Java中堆内存和栈内存的区别
Java把内存分成两种,一种叫做栈内存,一种叫做堆内存。
在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配。当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用。
堆内存用于存放由new创建的对象和数组。在堆中分配的内存,由java虚拟机自动垃圾回收器来管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象,引用变量相当于为数组或者对象起的一个别名,或者代号。
引用变量是普通变量,定义时在栈中分配内存,引用变量在程序运行到作用域外释放。而数组&对象本身在堆中分配,即使程序运行到使用new产生数组和对象的语句所在地代码块之外,数组和对象本身占用的堆内存也不会被释放,数组和对象在没有引用变量指向它的时候,才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因,实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
示例1如下:
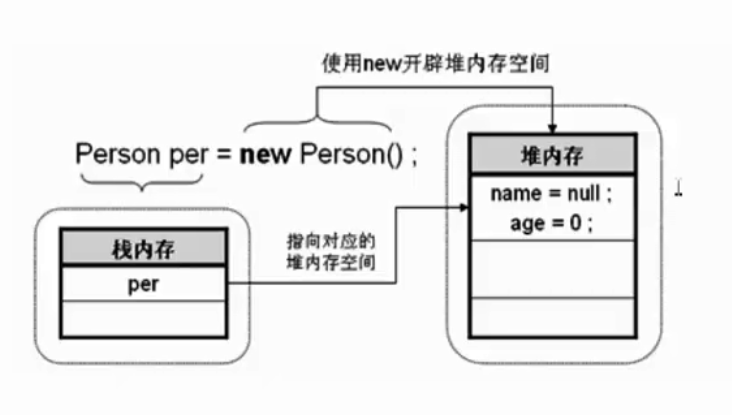
Person per = new Person();
//这其实是包含了两个步骤,声明和实例化
Person per = null; //声明一个名为Person类的对象per
per = new Person(); // 实例化这个per对象
声明 指的是创建类的对象的过程;
实例化 指的是用关键词new来开辟内存空间。
它们在内存中的划分是这样的:
那什么是栈内存(heap)和栈内存(heap)呢?
栈内存:
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。栈内存主要存放的是基本类型类型的数据 如( int, short, long, byte, float, double, boolean, char) 和对象句柄。注意:并没有String基本类型、在栈内存的数据的大小及生存周期是必须确定的、其优点是寄存速度快、栈数据可以共享、缺点是数据固定、不够灵活。
栈的共享:
String str1 = "myString"; String str2 = "myString"; System.out.println(str1 ==str2 ); //注意:这里使用的是str1 ==str2,而不是str1.equals(str2)的方式。 //因为根据JDK的说明,==号只有在两个引用都指向了同一个对象时才返回真值 //而str1.equals(str2),只是比较两个字符串是否相等
结果为True,这就说明了str1和str2其实指向的是同一个值。
上述代码的原理是,首先在栈中创建一个变量为str1的引用,然后查找栈中是否有myString这个值,如果没找到,就将myString存放进来,然后将str1指向myString。接着处理String str2 = "myString";;在创建完str2 的引用变量后,因为在栈中已经有myString这个值,便将str2 直接指向myString。这样,就出现了str1与str2 同时指向myString。
特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完str1与str2 的值后,再令str1=yourString;那么,str2不会等于yourString,还是等于myString。在编译器内部,遇到str1=yourString;时,它就会重新搜索栈中是否有yourString的字面值,如果没有,重新开辟地址存放yourString的值;如果已经有了,则直接将str1指向这个地址。因此str1值的改变不会影响到str2的值。
堆内存:
堆内存用来存放所有new 创建的对象和 数组的数据
String str1 = new String ("myString");
String str2 = "myString";
System.out.println(str1 ==str2 ); //False
String str1 = new String ("myString");
String str2 = new String ("myString");
System.out.println(a==b); //False
创建了两个引用,创建了两个对象。两个引用分别指向不同的两个对象。以上两段代码说明,只要是用new()来新建对象的,都会在堆中创建,而且其字符串是单独存值的,即使与栈中的数据相同,也不会与栈中的数据共享。
为了深入理解,添加了实例2:
public class Demo1 {
public static void main(String[] args) {
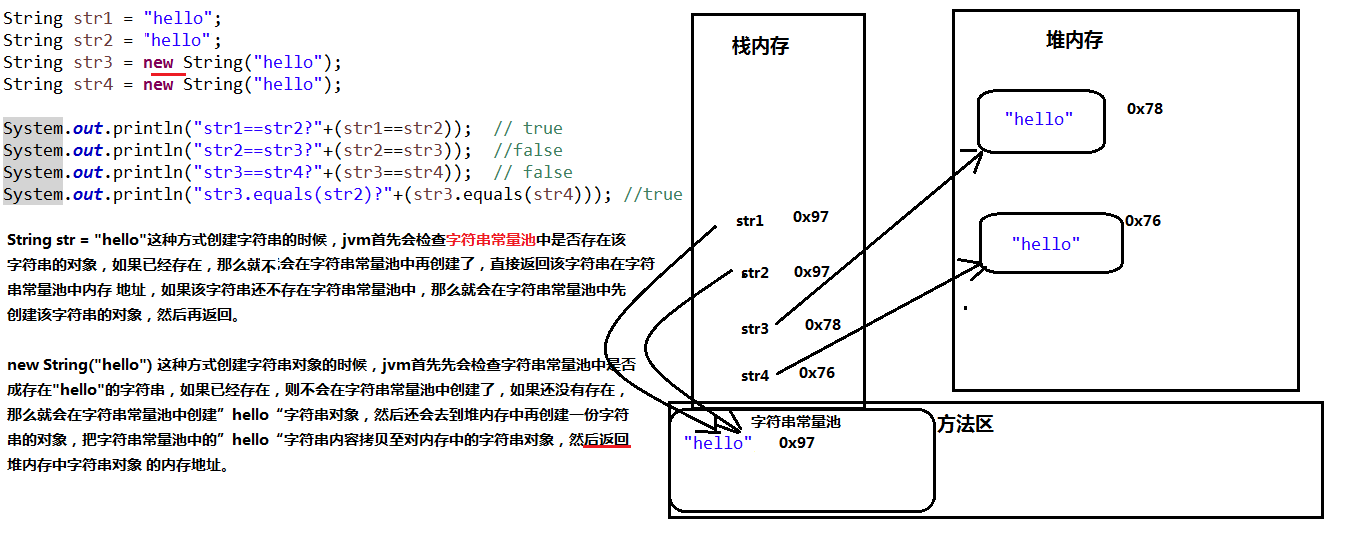
String str1 = "hello";
String str2 = "hello";
String str3 = new String("hello");
String str4 = new String("hello");
System.out.println("str1==str2?"+(str1==str2)); // true
System.out.println("str2==str3?"+(str2==str3)); //false
System.out.println("str3==str4?"+(str3==str4)); // false
System.out.println("str3.equals(str2)?"+(str3.equals(str4))); //true
//是String类重写了Object的equals方法,比较的是两个字符串对象 的内容 是否一致。
// "=="用于比较 引用数据类型数据的时候比较的是两个对象 的内存地址,equals方法默认情况下比较也是两个对象 的内存地址。
test(null);
}
}
实行原理如下:
Java中堆内存和栈内存的区别的更多相关文章
- Java中堆(heap)和栈(stack)的区别
简单的说: Java把内存划分成两种:一种是栈内存,一种是堆内存. 在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配. 当在一段代码块定义一个变量时,Java就在栈中为这个变量分 ...
- 转载C#中堆(heap)和栈(stack)的区别
转载原地址 http://www.cnblogs.com/wangshenhe/archive/2013/02/18/2916275.html [转]C#堆和栈的区别 理解堆与栈对于理解.NET中的 ...
- Java中堆内存和栈内存详解2
Java中堆内存和栈内存详解 Java把内存分成两种,一种叫做栈内存,一种叫做堆内存 在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配.当在一段代码块中定义一个变量时,ja ...
- 浅析JAVA中堆内存与栈内存的区别
Java把内存划分成两种:一种是栈内存,一种是堆内存. 一.栈内存 存放基本类型的变量,对象的引用和方法调用,遵循先入后出的原则. 栈内存在函数中定义的“一些基本类型的变量和对象的引用变量”都 ...
- Java SE之Java中堆内存和栈内存[转/摘]
[转/摘]1-3Java中堆内存和栈内存 注解:内存(Memory)即 内存储器,主存,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器(辅存)交换的数据. Java中把内存分为两种:栈 ...
- 熟悉java堆内存和栈内存和mysql的insert语句中含有id的处理
java的堆内存和栈内存有什么区别呢? 如果mysql数据库表的id是递增的,如果没有插入id,则id自增,如果插入id,则插入什么就显示什么.
- JAVA内存管理之堆内存和栈内存
我们常常做的是将Java内存区域简单的划分为两种:堆内存和栈内存.这种划分比较粗粒度,这种划分是着眼于我们最关注的.与对象内存分配密切相关的两类内存域.其中栈内存指的是虚拟机栈,堆内存指的是java堆 ...
- java堆内存和栈内存的处理
前段时间学习二叉树在处理删除操作的时候遇到一个头疼的问题:删除节点的时候明明已经置null了可树上该节点依旧存在,还必须执行node.father.left = null;才可以删除node节点,寻找 ...
- java堆内存与栈内存
java的内存分为两种,堆内存与栈内存: 堆内存用来存放数组和new的对象,比如一个文件,字节流是存放在堆中,栈内存为这个文件开辟一个索引,也就是这个文件的地址,并且保存在栈中.对象由GC处理释放内存 ...
- 浅析JS中的堆内存与栈内存
最近跟着组里的大佬面试碰到这么一个问题, Q:说说var.let.const的区别 A:balabalabalabla... Q:const定义的值能改么? A:你逗我?不能吧 不知道各位看官怎么想? ...
随机推荐
- DAC杂谈二 ——ADC和DAC常用技术术语
采集时间 采集时间是从释放保持状态(由采样-保持输入电路执行)到采样电容电压稳定至新输入值的1 LSB范围之内所需要的时间.采集时间(Tacq)的公式如下: 混叠 根据采样定理,超过奈奎斯特频率的输入 ...
- dubbo源码分析1——SPI机制的概要介绍
插件机制是Dubbo用于可插拔地扩展底层的一些实现而定制的一套机制,比如dubbo底层的RPC协议.注册中心的注册方式等等.具体的实现方式是参照了JDK的SPI思想,由于JDK的SPI的机制比较简单, ...
- html单选按钮用jQuery中prop()方法设置
模拟单选按钮时用jQuery,prop方法来设置. 赋默认选中值:$("#" + id).find("input:radio[value='" + state ...
- 获取图片的EXIF信息
对于专业的摄影师来说,Exif信息是很重要的信息,也包含了非常多的东西 1.EXIF EXIF(Exchangeable Image File)是“可交换图像文件”的缩写,当中包含了专门为数码相机的照 ...
- 【转】drop、truncate和delete的区别
(1)DELETE语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行回滚操作. TRUNCATE TABLE 则一次性地从表中删除所有的数据并不把单独的删 ...
- Java 处理 XML
DOM 优缺点:实现 W3C 标准,有多种编程语言支持这种解析方式,并且这种方法本身操作上简单快捷,十分易于初学者掌握.其处理方式是将 XML 整个作为类似树结构的方式读入内存中以便操作及解析,因此支 ...
- WebStorm 关联 TFS(转)
1.下载插件 TFS integration 2.链接TFS 服务器 3.创建工作区 4. 5.选择一个 工作环境 6.最重要的有点是在VCS里面要选择一个默认的提交方式!!!
- bean shell之间传递参数
BeanShell PostProcessor 向 BeanShell断言 传递参数 断言成功:
- IIS环境下部署https【转载】
1.首先我们要取走我们的证书,保存在我们本地的电脑里,然后复制到服务器即可. 2.取走后接下来干嘛?当然是打开文件看看里面有些什么啊.我们找到IIS那个压缩包并解压. 3.解析得到pfx文件,也就是我 ...
- T-SQL ORDER BY子句 排序方式
MS SQL Server ORDER BY子句用于根据一个或多个列以升序或降序对数据进行排序. 默认情况下,一些数据库排序查询结果按升序排列. 语法 以下是ORDER BY子句的基本语法. SELE ...