skip-thought vector 实现Sentence2vector
1、常见文本相似度计算方法
常见的短文本相似度计算方法目前有很多中,但这些短文本相似度计算方法都只是提取了短文本中的浅层特征,而无法提取短文本中的深层特征。目前常见的文本相似度计算方法有:
1)简单共有词。对文本分词之后,计算两本文本中相同词的数量,然后除以更长的文本中词的数量。
2)编辑距离。简单理解就是指两个字符串之间,由一个字符串转成另一个字符串所需的最少编辑操作次数。
3)TF-ITF +余弦相似度/距离计算方法。利用TF-ITF提取关键词,将文本转换成向量空间模型,然后计算两个文本在向量空间中的余弦相似度或者之间的距离(常见的距离有曼哈顿距离、欧几里得距离)。
4)Jaccard系数。对文本分词后,对两个文本进行交集和并集的处理,用交集中词的数量除以并集中词的数量来表示两个文本之间的相似度。
5)主题模型。基于LDA和LSA主题模型提取文档的主题(推荐基于统计的LDA主题模型),然后根据主题向量的余弦相似度来表示两个文本之间的相似度。
对于短文本除了所具有的浅层特征之外,还有很对深层特征,比如句子的语义,语法等。基于目前很火的 word2vec 可以很好的计算两个词之间的相似度,目前也有将word2vec运用到句子相似度计算上来。比如常见的方法有:
1)对句子进行分词,得到每个词的向量表示,然后将这些向量进行叠加生成一个新的向量,将这个新的向量作为该句子的向量。通过余弦相似度或者欧几里得距离来计算相似度。
2)针对第1种,在向量叠加时还可以给每个词加上权重系数,以此来区分重要词和非重要词。
3)将句子当做词放入到word2vec模型中直接训练出句子的向量表示。
2、skip-thought vectors 论文解读
2.1 skip-thought模型结构
skip-thought模型结构借助了skip-gram的思想。在skip-gram中,是以中心词来预测上下文的词;在skip-thought同样是利用中心句子来预测上下文的句子,其数据的结构可以用一个三元组表示 $(s_{t-1}, s_t, s_{t+1})$ ,输入值 $s_t$ ,输出值 $(s_{t-1}, s_{t+1})$ ,具体模型结构如下图:

途中 $<eos>$ 表示句子的结尾。在这里:
$s_{t}\quad I\;could\;see\;the\;cat\;on\;the\;steps$
$s_{t-1}\quad I\;got\;back\;home$
$s_{t+1} \quad This\;was\;strange$
2.2 神经网络结构
skip-thought模型的神经网络结构是在机器翻译中最常用的 Encoder-Decoder 架构,而在 Encoder-Decoder 架构中所使用的模型是GRU模型(具体GRU模型见这篇)。因此在训练句子向量时同样要使用到词向量,编码器输出的结果为句子中最后一个词所输出的向量。具体模型实现的公式如下:
编码阶段:
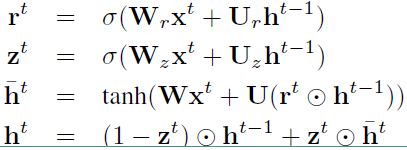
公式和GRU网络中的公式一模一样。$h_t$ 表示 $t$ 时刻的隐层的输出结果。
解码阶段:以 $s_{t+1}$ 为例,$s_{t-1}$ 相同:
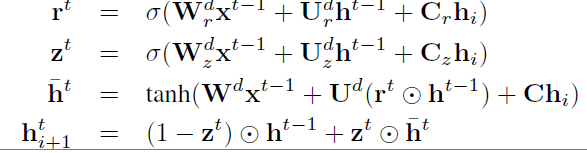
其中 $C_r, C_z, C$ 分别用来对重置门,更新门,隐层进行向量偏置的。
2.3 词汇扩展
词汇扩展主要是为了弥补我们的 Decoder 模型中词汇不足的问题。具体的做法就是:
1)我们用 $V_{w2v}$ 表示我们训练的词向量空间,用 $V_{rnn}$ 表示我们模型中的词向量空间,在这里 $V_{w2v}$ 是远远大于 $V_{rnn}$ 的。
2)引入一个矩阵 $W$ 来构建一个映射函数:$f: V_{w2v} -> V_{rnn}$ 。使得有 $ v^{'} = Wv $ ,其中 $ v \in V_{w2v}, v^{'} \in V_{rnn} $ 。
3)通过映射函数就可以将任何在 $V_{w2v}$ 中的词映射到 $V_{rnn}$ 中。
3、Tensorflow实现skip-thought
skip-thought已经添加到Tensorflow models中,只需要安装TensorFlow models就可以使用,具体安装流程:
1)在GitHub上下载源码:git clone --recurse-submodules https://github.com/tensorflow/models
2)将源码放到相应的位置:例如我是在Anaconda3中的虚拟环境下安装的tensorflow,则相应的路径:C:\Users\jiangxinyang\Anaconda3\envs\jiang\Lib\site-packages\tensorflow
具体GitHub地址:https://github.com/tensorflow/models/tree/master/research/skip_thoughts
skip-thought vector 实现Sentence2vector的更多相关文章
- 嵌入式Linux驱动学习之路(五)u-boot启动流程分析
这里说的u-boot启动流程,值得是从上电开机执行u-boot,到u-boot,到u-boot加载操作系统的过程.这一过程可以分为两个过程,各个阶段的功能如下. 第一阶段的功能: 硬件设备初始化. 加 ...
- 基于devkit8600的2011.04版uboot启动代码Start.s分析
/* * armboot - Startup Code for OMAP3530/ARM Cortex CPU-core * * Copyright (c) 2004 Texas Instrument ...
- 基于友善之臂ARM-tiny4412--uboot源码分析
/* * armboot - Startup Code for OMAP3530/ARM Cortex CPU-core * * Copyright (c) 2004 Texas Instrument ...
- 4412 uboot启动分析
感谢sea1105, https://blog.csdn.net/sea1105/article/details/52142772 在学习过程中,由于tiny4412资料太过于少,因此参考210的视屏 ...
- [LintCode/LeetCode]——两数和、三数和、四数和
LintCode有大部分题目来自LeetCode,但LeetCode比较卡,下面以LintCode为平台,简单介绍我AC的几个题目,并由此引出一些算法基础. 1)两数之和(two-sum) 题目编号: ...
- I.MX6 U-boot lvds display hacking
/*********************************************************************************** * I.MX6 U-boot ...
- 基于友善之臂ARM-tiny4412--uboot源代码分析
/* * armboot - Startup Code for OMAP3530/ARM Cortex CPU-core * * Copyright (c) 2004 Texas Instrument ...
- Codeforces 246E Blood Cousins Return(树上启发式合并)
题目链接 Blood Cousins Return #include <bits/stdc++.h> using namespace std; #define rep(i, a, b) f ...
- uboot学习之uboot-spl的程序流程分析
uboot-spl的程序流程主要包含下面的几个函数: _start->reset->save_boot_params->cpu_init_crit->lowlevel_init ...
随机推荐
- windows 上用 docker 部署aspnetcore 2.0
首先下载docker for windows 并且 安装. 这其中需要显卡支持虚拟化 windows系统升级到专业版 bois 启用虚拟 通过vs2017 创建一个net core ap ...
- Vue2+VueRouter2+webpack 构建项目实战(五):配置子路由
前言 通过前面几章的实战,我们已经顺利的构建项目,并且从API接口获取到数据并且渲染出来了.制作更多的页面,更复杂的应用,就是各位自己根据自己的项目去调整的事情了. 本章讲一下如何配置子路由,因为我们 ...
- Nginx 图片服务器
文件服务器:后台如果是集群,每次请求都会到不同的服务器,所以每台服务器的图片文件等都要做同步处理,才能保证每次用户不管访问到哪台服务器都能获取一样的资源.这种做法开销会很大,专门使用 nginx 作为 ...
- loadrunner 脚本优化-参数化之Parameter List参数同行取值
脚本优化-参数化之Parameter List参数同行取值 by:授客 QQ:1033553122 select next row 记录选择方式 Same line as,这个选项只有当参数多余一个时 ...
- jquery带参插件函数的编写
<!DOCTYPE html><html><head lang="en"> <meta charset="UTF-8" ...
- 「Android」系统架构概述
目录: 1.Android系统架构 2.Android类库 3.四大组件 --------------------------------------------------------------- ...
- 不需要再手写 onSaveInstanceState 了,因为你的时间非常值钱
如果你是一个有经验的 Android 程序员,那么你肯定手写过许多 onSaveInstanceState 以及 onRestoreInstanceState 方法用来保持 Activity 的状态, ...
- [katalon] 页面切换
UI自动化测试过程中会涉及到需要切换多个页面, 如点击一个按钮之后跳转到新的页面, 后者A站点提交信息后,B站点审核. Katalon虽然不支持控制多个浏览器,但是支持处理tab切换. 核心方法是使用 ...
- [20170603]12c Top Frequency histogram.txt
---恢复内容开始--- [20170603]12c Top Frequency histogram.txt --//个人对直方图了解很少,以前2种直方图类型对于目前的许多应用来讲已经足够,或者讲遇到 ...
- Spring入门详细教程(一)
一.spring概述 Spring是一个开放源代码的设计层面框架,他解决的是业务逻辑层和其他各层的松耦合问题,因此它将面向接口的编程思想贯穿整个系统应用.Spring是于2003 年兴起的一个轻量级的 ...