目标检测算法之YOLOv1与v2
YOLO:You Only Look Once(只需看一眼)
基于深度学习方法的一个特点就是实现端到端的检测,相对于其他目标检测与识别方法(如Fast R-CNN)将目标识别任务分成目标区域预测和类别预测等多个流程,YOLO将目标区域预测和类别预测整合到单个神经网络中,将目标检测任务看作目标区域预测和类别预测的回归问题。速度非常快,达到每秒45帧,而在快速YOLO(Fast YOLO,卷积层更少),可以达到每秒155帧。
与当前最好系统相比,YOLO目标区域定位误差更大,但是背景预测的假阳性(真实结果为假,算法预测为真)优于当前最好的方法。
一、YOLO的核心思想
1. YOLO的核心思想就是利用整张图作为网络的输入,直接在输出层回归bounding box(边界框)的位置及其所属类别
2. Faster R-CNN中也直接用整张图作为输入,但是Faster R-CNN整体还是采用了RCNN那种proposal + classifier的思想,只不过将提取proposal的步骤放在CNN中实现,而YOLO则采用直接回归的思路。
二、YOLO的实现方法
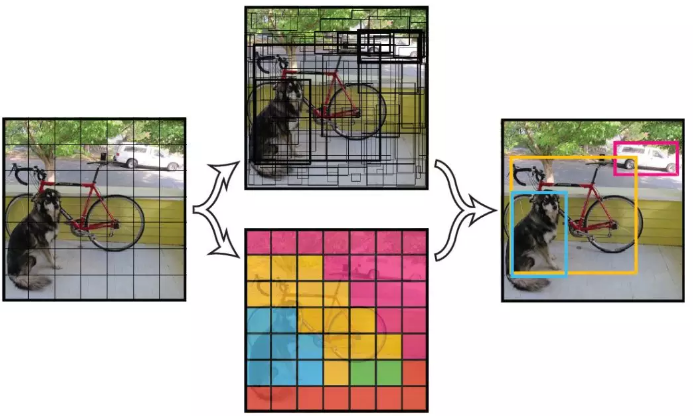
1. YOLO首先将图像分为SxS个网格(grid cell)。如果一个目标的中心落入格子,该格子就负责检测其目标。每一个网格中预测B个Bounding box和置信值(confidence score)。这个confidence代表了所预测的box中含有object的置信度和这个box预测的有多准这两重信息。置信值为:

如果有object落在grid cell里,第一项取1,否则取0。第二项是预测的bounding box和实际的groundtruth之间的IoU值。也就是说,如果有目标,置信值为IoU,如果没有,取0
2. 每一个bounding box包含5个值:x,y,w,h,和confidence。(x,y)坐标表示边界框相对于网格单元边界框的中心。宽度和高度相对于整张图像预测的。confidence表示预测的box与实际的groundtruth之间的IoU值。每个网格单元还预测C个条件类别概率:

这些概率是以网格包含目标为条件的,每个网格单元我们只预测一组类别概率,而不管边界框的数量B的多少。
3. 在测试时,我们乘以条件类概率和单个盒子的置信度预测:

在PASCAL VOC数据集上评价时,我们采用了S=7, B=2, C=20(该数据集包含20个类别),最终预测结果为
7x7x30(B*5 + C)的tensor

三、网络模型
网络有24个卷积层,后面是2个全连接层。使用1x1降维层(减少了前面层的特征空间),后面是3x3卷积层。我们在ImageNet分类任务上以一半的分辨率(224x224的输入图像)预训练卷积层,然后将分辨率加倍来进行检测。
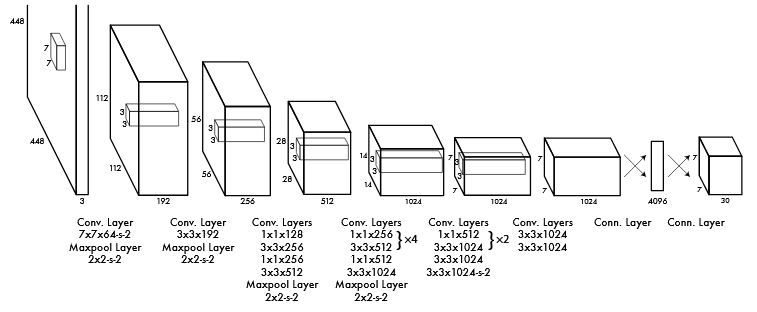
1+1+4+10+6+2=24个
可以看出,这个网络中主要采用了1x1卷积后跟着3x3卷积的方式。
特征提取网络采用了前20个卷积层,加一个avg-pooling层和一个全连接层,对ImageNet2012进行分类,top-5正确率为88%,输入为224x224
检测时,将输入分辨率改为448x448,因为网络结构是全卷积的,所以输入分辨率可以改变,整个网络输出为7x7x30维的tensor。
而快速版本的YOLO,旨在推动快速目标检测的界限。快速YOLO使用具有9层卷积,在这些层中使用较少的滤波器。除了网络规模之外,YOLO和Fast YOLO的所有训练和测试参数都是相同的。最终输出是7x7的预测张量。
四、损失函数
用网络直接回归物体的坐标是很难的,这里对要回归的物体的坐标进行了一些转换。物体方框的长w和宽h分别除以图片的长和宽;x和y坐标分别表示对应方格坐标的偏移,分别除以方格的长和宽;它们都在0到1之间
损失函数分为多个部分:

一些细节:
1. 最后一层激活函数使用线性激活函数,其它层使用leaky-Relu函数
2. 如果开始使用高学习率会不稳定,先从0.001到0.01,然后0.01训练75个epoch,接着0.001训练30个epoch,最后训练30个epoch
3. nms仅增加了2.3%的map
注意:
1. 由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率
2. 虽然每个格子可以预测B个bounding box,但是最终只选择IoU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占互勉比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷
3. YOLO方法模型训练依赖与物体识别标注数据,因此,对于非常规的物体形状或比例,YOLO的检测效果并不理想
4. YOLO采用了多个下采样层,网络学到的物体特征并不精细,因此也会影响检测效果
5. YOLO的损失函数中,大物体IoU误差和小物体IoU误差对网络训练中loss贡献值接近。因此,对于小物体,小的IoU误差也会对网络优化过程造成很大的影响,从而降低了物体检测的定位准确性。
五、YOLO的缺点
1. YOLO对相互靠的很近的物体,还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类
2. 同一类物体出现的新的不常见的长宽比和其他情况时,泛化能力较弱
3. 由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强
YOLOv2
YOLOv1基础上的延续,新的基础网络,多尺度训练,全卷积网络,Faster R-CNN的anchor机制,更多的训练技巧等等改进使得YOLOv2速度和精度都大幅提升,改进效果如下图:

1. BatchNorm
BatchNorm是2015年以后普遍比较流行的训练技巧,在每一层之后加入BN层可以将整个batch数据归一化到均值为0,方差为1的空间,即将所有层数据规范化,防止梯度消失与梯度爆炸,如:
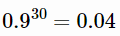
加入BN层训练之后效果就是网络收敛更快,并且效果更好。YOLOv2在加入BN层之后mAP上升2%。关于BN作用
2. 预训练尺寸
YOLOv1也在ImageNet预训练模型上进行fine-tune,但是预训练时网络入口为224x224,而fine-tune时为448x448,这会带来预训练网络与实际训练网络识别图像尺寸的不兼容。YOLOv2直接使用448x448的网络入口进行预训练,然后在检测任务上进行训练,效果得到3.7%的提升
3. 更细网络划分
YOLOv2为了提升小物体检测效果,较少网络中pooling数目,使最终特征图尺寸更大,如输入为416 x 416,则输出为13 x 13 x 125,其中13 x 13为最终特征图,即原图分格的个数,125为每个格子中的边界框构成(5 x (classes + 5))(416->208->104->52->26->13)
4. 全卷积网络
为了使网络能够接受多种尺寸的输入图像,YOLOv2除去了v1中的全连接层,因为全连接层必须要求输入输出固定长度特征向量。将整个网络编程一个全卷积网络,能够对多种尺寸输入进行检测。同时,全卷积网络相对于全连接层能够更好的保留目标的空间位置信息。
5. 新基础网络
下图为不同基础网络结构做分类任务。横坐标为做一次前向分类任务所需要的操作数目。可以看出darknet-19作为预训练网络(共19个卷积层),能在保持高精度的情况下快速运算。而SSD使用的VGG-16作为基础网络,VGG-16虽然精度与darknet-19相当,但运算速度慢。关于darknet-19基础网络速度

darknet-19的网络结构如下:
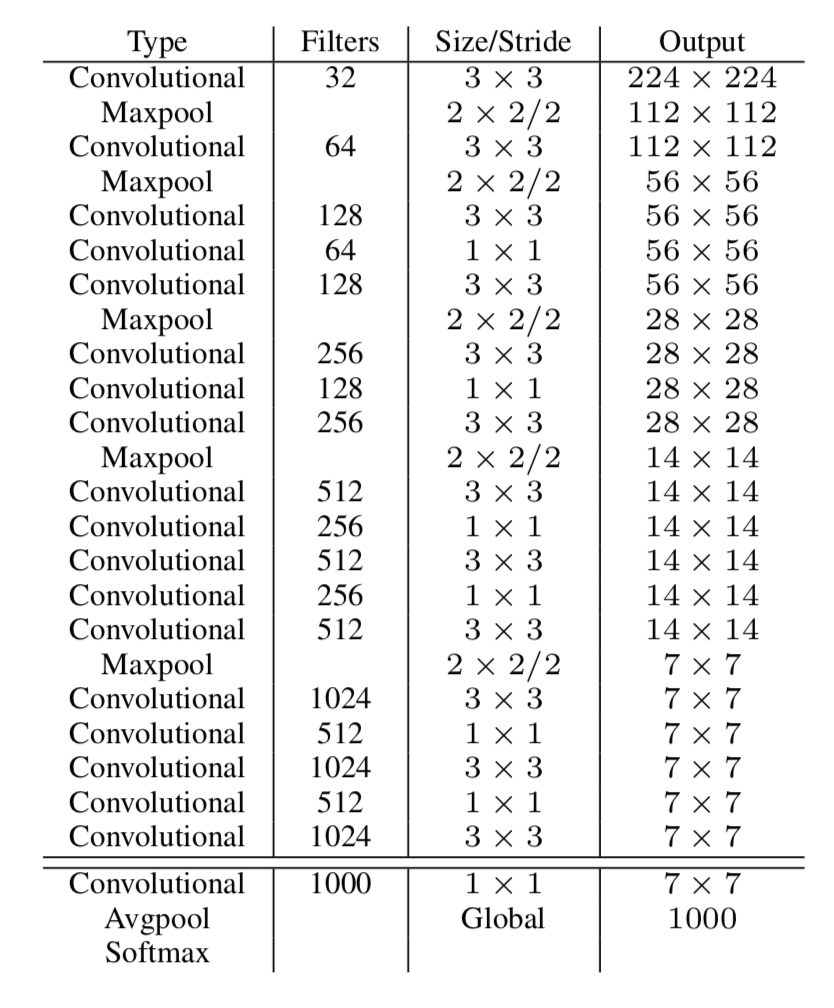
修改成detection网络时,删除了最后的卷积层,添加了3个3 x 3 x 1024的卷积层,和一个1 x 1 x 125的卷积层,在最后的3 x 3 x 512层和导数第二层之间添加了一个paththrough进行特征concat
6. anchor机制
YOLOv2为了提高精度和召回率,使用Faster R-CNN中的anchor机制。在每个网格设置k个参考anchor,训练以GT anchor作为基准计算分类与回归损失。测试时直接在每个格子上预测k个anchor box,每个anchor box为相对于参考anchor的offset与w,h的refine。这样把原来每个格子中边界框位置的全图回归(YOLOv1)转换为参考anchor位置的精修(YOLOv2)。至于每个格子中设置多少个anchor(k等于几),作者使用了k-means算法离线对voc及coco数据集中目标的形状及尺度进行了计算。发现k = 5时并且选取固定5比例值时,anchors形状及尺度最接近voc与coco中目标的形状,k不能取太大,否则模型太复杂,计算量很大
7. 残差融合低级特征
为了使网络能够更好检测小物体,作者使用了resnet跳级层结构,网络末端的高级特征与前一层或者前几层的低级细粒度特征结合起来,增加网络对小物体的检测效果,使用该方法能够将mAP提高1%。同样,SSD上也可以看出使用细粒度特征(低级特征)将进行小物体检测的思想,但是不同的是,SSD直接在多个低级特征图上进行目标检测。因此,SSD对于小目标检测效果要优于YOLOv2,这点可以在coco测试上看出,因此coco上小物体比较多,但YOLOv2在coco上要明显逊色于SSD,但在比较简单的检测数据集voc上要优于SSD

8. 多尺寸训练
YOLOv2为全卷积网络FCN,可以适合不同尺寸图片作为输入,但要满足模型在测试时能够对多尺度输入图像都有很好效果,作者训练过程中每10个epoch都会对网络进行新的输入尺寸训练。需要注意的是,因为全卷积网络总共对输入图像进行了5次下采样(步长为2的卷积或者池化层),所以最终特征图为原图的1/32。所以训练或者测试时,网络必须为32的位数。并且最终特征图尺寸即为原图划分网络的方式。
参考地址:
https://www.cnblogs.com/fariver/p/7446921.html
https://www.jianshu.com/p/f87be68977cb
目标检测算法之YOLOv1与v2的更多相关文章
- 目标检测算法的总结(R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD、FNP、ALEXnet、RetianNet、VGG Net-16)
目标检测解决的是计算机视觉任务的基本问题:即What objects are where?图像中有什么目标,在哪里?这意味着,我们不仅要用算法判断图片中是不是要检测的目标, 还要在图片中标记出它的位置 ...
- 基于COCO数据集验证的目标检测算法天梯排行榜
基于COCO数据集验证的目标检测算法天梯排行榜 AP50 Rank Model box AP AP50 Paper Code Result Year Tags 1 SwinV2-G (HTC++) 6 ...
- (六)目标检测算法之YOLO
系列文章链接: (一)目标检测概述 https://www.cnblogs.com/kongweisi/p/10894415.html (二)目标检测算法之R-CNN https://www.cnbl ...
- 基于模糊Choquet积分的目标检测算法
本文根据论文:Fuzzy Integral for Moving Object Detection-FUZZ-IEEE_2008的内容及自己的理解而成,如果想了解更多细节,请参考原文.在背景建模中,我 ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- FAIR开源Detectron:整合全部顶尖目标检测算法
昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标检测平台. 昨天,Facebook AI 研究院(FAIR)开源了 Detectron,业内最佳水平的目标 ...
- AI SSD目标检测算法
Single Shot multibox Detector,简称SSD,是一种目标检测算法. Single Shot意味着SSD属于one stage方法,multibox表示多框预测. CNN 多尺 ...
- 第二十九节,目标检测算法之R-CNN算法详解
Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmenta ...
- 目标检测算法之R-CNN算法详解
R-CNN全称为Region-CNN,它可以说是第一个成功地将深度学习应用到目标检测上的算法.后面提到的Fast R-CNN.Faster R-CNN全部都是建立在R-CNN的基础上的. 传统目标检测 ...
随机推荐
- Linux系统安全学习笔记(1)-- 文件系统类型
今天看了一个关于Linux系统安全的视频教程,这个教程有很多的知识点,我会分几篇博文将我的笔记分享出来. 首先是关于Linux文件系统类型的一些知识,Linux有四种常见的文件系统类型(网上大多数是3 ...
- roslaunch & gdb 调试指南(待补充)
1. 安装xterm sudo apt-get install xterm 2. 在launch文件中添加如下内容: <node name="navigation" pkg= ...
- 统计分析与R软件-chapter2-5
2.5 多维数组和矩阵 2.5.1 生成数组或矩阵 数组有一个特征属性叫做维数向量(dim属性),维数向量是一个元素取正整数的向量,其长度是数组的维数,比如维数向量有两个元素时数组为2维数组(矩阵). ...
- Windows PowerShell 入門(1)-基本操作編
Microsoftが提供している新しいシェル.Windows Power Shellの基本操作方法を学びます.インストール.起動終了方法.コマンドレット.命名規則.エイリアス.操作方法の調べ方について ...
- nginx 配置域名转发
自己测试环境,配置下载目录和一个jenkins的地址: 域名跳转,反向代理 # cat ../nginx.conf user www www; worker_processes ; error_log ...
- Xamarin AVD x86 问题
inspired by https://stackoverflow.com/questions/34282243/error-while-starting-emulator/34282302#3428 ...
- 解决tomcat报错javax.imageio.IIOException: Can't create output stream!
启动tomcat catalina.out报错如下,登陆的时候无法显示验证码 2017-06-09 11:23:06,628 DEBUG org.springframework.web.servlet ...
- 转-C语言中.h和.c文件解析
C语言中.h和.c文件解析(很精彩) 简单的说其实要理解C文件与头文件(即.h)有什么不同之处,首先需要弄明白编译器的工作过程,一般说来编译器会做以下几个过程: 1.预处理阶段 2.词 ...
- python并发(阻塞、非阻塞、epoll)
在Linux系统中 01 阻塞服务端 特征:1对1,阻塞. import socket server = socket.socket() #生成套接字对象 server.bind(('0.0.0.0' ...
- Day7--------------虚拟机网络服务
1.桥接 连接到本地的网卡,把本机的网卡看作是虚拟交换机 ping ip地址 arping -i eth0 192.168.11.11 返回物理MAC地址 #可以检查是否有重复 ...