python3 urllib及requests基本使用
在python中,urllib是请求url连接的标准库,在python2中,分别有urllib和urllib,在python3中,整合成了一个,称谓urllib
1、urllib.request
request主要负责构建和发起网络请求
1)GET请求(不带参数)
response = urllib.request.urlopen(url,data=None, [timeout, ]*)
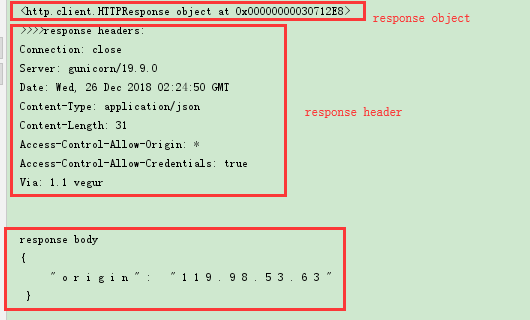
返回的response是一个http.client.HTTPResponse object
response操作:
a) response.info() 可以查看响应对象的头信息,返回的是http.client.HTTPMessage object
b) getheaders() 也可以返回一个list列表头信息
c) response可以通过read(), readline(), readlines()读取,但是获得的数据是二进制的所以还需要decode将其转化为字符串格式。
d) getCode() 查看请求状态码
e) geturl() 获得请求的url
>>>>>>>
2)GET请求(带参数)
需要用到urllib下面的parse模块的urlencode方法
param = {"param1":"hello", "param2":"world"}
param = urllib.parse.urlencode(param) # 得到的结果为:param2=world¶m1=hello
url = "?".join([url, param]) # http://httpbin.org/ip?param1=hello¶m2=world
response = urllib.request.urlopen(url)
3)POST请求:
urllib.request.urlopen()默认是get请求,但是当data参数不为空时,则会发起post请求
传递的data需要是bytes格式
设置timeout参数,如果请求超出我们设置的timeout时间,会跑出timeout error 异常。
param = {"param1":"hello", "param2":"world"}
param = urllib.parse.urlencode(param).encode("utf8") # 参数必须要是bytes
response = urllib.request.urlopen(url, data=param, timeout=10)
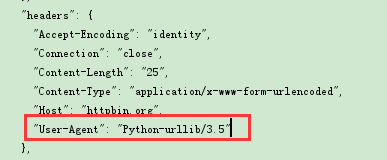
4)添加headers
通过urllib发起的请求,会有一个默认的header:Python-urllib/version,指明请求是由urllib发出的,所以遇到一些验证user-agent的网站时,我们需要伪造我们的headers
伪造headers,需要用到urllib.request.Request对象
headers = {"user-agent:"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)


对于爬虫来说,如果一直使用同一个ip同一个user-agent去爬一个网站的话,可能会被禁用,所以我们还可以用用户代理池,循环使用不同的user-agent
原理:将各个浏览器的user-agent做成一个列表,然后每次爬取的时候,随机选择一个代理去访问
uapool = ["谷歌代理", 'IE代理', '火狐代理',...]
curua = random.choice(uapool)
headers = {"user-agent": curua}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)
5)添加cookie
为了在请求的时候,带上cookie信息,需要构造一个opener
需要用到http下面的cookiejar模块
from http import cookiejar
from urllib import request
a) 创建一个cookiejar对象
cookie = cookiejar.CookieJar()
b) 使用HTTPCookieProcessor创建cookie处理器
cookies = request.HTTPCookieProcessor(cookie)
c) 以cookies处理器为参数创建opener对象
opener = request.build_opener(cookies)
d) 使用这个opener来发起请求
resp = opener.open(url)
e) 使用opener还可以将其设置成全局的,则再使用urllib.request.urlopen发起的请求,都会带上这个cookie
request.build_opener(opener)
request.urlopen(url)
6)IP代理
使用爬虫来爬取数据的时候,常常需要隐藏我们真实的ip地址,这时候需要使用代理来完成
IP代理可以使用西刺(免费的,但是很多无效),大象代理(收费)等
代理池的构建可以写固定ip地址,也可以使用url接口获取ip地址
固定ip:
from urllib import request
import random
ippools = ["36.80.114.127:8080","122.114.122.212:9999","186.226.178.32:53281"]
def ip(ippools):
cur_ip = random.choice(ippools)
# 创建代理处理程序对象
proxy = request.ProxyHandler({"http":cur_ip})
# 构建代理
opener = request.build_opener(proxy, request.HttpHandler)
# 全局安装
request.install_opener(opener)
for i in range(5):
try:
ip(ippools)
cur_url = "http://www.baidu.com"
resp = request.urlopen(cur_url).read().decode("utf8")
excep Exception as e:
print(e)
使用接口构建IP代理池(这里是以大象代理为例)
def api():
all=urllib.request.urlopen("http://tvp.daxiangdaili.com/ip/?tid=订单号&num=获取数量&foreign=only")
ippools = []
for item in all:
ippools.append(item.decode("utf8"))
return ippools
其他的和上面使用方式类似
7)爬取数据并保存到本地 urllib.request.urlretrieve()
如我们经常会需要爬取一些文件或者图片或者音频等,保存到本地
urllib.request.urlretrieve(url, filename)
8)urllib的parse模块
前面第2)中,我们用到了urllib.parse.urlencode()来编码我们的url
a)urllib.parse.quote()
这个多用于特殊字符的编码,如我们url中需要按关键字进行查询,传递keyword='诗经'
url是只能包含ASCII字符的,特殊字符及中文等都需要先编码在请求
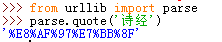
要解码的话,使用unquote
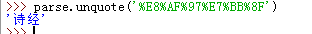
b)urllib.parse.urlencode()
这个通常用于多个参数时,帮我们将参数拼接起来并编译,向上面我们使用的一样

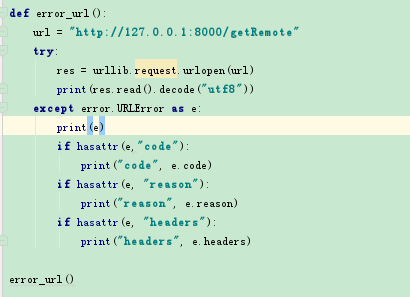
9)urllib.error
urllib中主要两个异常,HTTPError,URLError,HTTPError是URLError的子类
HTTPError包括三个属性:
code:请求状态码
reason:错误原因
headers:请求报头
2、requests
requests模块在python内置模块上进行了高度的封装,从而使得python在进行网络请求时,变得更加人性化,使用requests可以轻而易举的完成浏览器可有的任何操作。
1)get:
requests.get(url) #不带参数的get请求
requests.get(url, params={"param1":"hello"}) # 带参数的get请求,requests会自动将参数添加到url后面
2)post:
requests.post(url, data=json.dumps({"key":"value"}))
3)定制头和cookie信息
header = {"content-type":"application/json","user-agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
cookie = {"cookie":"cookieinfo"}
requests.post(url, headers=header, cookie=cookie)
requests.get(url, headers=header, cookie=cookie)
4)返回对象操作:
使用requests.get/post后会返回一个response对象,其存储了服务器的响应内容,我们可以通过下面方法读取响应内容
resp = requests.get(url)
resp.url # 获取请求url
resp.encoding # 获取当前编码
resp.encoding='utf8' # 设置编码
resp.text # 以encoding解析返回内容。字符串形式的响应体会自动根据响应头部的编码方式进行解码
resp.content # 以字节形式(二进制)返回。字节方式的响应体,会自动解析gzip和deflate压缩
resp.json() # requests中内置的json解码器。以json形式返回,前提是返回的内容确实是json格式的,否则会报错
resp.headers # 以字典形式存储服务器响应头。但是这个字典不区分大小写,若key不存在,则返回None
resp.request.headers # 返回发送到服务器的头信息
resp.status_code # 响应状态码
resp.raise_for_status() # 失败请求抛出异常
resp.cookies # 返回响应中包含的cookie
resp.history # 返回重定向信息。我们可以在请求时加上allow_redirects=False 来阻止重定向
resp.elapsed # 返回timedelta,响应所用的时间
具体的有哪些方法或属性,可以通过dir(resp)去查看。
5)Session()
会话对象,能够跨请求保持某些参数。最方便的是在同一个session发出的所有请求之间保持cookies
s = requests.Session()
header={"user-agent":""}
s.headers.update(header)
s.auth = {"auth", "password"}
resp = s.get(url)
resp1 = s.port(url)
6)代理
proxies = {"http":"ip1", "https":"ip2"}
requests.get(url, proxies=proxies)
7)上传文件
requests.post(url, files={"file": open(file, 'rb')})
把字符串当做文件上传方式:
requests.post(url, files={"file":('test.txt', b'hello world')}}) # 显示的指明文件名为test.txt
8)身份认证(HTTPBasicAuth)
from requests.auth import HTTPBasicAuth
resp = request.get(url, auth=HTTPBasicAuth("user", "password"))
另一种非常流行的HTTP身份认证形式是摘要式身份认证
requests.get(url, HTTPDigestAuth("user", "password"))
9)模拟登陆GitHub demo
from bs4 import BeautifulSoup
# 访问登陆界面,获取登陆需要的authenticity_token
url = "https://github.com/login"
resp = requests.get(url)
# 使用BeautifulSoup解析爬取的html代码并获取authenticity_token的值

s = BeautifulSoup(resp.text, "html.parser")
token = s.find("input", attrs={"name":"authenticity_token"}).get("value")
# 获取登陆需要携带的cookie
cookie = resp.cookies.get_dict()
# 带参数登陆
login_url = "https://github.com/session"

login_data = {
"commit":"Sign+in",
"utf8":"✓",
"authenticity_token":token,
"login":username,
"password":password
}
resp2 = requests.post(login_url, data=login_data, cookies=cookie)
# 获取登陆后的cookie
logged_cookie = resp2.cookies.get_dict()
# 携带cookie就可以访问你想要访问的任意网页了
requests.get(url, cookies=logged_cookie)
# 也可以把爬取的网页写入本地文件
with open(file, "w", encoding='utf8') as f:
f.write(resp2.text)
参考:https://www.cnblogs.com/ranxf/p/7808537.html
python3 urllib及requests基本使用的更多相关文章
- python3 urllib和requests模块
urllib模块是python自带的,直接调用就好,用法如下: 1 #处理get请求,不传data,则为get请求 2 import urllib 3 from urllib.request impo ...
- Python 网络请求模块 urllib 、requests
Python 给人的印象是抓取网页非常方便,提供这种生产力的,主要依靠的就是 urllib.requests这两个模块. urlib 介绍 urllib.request 提供了一个 urlopen 函 ...
- 爬虫小探-Python3 urllib.request获取页面数据
使用Python3 urllib.request中的Requests()和urlopen()方法获取页面源码,并用re正则进行正则匹配查找需要的数据. #forex.py#coding:utf-8 ' ...
- Python3.x:requests的用法
Python3.x:requests的用法 1,requests 比 urllib.request 容错能力更强: 2,通常用法: (1).认证.状态码.header.编码.json r = requ ...
- Python3 urllib.parse 常用函数示例
Python3 urllib.parse 常用函数示例 http://blog.51cto.com/walkerqt/1766670 1.获取url参数. >>> from url ...
- 浅谈urllib和requests
urllib和requests的学习 urllib requests 参考资料 urllib urllib是python的基本库之一,内置四大模块,即request,error,parse,robot ...
- 【Python爬虫实战--1】深入理解urllib;urllib2;requests
摘自:http://1oscar.github.io/blog/2015/07/05/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3urllib;urllib2;reques ...
- 【转】python3 urllib.request 网络请求操作
python3 urllib.request 网络请求操作 基本的网络请求示例 ''' Created on 2014年4月22日 @author: dev.keke@gmail.com ''' im ...
- Python3 urllib.request库的基本使用
Python3 urllib.request库的基本使用 所谓网页抓取,就是把URL地址中指定的网络资源从网络流中读取出来,保存到本地. 在Python中有很多库可以用来抓取网页,我们先学习urlli ...
随机推荐
- CsQuery获取IDomObject元素的完整CSS选择器
一.方法说明 通过IDomObject元素,获取完整的CSS选择器,过滤HTML和BODY元素,自动将class.id添加到选择器上,优先添加class,无class再添加id.如: <html ...
- 前端AntD框架的upload组件上传图片时遇到的一些坑
前言 本次做后台管理系统,采用的是 AntD 框架.涉及到图片的上传,用的是AntD的 upload 组件. 前端做文件上传这个功能,是很有技术难度的.既然框架给我们提供好了,那就直接用呗.结果用的时 ...
- windows虚拟内存机制
在windows系统中个,每个进程拥有自己独立的虚拟地址空间(Virtual Address Space).这一地址空间的大小与计算机硬件.操作系统以及应用程序都有关系. 对于32位程序来说,最多能使 ...
- Markdonw基本语法学习
Markdonw基本语法 二级标题 三级标题 ----ctrl+r 粗体 ctrl+b 斜体 ctr+i #include<stdio.h> void main() { printf(&q ...
- 自动化测试基础篇--Selenium多窗口、句柄问题
摘自https://www.cnblogs.com/sanzangTst/p/7680402.html 有时我们在打开浏览器浏览网页时,当点击网页上某些链接时,它不是直接在当前页面上跳转,而是重新打开 ...
- 【Git学习二】深入了解git checkout命令
检出命令(git checkout)是Git最常用的命令之一,同时也是一个很危险的命令,因为这条命令会重写工作区.检出命令的用法如下: 用法一:git checkout[-q][<commit& ...
- 微信小程序跳转微信小程序新增配置项目 navigateToMiniProgramAppIdList
每个小程序可跳转的其他小程序数量限制为不超过 10 个 从 2.4.0 版本以及指定日期(具体待定)开始,开发者提交新版小程序代码时,如使用了跳转其他小程序功能,则需要在代码配置中声明将要跳转的小程序 ...
- Python的datetime模块分析
datetime模块用于是date和time模块的合集,datetime有两个常量,MAXYEAR和MINYEAR,分别是9999和1. datetime模块定义了5个类,分别是 1.datetime ...
- 【vue】使用localStorage解决vuex在页面刷新后数据被清除的问题
通常,我们在使用vue编写页面时,会需要使用vuex在组件间传递(或者说共同响应)同一个数据的变化.例如:用户的登录信息. 下面,我们使用传递用户登录信息的例子来一步步解决这个问题. 首先,我们的第一 ...
- A - 畅通工程续 最短路
某省自从实行了很多年的畅通工程计划后,终于修建了很多路.不过路多了也不好,每次要从一个城镇到另一个城镇时,都有许多种道路方案可以选择,而某些方案要比另一些方案行走的距离要短很多.这让行人很困扰. 现在 ...