学习SQL关联查询
通过一个小问题来学习SQL关联查询
原话题:

是关于一个left join的,没有技术难度,但不想清楚不一定能回答出正确答案来:
TabA表有三个字段Id,Col1,Col2 且里面有一条数据1,1,2
TabB表有两个字段Id,Col1且里面有四条数据
- 1,1
- 2,2
- 3,2
- 4,2
问题:

如下语句会返回多少条数据? 在不写测试脚本的情况下,如果你能在5分钟内准备回答出答案,且能说出些所以然来(及不是凭感觉猜出来的结果),那么请继续看后面的问题。
Select * from TabA a Left join TabB b1 on a.Col1=b1.Col1 Left join TabB b2 on a.Col2=b2.Col1 |
延深问题:
现在表A多增加一条数据2,3,4 ,此时再运行上面的语句会几条数据?如果你能在2分钟内回答出正常答案,那么请继续看后面的问题。
理论问题:
- 是否知道 sql server的join包含 hash匹配,嵌套循环以及合并联接?不同于left join, inner join的概念,属于执行计划中的概念。
- 上面三种的查询机制是否能画简单的示意图?
- 上面三种查询机制的应用场景是什么?即什么样的情况下适合应用三种中的哪一种?
我发现就上面这个问题不少人回答不正确,这其中也包括我自己。为什么如此简单的问题往往会回答错误,我认为可能有如下原因:
- 本身对SQL查询知识就很欠缺,比如不知道left join与inner join的区别等等;
- 平时工作中也写SQL查询,只知道怎么用,不知道稍微详细一点的细节;
- 没经过大脑思考,随口说的,往往仔细想想就能回答正确。
对于第一种情况的人,短时间内无法解决,只有通过自身的学习来补救,对于第二种情况的人就需要稍微学习一些基本的理论知识就够用,对于第三种情况的人是一个态度问题。
left join的概念
简单来讲就是以左表做为外层循环表,每条每条去内层表去查找匹配记录,如果找到就返回join好的值,如果没找到返回外层表的值,内层表统一赋值为null。这里之所以说成简单来讲,是因为我是拿嵌套循环的例子来分析,因为这比较容易让非SQL方面的程序员明白,毕竟对于.net程序员来讲编写双层或者多层循环的例子会很多。而对于hash匹配以及合并联接的应用场景在.net程序中相对较少,类似如下的双层循环。

foreach(var colA in tabA)
{
foreach(var colB in tabB)
{
if(colA==colB)
{
......
}
}
}
这里需要注意下,上面说到的外层表的记录循环去内层表查找时,这里有个问题,看这条语句:
Select * from TabA a Left join TabB b1 on a.Col1=b1.Col1 |
这里的TabA 就是我这里讲的外层表,TabB就是内层表,外层表就一行数据,内层表有4行数据,从上面给出的数据来看,用来做等值判断的条件是外层表的Col1字段与内层表的Col1字段,拿外层表的Cole=1这行数据去内层表查询时,内层表的第一条数据符合条件,其它三条不符合,此时的结果会是下面的哪一种呢?
- 4条记录
a.Id a.Col1 a.Col2 b.Id b.Col1
1 1 2 1 1
1 1 2 null null
1 1 2 null null
1 1 2 null null
- 一条记录
a.Id a.Col1 a.Col2 b.Id b.Col1
1 1 1 2 1
这要理解当在内层表中找到数据以及找不到数据的区别,我们拿外层表Col1=1这条数据去内层表查找时,需要查找4次,其中有一条符合,三条不符合,这说明找到了匹配数据,所以只返回匹配的数据行,即一条数据,而不会出现上面的第一种结果返回4条数据。

这是我当时遇到这个问题时产生的误解。
再看后面的那个left join
Select * from TabA a Left join TabB b1 on a.Col1=b1.Col1 Left join TabB b2 on a.Col2=b2.Col1 |
容易产生的问题,再进行第二次left join 的时候,外层表是TabA原始表呢还是第一次left join 之后的结果集呢? 看下我列出来的表头,就很容易理解了,这里的a.Col2就是第一次left join后的结果集。( a.Id a.Col1 a.Col2 b.Id b.Col1)
我们可以做下测试,这里使用inner join来做测试,因为这加容易比较出差异,运行下面的语句,此时TabA中有两条数据,就是上面延深问题中添加的2,3,4这条。
Select * from TabA a inner join TabB b1 on a.Col1=b1.Col1 inner join TabB b2 on a.Col2=b2.Col1 |
分两步来看:
Select * from TabA a inner join TabB b1 on a.Col1=b1.Col1 |
这里只会返回一条数据,因为inner join返回的交集。
a.Id a.Col1 a.Col2 b.Id b.Col1
1 1 2 1 1
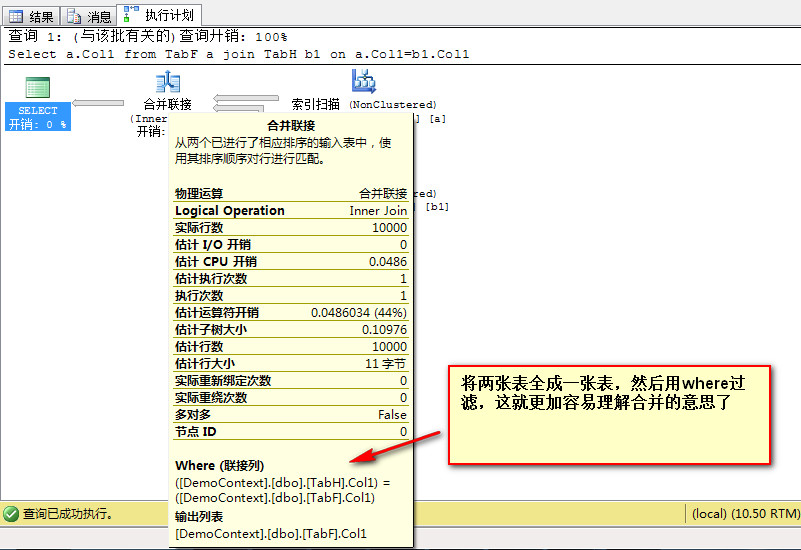
如果第二次join 时,如果连接的是原始表TablA,那么循环查询的次数应该是TabA的总条数2,但从下面的执行计划图可以分析出执行顺序。
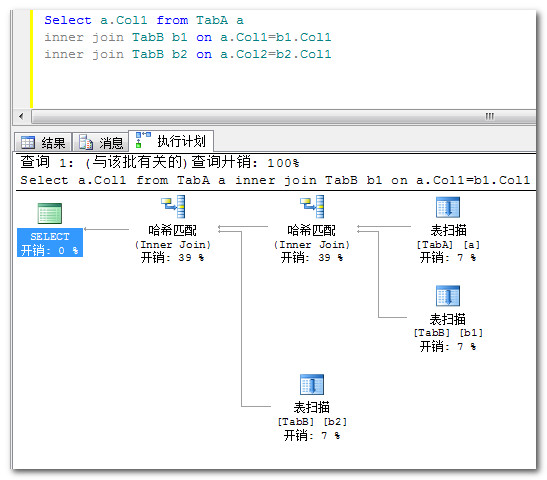
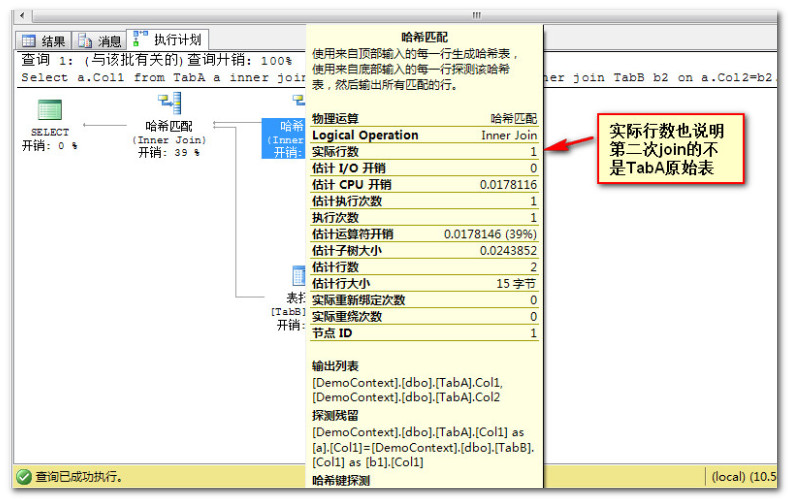
- 上图一的结构图很明显,第二次join的是第一次join的结果集而不是原始表TabA。
- 上图二的实际行数也足以说明关联的不是原始表TabA
解决了上面两个问题,那么应该能容易分析出文章前面提到的两个问题的答案了。但这只是解决了一个小问题,如果从学习的角度来讲我们应该通过这一个问题来将其周边涉及的主要知识都学习一下,这里我们非常有必要了解了执行计划的join分类。
Join在执行计划中的分类
我只是简单的对这三种分类做简单的概述,后续为这三种join分别进行稍微详细点的总结。执行计划中的三种Join各有各的优缺点,不能说哪一种绝对是最好的,也不能说哪一种能够适用于所有的查询应用场景,我下面提供的常见应用场景只是一些案例,且是有运行环境的,因为执行计划的选择非常复杂,有时只要有一个环境因素不同就会造成执行计划的不同,比如会受到下面因素的因素的影响:
- 数据量,当数据量比较小时可能是一种执行计划,当数据量慢慢增大时执行计划可能会发生改变。
- join关联的不同也会使执行计划发生改变,比如用inner join与left join时产生的执行计划有可能是不同的。

Hash匹配
常见适用场景:
- 条件列没有索引,这里说的条件列是关联表的所有关联键都没有索引
- 大数据表关联
约束条件:只能用于等值条件,比如a.Col1=b.Col1这种类型的,值的注意的是这里讲的等值条件,不是说所有的条件都需要是等值的,只有其中有一个是等值条件就行,比如下面这几种都符合等值条件:
Select * from TabA a inner join TabB b1 on a.Col1=b1.Col1 AND a.Col3 LIKE '%1%' |
上面提到的适用场景以及约束条件,不是绝对的,受很多其它因素影响,比如上面提到的join方式的不同,例如下面这两条SQL的执行计划就不同,这里就不贴图了,情况很复杂。
- 下面是嵌套查询
Select * from TabA aLeft join TabB b1 on <span style="color: #000000;">a.Col1=b1.Col1Left</span> join TabB b2 on a.Col2=b2.Col1 |
- 下面是Hash匹配
Select * from TabA ainner join TabB b1 on a.Col1=b1.Col1inner join TabB b2 on a.Col2=b2.Col1 |
Hash匹配还可以根据需要生成的Hash表的大小细分,分为In-Memory,grace以及recursive 这三种,它们对于内存的要求逐步提高。
Hash匹配的优点:只需要扫描两次表,IO占用相对较少。
Hash匹配的缺点:构建Hash表,比较消耗CPU资源。
嵌套循环
常见适用场景:一个表数据量大,一个表数据量小,且关联键有索引。当只有一个表的关联键有索引时,将具有索引的表做为内层表可以获取最佳的IO性能。不局限于等值条件。
合并联接
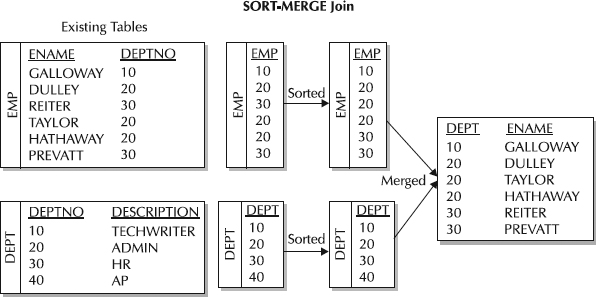
常见适用场景,关联键上需要有已经经过排序后的索引做为数据源,一般情况下需要有一个关联键是唯一索引。当两个关联表数据量相当时且具有排序后的索引那么比较适合用合并联接,不局限于等值条件。
总结:
sql查询机制非常复杂,受各种因素的影响,很难有统一的标准去衡量一条SQL语句的性能。而只有了解了它的一些基本原理后,才有可能不被一些看起来非常简单的问题难倒,也才有可能编写也适用于当前项目性能最佳的SQL来。
学习SQL关联查询的更多相关文章
- 通过一个小问题来学习SQL关联查询
原话题: 是关于一个left join的,没有技术难度,但不想清楚不一定能回答出正确答案来: TabA表有三个字段Id,Col1,Col2 且里面有一条数据1,1,2 TabB表有两个字段Id,Col ...
- (一)SQL关联查询的使用技巧 (各种 join)
---恢复内容开始--- (一)SQL关联查询的使用技巧 (各种 join) 这几天因为工作的时候,发现自己的sql语句基础不是很好,特意研究了一下,发现sql语句真的是博大精深,sql语句不仅是要查 ...
- 通过Spark SQL关联查询两个HDFS上的文件操作
order_created.txt 订单编号 订单创建时间 -- :: -- :: -- :: -- :: -- :: order_picked.txt 订单编号 订单提取时间 -- :: ...
- MyBatis 实践 -动态SQL/关联查询
MyBatis 实践 标签: Java与存储 动态SQL 动态SQL提供了对SQL语句的灵活操作,通过表达式进行判断,对SQL进行拼接/组装. if 对查询条件进行判断,如果输入参数不为空才进行查询条 ...
- sql关联查询—将一个表的查询结果作为新表进行查询操作
例题:# 各个部门中 最高工资中最低的那个部门的 最低工资是多少? 先考虑取得各个部门最高工资 SELECT MAX(salary) AS max_salary,e.`department_id` ...
- SQL关联查询
从2张或多张表中,取出有关联的数据 关联查询一共有几种情况: 内连接:INNER JOIN .CROSS JOIN (1)形式一 select 字段列表 from A表 inner join B表 o ...
- 转载:sql关联查询
inner join(等值连接)只返回两个表中联结字段相等的行 left join(左联接)返回包括左表中的所有记录和右表中联结字段相等的记录 right join(右联接)返回包括右表中的所有记录和 ...
- SQL关联查询中on与where
微信公众号:刺刺刺猬的优雅 前段时间,做一个查询,打算用left join查询存在于A表但不存在于B表记录,但怎么查都不对,原因是把所有filter全部放在了where语句中,因此回头看了资料,记录一 ...
- 玩school 学习sql server 查询的网站
http://www.w3school.com.cn/sql/sql_like.asp
随机推荐
- ASP.NET 5 (vNext)
ASP.NET 5 (vNext) 理解和入门 概述 ASP.NET 5 (又称为vNext) 是自ASP.NET产生15年以来一次革命性的更新, 我们可以从以下几点来理解其概貌和意义: ASP. ...
- 2014鞍山直播比赛H称号HDU5077(DFS修剪+通过计)
NAND Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others) Total Sub ...
- Swift 语言概览 -自己在Xcode6 动手写1
原文:Swift 语言概览 -自己在Xcode6 动手写1 Swift是什么? Swift是苹果于WWDC 2014发布的编程语言,这里引用The Swift Programming Language ...
- 【地图API】为何您的坐标不准?如何纠偏?
原文:[地图API]为何您的坐标不准?如何纠偏? 摘要:各种坐标体系之间如何转换?到底有哪些坐标体系?什么是火星坐标?为什么我的坐标,在地图上显示会有偏移?本文详细解答以上问题.最后给出坐标拾取工具. ...
- Linux基础正则表达式:grep,sed
先说明语系对正则表达式的影响 LANG=C:0,1,2,3,4...A,B,C,D...Z a b c d ... z LANG=zh_CN:0,1,2,3,4...a A b B c C ...
- JAVA异常处理、常用类、反射、集合
异常 异常:在Java中是指被一个方法抛出的对象. 分类:检查异常.运行时异常.错误 运行时异常(uncheckd):RuntimeException和其子类 检查异常(checkd/搜检异常):指E ...
- Android Studio怎样更改JDK和SDK的路径?
这个对于非常多刚转到Android Studio上的来说,确实是一个问题.可能你在设置里面找了非常久都没找到这个选项. 直接上图吧,按下图就能够找到设置的地儿了,然后直接设置到你SDK或者JDK的路径 ...
- .NET源代码的内部排序实现
使用JetBrains的DotPeek工具能够方便地查看.net的部分源代码.于是看了一下.NET的内部是怎样实现排序的算法. 在System.Collections.Generic 命名空间下能够看 ...
- 快速构建Windows 8风格应用1-开发工具安装及模拟器使用
原文:快速构建Windows 8风格应用1-开发工具安装及模拟器使用 本篇博文主要介绍的是开发Windows 8风格应用中常用的两个开发工具:Visual Studio 2012和Expression ...
- 经常使用Javascript CDN 对照
[前言] 请参阅某种网上文章: http://c7sky.com/javascript-libraries-cdn.html 本文加入的各个cdn对一些库的更新情况.以及响应时间. [更新] 发表文章 ...