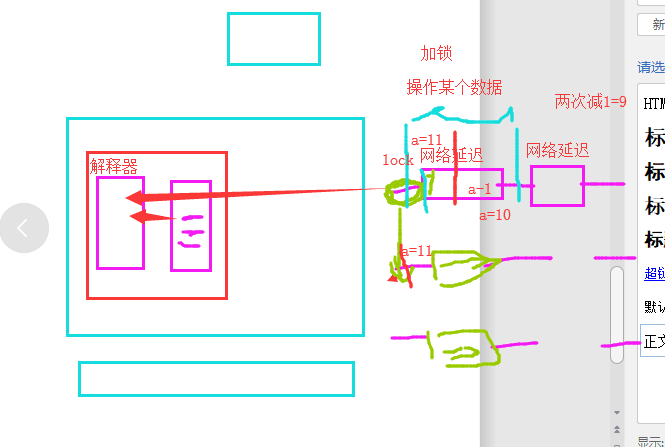
如果没有lock锁,在数据操作的过程中,线程通过GIL锁进入解析器中,遇到I/O操作会回收,线程的GIL锁权限,然后其他线程就可以拿到锁进入解析器,这样之前的数据还没来得及修改,就被下一个线程获得数据,这样就会造成数据混乱。如果有lock锁,就算系统回收了GIL锁的权限,但后面的线程都在lock锁的外面,一直属于阻塞状态,不会进行lock锁中的数据,这样就保证了数据的安全性,但是数据处理效率减低了。
python 线程队列、线程池、全局解释器锁GIL的更多相关文章
- 全局解释器锁GIL & 线程锁
1.GIL锁(Global Interpreter Lock) Python代码的执行由Python虚拟机(也叫解释器主循环)来控制.Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行 ...
- python 什么是全局解释器锁GIL
什么是全局解释器锁GIL Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython版本)来控制,Python 在设计之初就考虑到要在解释器的主循环中,同时只有一个线程在执行,即在 ...
- 21.线程,全局解释器锁(GIL)
import time from threading import Thread from multiprocessing import Process #计数的方式消耗系统资源 def two_hu ...
- Python如何规避全局解释器锁(GIL)带来的限制
编程语言分类概念介绍(编译型语言.解释型语言.静态类型语言.动态类型语言概念与区别) https://www.cnblogs.com/zhoug2020/p/5972262.html Python解释 ...
- 全局解释器锁GIL
我们使用高并发,一次是创建1万个线程去修改一个数并打印结果看现象: from threading import Thread import os def func(args): global n n ...
- 并发编程——全局解释器锁GIL
1.全局解释器锁GIL GIL其实就是一把互斥锁(牺牲了效率但是保证了数据的安全). 线程是执行单位,但是不能直接运行,需要先拿到python解释器解释之后才能被cpu执行 同一时刻同一个进程内多个线 ...
- python 多线程编程之使用进程和全局解释器锁GIL
本文主要介绍如何在python中使用线程. 全局解释器锁: python代码的执行是由python虚拟机(又名解释器主循环)进行控制的.python中,主循环中同时只能有一个控制线程在执行,就像单核C ...
- Python全局解释器锁 -- GIL
首先强调背景: 1.GIL是什么?GIL的全称是Global Interpreter Lock(全局解释器锁),来源是python设计之初的考虑,为了数据安全所做的决定. 2.每个CPU在同一时间只能 ...
- Python核心技术与实战——十九|一起看看Python全局解释器锁GIL
我们在前面的几节课里讲了Python的并发编程的特性,也了解了多线程编程.事实上,Python的多线程有一个非常重要的话题——GIL(Global Interpreter Lock).我们今天就来讲一 ...
随机推荐
- [转]git commit之后,想撤销commit
本文转自:http://www.cnblogs.com/lfxiao/p/9378763.html 写完代码后,我们一般这样 git add . //添加所有文件 git commit -m &quo ...
- 升级ssh到OpenSSH_7.5p1
Redhat 6.5 x64升级SSH到OpenSSH_7.5p1 为了防止openssh安装失败导致不能远程登录,先部署telnet服务以防万一. rpm -qa telnet telnet-ser ...
- 从零开始学安全(十六)● Linux vim命令
游标控制 h 游标向左移 j 游标向下移 k 游标向上移 l (or spacebar) 游标向右移 w 向前移动一个单词 b 向后移动一个单词 e 向前移动一个单词,且游标指向单词的末尾 ( 移到当 ...
- String为什么是不可变的?
前几天一个面试被问到String为什么是不可变的?, 自我感觉当时回答的不太理想, 事后总结一下 不可变的是什么 我们谈论的String不可变, 指的是字符串的值不可变 例: String s = & ...
- mybatis笔记02
目录 0. 文章目录 1. Mybatis映射文件 1.1 输入映射 1.2 输出映射 1.3 resultMap 2. 动态SQL 2.1 if和where 2.2 foreach循环 2.3 sq ...
- 反射demo(拷贝一个对象)
经过了上一次对反射的初步认知,最近又接触到了后,做了一个小demo,感觉这次带了一点理解去做的,比第一次接触反射好了许多. 上次学习的链接,有一些反射用的基础语句.https://www.cnblog ...
- 【CSS学习】--- 文本水平对齐属性text-align和元素垂直对齐属性vertical-align
一.文本水平对齐属性---text-align text-align属性是将块级标签以及单元格里面的内容进行相应的对齐,块级标签里的内联元素会被整体进行移动,而子块级元素或子单元格则会继承父元素的te ...
- python中经典类和新式类的区别
要知道经典类和新式类的区别,首先要掌握类的继承.类的继承的一个优点就是减少代码,而且使代码看起来结构很完整. 那什么是经典类,什么是新式类呢? 经典类和新式类的主要区别就是类的继承的方式 ,经典类遵循 ...
- IBM沃森会成为第一个被抛弃的AI技术吗?
作者|William Vorhies 译者|姚佳灵 编辑|Debra 导读:IBM 的沃森问答机(Question Answering Machine,简称 QAM),因 2011 年参加综艺节目&l ...
- Spring Data Redis 让 NoSQL 快如闪电(2)
[编者按]本文作者为 Xinyu Liu,文章的第一部分重点概述了 Redis 方方面面的特性.在第二部分,将介绍详细的用例.文章系国内 ITOM 管理平台 OneAPM 编译呈现. 把 Redis ...